Hadoop完全分布式的配置
选取机器sam01作为主节点,并进行分布式文件的配置
1.进入Hadoop配置文件路径/usr/local/hadoop/etc/hadoop(这里我把Hadoop安装在/usr/local目录下)
2.配置core-site.xml文件
<configuration>
<!-- hdfs的地址名称:schame,ip,port-->
<!-- 在Hadoop1.x的版本中,默认使用的端口是9000。在Hadoop2.x的版本中,默认使>用端口是8020 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://sam01:8020</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
3.配置hdfs-site.xml文件
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sam02:50090</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>sam01:50070</value>
</property>
</configuration>
4.配置mapred-site.xml
这里初始为mapred-site.xml.template文件,需要复制为mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml
<configuration>
<!-- namenode守护进程管理的元数据文件fsimage存储的位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<!-- 确定DFS数据节点应该将其块存储在本地文件系统的何处-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
</property>
<!-- 块的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 块的大小(128M),下面的单位是字节-->
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<!-- secondarynamenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sam02:50090</value>
</property>
<!-- namenode守护进程的http地址:主机名和端口号。参考守护进程布局-->
<property>
<name>dfs.namenode.http-address</name>
<value>sam01:50070</value>
</property>
</configuration>
6.配置yarn-site.xml
<configuration>
<!-- 指定yarn的shuffle技术-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager的主机名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>sam01</value>
</property>
<!--下面的可选-->
<!--指定shuffle对应的类 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!--配置resourcemanager的内部通讯地址-->
<property>
<name>yarn.resourcemanager.address</name>
<value>sam01:8032</value>
</property>
<!--配置resourcemanager的scheduler的内部通讯地址-->
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>sam01:8030</value>
</property>
<!--配置resoucemanager的资源调度的内部通讯地址-->
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>sam01:8031</value>
</property>
<!--配置resourcemanager的管理员的内部通讯地址-->
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>sam01:8033</value>
</property>
<!--配置resourcemanager的web ui 的监控页面-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>sam01:8088</value>
</property>
</configuration>
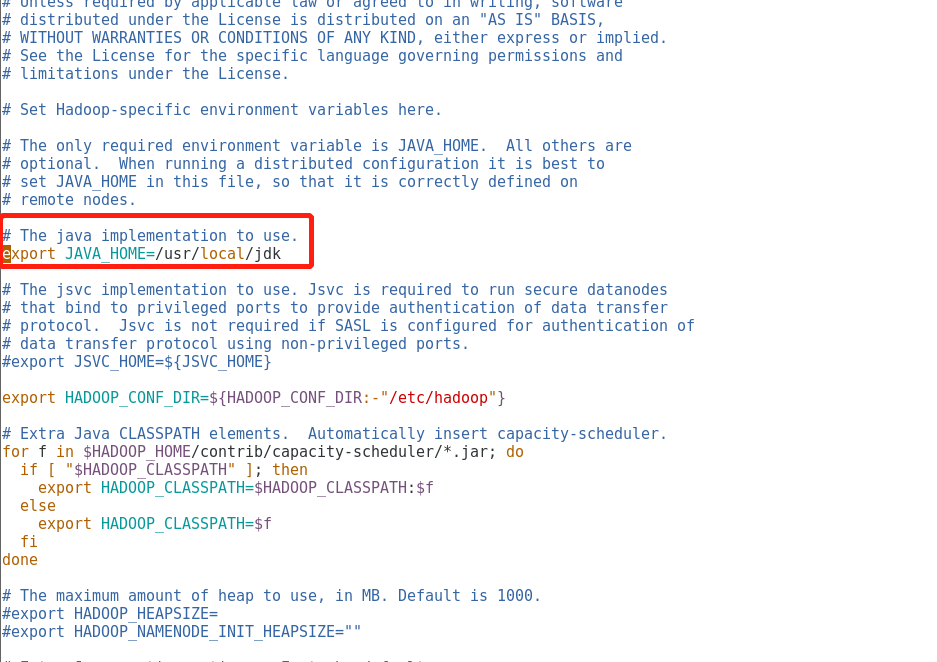
7.配置hadoop-env.sh文件
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk
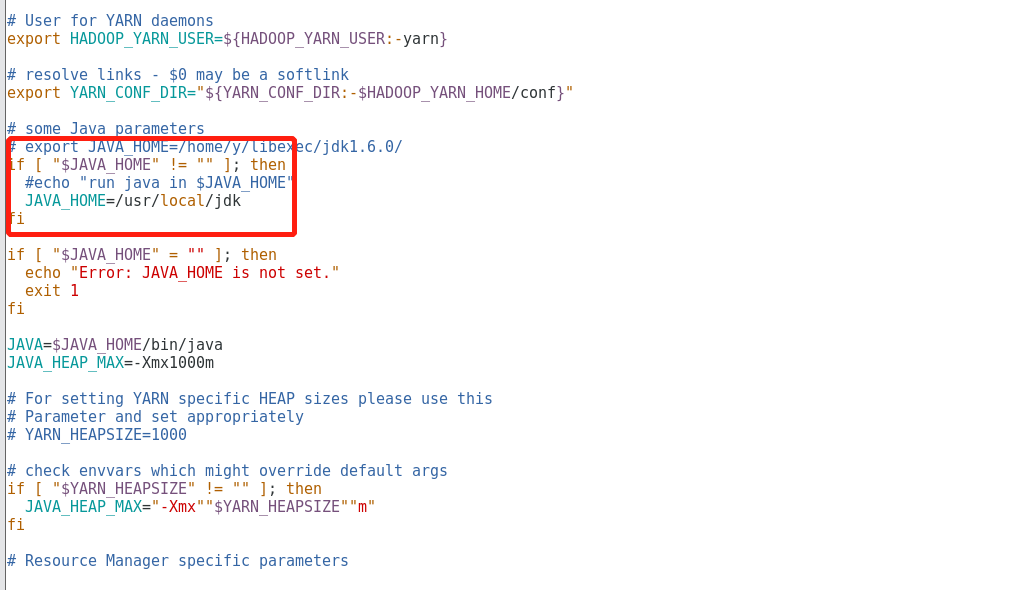
8.配置yarn-env.sh文件
#echo "run java in $JAVA_HOME"
JAVA_HOME=/usr/local/jdk
9.配置slaves文件,此文件用于指定datanode守护进程所在的机器节点主机名
sam01
sam02
sam03
10.同步Hadoop配置文件到其余的节点
cd /usr/local
scp -r hadoop/ sam02:$PWD
scp -r hadoop/ sam03:$PWD
Hadoop完全分布式的配置的更多相关文章
- Hadoop完全分布式安装配置完整过程
一. 硬件.软件准备 1. 硬件设备 为了方便学习Hadoop,我采用了云服务器来配置Hadoop集群.集群使用三个节点,一个阿里云节点.一个腾讯云节点.一个华为云节点,其中阿里云和腾讯云都是通过使用 ...
- Hadoop 伪分布式安装配置
- 基于Centos搭建 Hadoop 伪分布式环境
软硬件环境: CentOS 7.2 64 位, OpenJDK- 1.8,Hadoop- 2.7 关于本教程的说明 云实验室云主机自动使用 root 账户登录系统,因此本教程中所有的操作都是以 roo ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- hadoop的安装和配置(三)完全分布式模式
博主会用三篇文章为大家详细说明hadoop的三种模式: 本地模式 伪分布模式 完全分布模式 完全分布式模式: 前面已经说了本地模式和伪分布模式,这两种在hadoop的应用中并不用于实际,因为几乎没人会 ...
- 在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例
在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例 ...
- Hadoop伪分布式配置
一步一步来: 安装VMWARE简单,安装CentOS也简单 但是,碰到了一个问题:安装的虚拟机没有图形化界面 最后,我选择了CentOS-7-x86_64-DVD-1503-01.iso镜像 配置用户 ...
- Data - Hadoop伪分布式配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- 使用docker搭建hadoop环境,并配置伪分布式模式
docker 1.下载docker镜像 docker pull registry.cn-hangzhou.aliyuncs.com/kaibb/hadoop:latest 注:此镜像为阿里云个人上传镜 ...
随机推荐
- JMeter_调试取样器(Debug Sampler)
大家在调试 JMeter 脚本时有没有如下几种需求: 我想知道参数化的变量取值是否正确! 我想知道正则表达式提取器(或json提取器)提取的值是否正确! 我想知道 JMeter 属性! 调试时服务器返 ...
- 学习Layui笔记-父窗口获取子窗口的radio
最近学习layui,使用radio做单项选择的时候,发现layui无论怎么取值,都是默认取到第一个radio的值. 百度下找解决方法. html页面部分 <div class="lay ...
- 基于Bert的恶意软件多分类
基于Bert从Windows API序列做恶意软件的多分类 目录 基于Bert从Windows API序列做恶意软件的多分类 0x00 数据集 0x01 BERT BERT的模型加载 从文本到ids ...
- python极简教程06:生成式和装饰器
测试奇谭,BUG不见. 这一场,主讲python的生成式和装饰器. 目的:掌握四种生成式(列表.生成器.集合.字典),装饰器的原理和使用. 生成式 01 什么是生成式? 能够用一行代码,快速高效的生成 ...
- css3中transition属性详解
css3中通过transition属性可以实现一些简单的动画过渡效果~ 1.语法 transition: property duration timing-function delay; transi ...
- Linux 安装 MySQL 8.0.26 超详细图文步骤
1.MySQL 8.0.26 下载 官方网站下载 MySQL 8.0.26 安装包,下载地址: https://downloads.mysql.com/archives/community/ 需要注意 ...
- C# 给PDF文档设置过期时间
我们可以给一些重要文档或者临时文件设置过期时间和过期信息提示来提醒读者或管理者文档的时效性,并及时对文档进行调整.更新等.下面,分享通过C#程序代码来给PDF文档设置过期时间的方法. 引入dll程序集 ...
- jsp文本框输入限制问题
1.jsp文本窗口实现控制输入格式 <input onkeyup = "value=value.replace(/[\W]/g,'')" onbeforepaste=&quo ...
- 『德不孤』Pytest框架 — 3、Pytest的基础说明
目录 1.Pytest参数介绍 2.Pytest框架用例命名规则 3.Pytest Exit Code说明 4.pytest.ini全局配置文件 5.Pytest执行测试用例的顺序 1.Pytest参 ...
- vue学习4-class和sytle绑定
#### Class绑定: 1. 通过数组的方式来实现: 2. 通过对象的方式来实现: 通过对象: 通过数组,通过数组是把多个style样式对象添加进去: