Kaldi中的L2正则化
steps/nnet3/train_dnn.py
--l2-regularize-factor
影响模型参数的l2正则化强度的因子。要进行l2正则化,主要方法是在配置文件中使用'l2-regularize'进行配置。l2正则化因子将乘以组件中的l2正则化值,并且可用于通过模型平均化以校正与并行化带来的影响。
(float,默认值= 1)
src/nnet3/nnet-utils.cc:2030
void ApplyL2Regularization(const Nnet &nnet, BaseFloat l2_regularize_scale, Nnet *delta_nnet) { /*...*/
//nnet是更新前的神经网络
const Component *src_component_in = nnet.GetComponent(c);
//delta_nnet是进行更新后的神经网络
UpdatableComponent *dest_component =
dynamic_cast<UpdatableComponent*>(delta_nnet->
GetComponent(c));
//delta_nnet->c -= 2.0 * l2_regularize_scale * alpha * eta * nnet.c
// alpha为L2正则化常数
// eta为学习率
// nnet.c为该nnet的component(应该是权重)
// l2_regularize来自于L2Regularization(),该函数返回UpdatableComponent中的L2正则化常量(通常由配置文件设定)。
// 根据steps/libs/nnet3/xconfig/basic_layers.py:471
// 可以xconfig中指定l2-regularize(默认为0.0)
// 一般通过ApplyL2Regularization()而非组件层的代码读取该常量。ApplyL2Regularization(),声明于nnet-utils.h(训练工作流的一部分)。
BaseFloat scale = -2.0 * l2_regularize_scale * lrate * l2_regularize;
// nnet3/nnet-simple-component.cc:1027
// linear_params_.AddMat(alpha, other->linear_params_);
// bias_params_.AddVec(alpha, other->bias_params_);
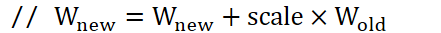

/*...*/}
//输出的统计数值
CuVector<double> value_sum_;
//非线性(神经元)的微分的统计数值(只适用于以向量元素为单位的非线性,不适用于Softmax)
CuVector<double> deriv_sum_;
//objective derivative function sum square
//目标函数微分的平方和,用于诊断
CuVector<double> oderiv_sumsq_;
//oderiv_sumsq_中stats数量
double oderiv_count_;
对于神经网络中的每个可更新组件c,假设它在组件中设定了l2正则化常量alpha(请参阅UpdatableComponent::L2Regularization())和学习率eta,那么此函数为(伪代码):

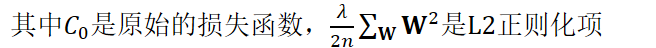
对求W偏导:

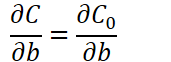
可以发现L2正则化项对b的更新没有影响,但是对于w的更新有影响:
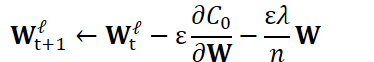

delta_nnet-> c -= 2.0 * l2_regularize_scale * alpha * eta * nnet.c
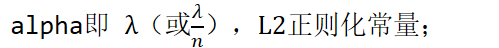
nnet.c即w;
eta为学习率
因子-1.0(-=,减等于)是为了最大化正则化项;

因子2.0来自参数平方的导数。该函数使用了"l2_regularize_scale"因子,请参阅下面的说明。
注意:由于与自然梯度的相互作用,Kaldi的L2正则化是普通方法的近似。问题在于普通梯度乘以经过近似化、平滑化、比例缩放的Fisher矩阵的逆,但是l2梯度不是。这意味着我们正在优化的不是常规的"目标函数 + L2正则化项"这种形式,我们可以将其视为"常规目标函数 + L2正则化项
× Fisher矩阵"
,前提是
参数变化量不受到Fisher矩阵缩放的影响,所以这不会影响L2的整体强度,只会影响是方向(direction-wise)权重。实际上,在大的Fisher矩阵的变换方向上,相对于梯度,L2项的贡献将更大。这可能并不理想,但如果没有实验就很难判断。无论如何,L2的影响足够小,并且Fisher矩阵根据identity进行了充分的平滑,我怀疑这会产生很大的差别。
要为nnet3设定L2正则化,可以调用nnet3/xconfig_to_configs.py:

Kaldi中的L2正则化的更多相关文章
- 从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化
从有约束条件下的凸优化角度思考神经网络训练过程中的L2正则化 神经网络在训练过程中,为应对过拟合问题,可以采用正则化方法(regularization),一种常用的正则化方法是L2正则化. 神经网络中 ...
- TensorFlow中的L2正则化函数:tf.nn.l2_loss()与tf.contrib.layers.l2_regularizerd()的用法与异同
tf.nn.l2_loss()与tf.contrib.layers.l2_regularizerd()都是TensorFlow中的L2正则化函数,tf.contrib.layers.l2_regula ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- tensorflow中添加L2正则化损失
方法有几种,总结一下方便后面使用. 1. tensorflow自动维护一个tf.GraphKeys.WEIGHTS集合,手动在集合里面添加(tf.add_to_collection())想要进行正则化 ...
- TensorFlow L2正则化
TensorFlow L2正则化 L2正则化在机器学习和深度学习非常常用,在TensorFlow中使用L2正则化非常方便,仅需将下面的运算结果加到损失函数后面即可 reg = tf.contrib.l ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- tensorflow 中的L1和L2正则化
import tensorflow as tf weights = tf.constant([[1.0, -2.0],[-3.0 , 4.0]]) >>> sess.run(tf.c ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
随机推荐
- 用javascript来实现前端简单路由
WEB开发中路由概念并不陌生,我们接触到的有前端路由和后端路由.后端路由在很多框架中是一个重要的模块,如Thinkphp,Wordpress中都应用了路由功能,它能够让请求的url地址变得更简洁.同样 ...
- Methods for follow-up research of exome analysis:外显子后续分析研究思路总结
外显子后续分析研究思路一般有以下几种(Methods for follow-up research of exome analysis): 1.对突变频率.突变类型.突变方式进行统计分析 Mutati ...
- postman 介绍
- _future_用法总结
写这篇文章主要是参考以下两篇博客 https://blog.csdn.net/stan_pcf/article/details/60465665 https://www.liaoxuefeng.com ...
- halcon图像处理的基本思路
原图素材,1.jpg 过程图: 结果图: 代码及注意事项: read_image (Image, 'C:/Users/Jv/Desktop/1.jpg') rgb1_to_gray (Image, G ...
- springcloud使用zookeeper作为config的配置中心
https://blog.csdn.net/CSDN_Stephen/article/details/78856323 仓库更新了,本地如何更新: 使用configserver作为配置中心: http ...
- Luogu P3521 [POI2011]ROT-Tree Rotations
题目链接 \(Click\) \(Here\) 线段树合并,没想到学起来意外的很简单,一般合并权值线段树. 建树方法和主席树一致,即动态开点.合并方法类似于\(FHQ\)的合并,就是把两棵树的信息整合 ...
- lucene的CRUD操作Document(四)
IndexWriter writer = new IndexWriter(Directory, IndexWriterConfig); 增加文档:writer.addDocument(); 读取文档: ...
- day12-(jsp&el&jstl)
回顾: jsp: cookie: 浏览器端会话技术 由服务器产生,生成key=value形式,通过响应头(set-cookie)返回给浏览器,保存在浏览器端 下次访问的时候根据一定的规则携带cooki ...
- java中用jdom创建xml文档/将数据写入XML中
import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; i ...