scrapy几种反反爬策略
一.浏览器代理
1.直接处理:
1.1在setting中配置浏览器的各类代理:
user_agent_list=[ "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
......
]
1.2然后在各个请求中调用:
import random
from setting import user_agent_list
headers=
{
"Host":"",
......
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
}
def parse(self,response):
...... user_agent=random.choice(user_agent_list)
self.header["User-Agent"]=user_agent
yeild scrapy.Request(request_url,headers=self.headers,callback=...)
1.3缺点:
使用麻烦,各个请求都要调用,而且耦合性高。
2.使用downloader-middlewares:
2.1使用downloader-middleware(setting中默认是注销了的):

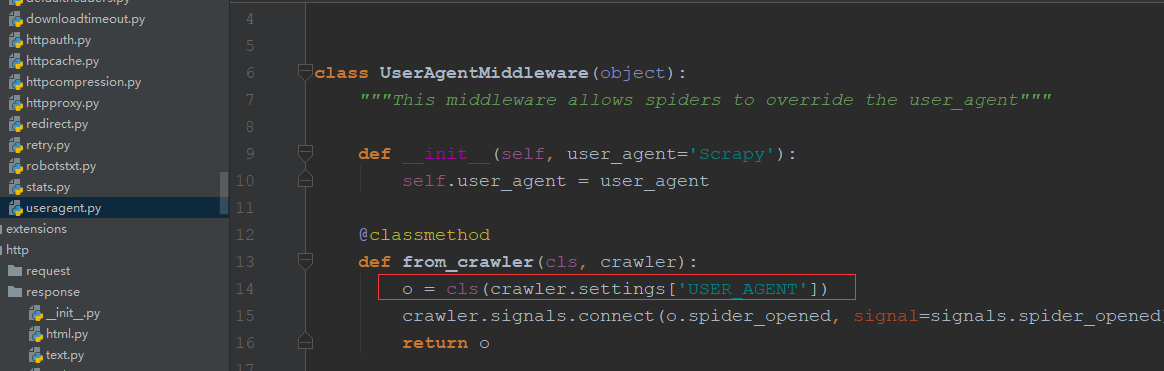
2.2useragent源码如下(默认的User-Agent为Scraoy,可以直接在setting中配置USER_AGENT="......"就会替换Scrapy如红框中):
2.3自定义useragentmiddleware(需要在setting中将默认的middleware致为none或数字比自定以的小):

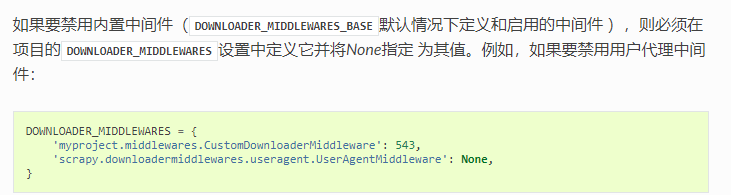
官网简介
2.3.1直接重写函数:
#这样能实现,写一个random()函数选择代理,但维护user_agent_list很麻烦,需要重启spider
class RandomUserAgentMiddleware(object):
#随机选择User-Agent
def __init__(self,crawler):
super(RandomUserAgentMiddleware,self).__init__()
self.user_agent_list=crawler.setting.get("user_agent_list","")
@classmethod
def from_crawler(cls,crawler):
return cls(crawler)
def process_request(self,request,spider):
request.headers.setdefault('User-Agent',random())
2.3.2fake_useragent的使用:
安装:pip install fake_useragent
使用:
from fake_useragent import UserAgent
......
class RandomUserAgentMiddleware(object):
#随机选择User-Agent,所有浏览器
def __init__(self,crawler):
super(RandomUserAgentMiddleware,self).__init__()
self.ua = UserAgent()
@classmethod
def from_crawler(cls,crawler):
return cls(crawler)
def process_request(self,request,spider):
request.headers.setdefault('User-Agent',self.ua.random)
class RandomUserAgentMiddleware(object):
# 随机选择User-Agent
def __init__(self, crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
#RANDOM_UA_TYPE为setting中配置的浏览器类型
self.ua_type = crawler.settings.get("RANDOM_UA_TYPE", "random") @classmethod
def from_crawler(cls, crawler):
return cls(crawler) def process_request(self, request, spider):
#函数里定义函数(动态语言闭包特性),获取是哪种浏览器类型的随机
def get_ua():
#相当于取self.ua.ua_type
return getattr(self.ua, self.ua_type) request.headers.setdefault('User-Agent', get_ua())
2.3.3自定义中间件配置:

二.IP代理设置
1.重启路由器:
IP在绝大多数情况会变,用本机IP比用代理IP爬取速度更快。
2.代理IP原理:
1.本机向代理服务器发起请求访问某个网站——>
2.代理服务器访问请求的网站——>
3.数据返回给代理服务器——>
4.代理服务器把数据返回给本机。
3.免费ip网站获取ip(西刺网【设置一定间隔】):
# _*_ encoding:utf-8 _*_
__author__ = 'LYQ'
__date__ = '2018/10/6 17:16'
import requests
from scrapy.selector import Selector
import MySQLdb conn = MySQLdb.Connect(host="localhost", user="root", passwd="", db="xici", charset="utf8")
cursor = conn.cursor() def crawl_ips():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36"
}
for i in range(1, 3460):
re = requests.get("http://www.xicidaili.com/nn/{0}".format(i), headers=headers)
selector = Selector(text=re.text)
ip_lists = selector.css('#ip_list tr')
get_ips = []
for ip_list in ip_lists[1:]:
speed = ip_list.css(".bar::attr(title)").extract_first()
if speed:
speed = float(speed.split('秒')[0])
texts = ip_list.css("td::text").extract()
ip = texts[0]
port = texts[1]
proxy_type = ip_list.xpath("td[6]/text()").extract_first()
get_ips.append((ip, port, proxy_type, speed))
for ip_info in get_ips:
cursor.execute(
"INSERT REPLACE INTO proxy_ips(ip,port,type,speed) VALUES('{0}','{1}','{2}','{3}')".format(ip_info[0],
ip_info[1],
ip_info[2],
ip_info[3])
)
conn.commit() class Get_ip(object):
def judge_ip(self, ip, port):
# 判断ip是否可用
http_url = 'https://www.baidu.com'
proxy_url = 'https://{0}:{1}'.format(ip, port)
try:
proxy_dict = {
'http': proxy_url
}
response = requests.get(http_url, proxies=proxy_dict)
except:
print("该ip:{0}不可用".format(ip))
self.delete_ip(ip)
return False
else:
code = response.status_code
if code >= 200 and code < 300:
print("ip:{0}有效".format(ip))
return True
else:
print("该ip:{0}不可用".format(ip))
self.delete_ip(ip)
return False def delete_ip(self, ip):
delete_sql = """
delete from proxy_ips where ip='{0}'
""".format(ip)
cursor.execute(delete_sql)
conn.commit()
return True def get_random_ip(self):
random_sql = """
SELECT ip,port from proxy_ips ORDER BY RAND() LIMIT 1
"""
result = cursor.execute(random_sql)
for ip_info in cursor.fetchall():
ip = ip_info[0]
port = ip_info[1]
judge_re=self.judge_ip(ip, port)
if judge_re:
return 'http://{0}:{1}'.format(ip,port)
else:
return self.get_random_ip() if __name__=='__main__':
# crawl_ips()
get_ip = Get_ip()
a = get_ip.get_random_ip()
4.ip代理中间件书写:
class RandomProxyMiddleware(object):
#动态代理ip的使用
def process_request(self, request, spider):
get_ip=Get_ip()
request.meta['proxy']=get_ip.get_random_ip()
5.开源库的使用(scrapy_proxy处理ip):
scrapy-crawla,haipproxy,scrapy-proxies等,可以在github上查看
6.Tor(洋葱网络的使用),可以隐藏ip(需要vpn)
三.验证码的识别
1.编码实现(tesseract-ocr):
需要数据训练,识别率低。
2.在线打码(识别率在90%以上):
2.1云打码平台的使用:
注册之后(开发者和用户模式),可以下载对应的调用实列查看
软件添加

验证码类型
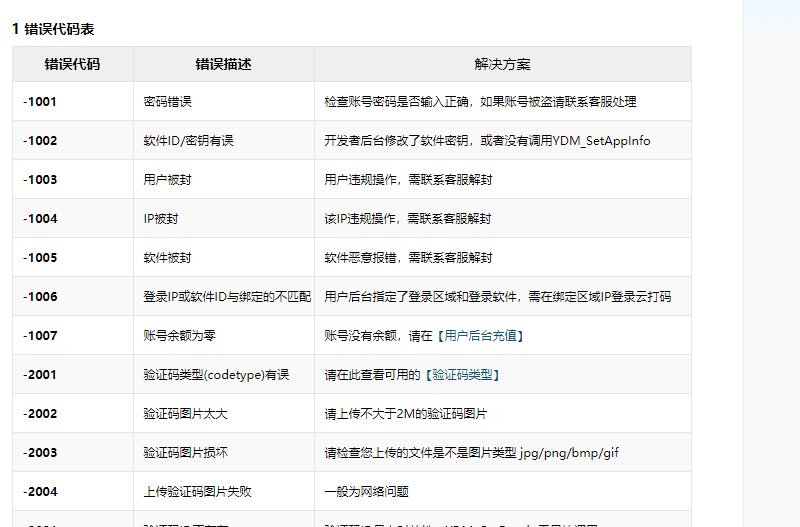
错误状态码,可以在官网查看所有
2.2识别接口:
import json
import requests class YDMHttp(object):
apiurl = 'http://api.yundama.com/api.php'
username = ''
password = ''
appid = ''
appkey = '' def __init__(self, username, password, appid, appkey):
self.username = username
self.password = password
self.appid = str(appid)
self.appkey = appkey def balance(self):
data = {'method': 'balance', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey}
response_data = requests.post(self.apiurl, data=data)
ret_data = json.loads(response_data.text)
if ret_data["ret"] == 0:
print ("获取剩余积分", ret_data["balance"])
return ret_data["balance"]
else:
return None def login(self):
data = {'method': 'login', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey}
response_data = requests.post(self.apiurl, data=data)
ret_data = json.loads(response_data.text)
if ret_data["ret"] == 0:
print ("登录成功", ret_data["uid"])
return ret_data["uid"]
else:
return None def decode(self, filename, codetype, timeout):
data = {'method': 'upload', 'username': self.username, 'password': self.password, 'appid': self.appid, 'appkey': self.appkey, 'codetype': str(codetype), 'timeout': str(timeout)}
files = {'file': open(filename, 'rb')}
response_data = requests.post(self.apiurl, files=files, data=data)
ret_data = json.loads(response_data.text)
if ret_data["ret"] == 0:
print ("识别成功", ret_data["text"])
return ret_data["text"]
else:
return None if __name__ == "__main__":
# 用户名
username = ''
# 密码
password = ''
# 软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得!
appid = 5921
# 软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得!
appkey = '4b29b3e33db637975d5e51bdf9f2c03b'
# 图片文件
filename = 'getimage.jpg'
# 验证码类型,# 例:1004表示4位字母数字,不同类型收费不同。请准确填写,否则影响识别率。在此查询所有类型 http://www.yundama.com/price.html
codetype = 1004
# 超时时间,秒
timeout = 60
# 检查
if (username == 'username'):
print ('请设置好相关参数再测试')
else:
# 初始化
yundama = YDMHttp(username, password, appid, appkey) # 登陆云打码
uid = yundama.login()
print ('uid: %s' % uid) # 查询余额
balance = yundama.balance()
print ('balance: %s' % balance) # 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果
text = yundama.decode(filename, codetype, timeout)

结果如下
3.人工打码:
识别率最高,费用高。
四.配置使爬虫被识别率降低
1.cookie的禁用:
1.1setting.py中(不需登录的网站):
COOKIES_ENABLED = False
1.2自动限速(AutoThrottle)扩展:
主要配置(setting中):
AUTOTHROTTLE_ENABLED 默认: False 启用AutoThrottle扩展。
AUTOTHROTTLE_START_DELAY 默认: 5.0 初始下载延迟(单位:秒)。
AUTOTHROTTLE_MAX_DELAY 默认: 60.0 在高延迟情况下最大的下载延迟(单位秒)。
AUTOTHROTTLE_DEBUG 默认: False 起用AutoThrottle调试(debug)模式,展示每个接收到的response。 您可以通过此来查看限速参数是如何实时被调整的。
1.3不同的spider设置不同的setting:
在spider中设置(这里的属性会覆盖setting中的):
custom_setting={
"COOKIES_ENABLED":True,
......
}
scrapy几种反反爬策略的更多相关文章
- Scrapy中的反反爬、logging设置、Request参数及POST请求
常用的反反爬策略 通常防止爬虫被反主要有以下几策略: 动态设置User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息.) 禁用cookies(也就是不启用cookies midd ...
- python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题
python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题 一丶爬虫概述 通过编写程序'模拟浏览器'上网,然后通 ...
- scrapy反反爬虫策略和settings配置解析
反反爬虫相关机制 Some websites implement certain measures to prevent bots from crawling them, with varying d ...
- 抖音爬虫教程,python爬虫采集反爬策略
一.爬虫与反爬简介 爬虫就是我们利用某种程序代替人工批量读取.获取网站上的资料信息.而反爬则是跟爬虫的对立面,是竭尽全力阻止非人为的采集网站信息,二者相生相克,水火不容,到目前为止大部分的网站都还是可 ...
- 【Python必学】Python爬虫反爬策略你肯定不会吧?
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 正文 Python爬虫反爬策略三部曲,拥有这三步曲就可以在爬虫界立足了: ...
- Python爬虫实战——反爬策略之模拟登录【CSDN】
在<Python爬虫实战-- Request对象之header伪装策略>中,我们就已经讲到:=="在header当中,我们经常会添加两个参数--cookie 和 User-Age ...
- scrapy反反爬虫
反反爬虫相关机制 Some websites implement certain measures to prevent bots from crawling them, with varying d ...
- 谈谈HTTPS安全认证,抓包与反抓包策略
文章原创于公众号:程序猿周先森.本平台不定时更新,喜欢我的文章,欢迎关注我的微信公众号. 协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信 ...
- python做反被爬保护的方法
python做反被爬保护的方法 网络爬虫,是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.但是当网络爬虫被滥用后,互联网上就出现太多同质的东西,原创得不到保护.于是,很 ...
- 爬取豆瓣电影储存到数据库MONGDB中以及反反爬虫
1.代码如下: doubanmoive.py # -*- coding: utf-8 -*- import scrapy from douban.items import DoubanItem cla ...
随机推荐
- 【转】iOS 音频-AVAudioSession
1. AVAudioSession 概述 最近一年一直在做IPC Camera的iOS客户端开发.和音频打交道,必须要弄清楚 AVAudioSession. 先看下苹果的官方图: Audio Se ...
- Visual Studio 2013 编译 64 位 Python 的 C 扩展 (使用 PyObject 包装)
对于 32 位 Python 的 C 扩展,以前用过 mingW32 编译, 但是 mingW32 不支持 64 位 Python 的 C 扩展编译,详情可见 stackoverflow,这位前辈的大 ...
- Oracle 迁移 序列
---删除序列select 'drop sequence ' || sequence_owner || '.' || SEQUENCE_NAME || ';'from dba_sequenceswhe ...
- 【转】从零开始玩转logback
概述 LogBack是一个日志框架,它与Log4j可以说是同出一源,都出自Ceki Gülcü之手.(log4j的原型是早前由Ceki Gülcü贡献给Apache基金会的)下载地址:http://l ...
- ASCII,unicode, utf8 ,big5 ,gb2312,gbk,gb18030等几种常用编码区别(转载)
原文出处:http://www.blogjava.net/xcp/archive/2009/10/29/coding2.html 最近老为编码问题而烦燥,下定决心一定要将其弄明白!本文主要总结网上一些 ...
- 首页技术支持常见问题宽带外网IP显示为10、100、172开头,没有公网IP,如何解决?
1.表现形式: 路由器拨号获得的公网IP变成了一个以100开头的IP(或者是10.172开头),而打开ip138.com查询却又是另外一个IP,将100开头的这个IP到百度去查询下则显示所在区域为美国 ...
- Generative Adversarial Nets[AAE]
本文来自<Adversarial Autoencoders>,时间线为2015年11月.是大神Goodfellow的作品.本文还有些部分未能理解完全,不过代码在AAE_LabelInfo, ...
- 10分钟开发 GPS 应用,了解一下
1 前言 在导师公司实习了半个月,参加的是尾气遥测项目,我的任务是开发GPS 的相关事情,从零到有的开发出了 GPS 的 Winform 应用,在这里记录一下开发过程和简要的描述一下将 GPS 数据提 ...
- SQLite 实现删除表中前一天的数据
注意点1 要注意SQLite datatime()函数为何获取不到系统本地时间?这个问题,坑死我了. 解决方法详见这篇文章:SQLite datatime()函数为何获取不到系统本地时间? 注意点2: ...
- 深入理解Redis高可用方案-Sentinel
Redis Sentinel是Redis的高可用方案.是Redis 2.8中正式引入的. 在之前的主从复制方案中,如果主节点出现问题,需要手动将一个从节点升级为主节点,然后将其它从节点指向新的主节点, ...