开源ETL工具之Kettle介绍
What
起源
Kettle是一个Java编写的ETL工具,主作者是Matt Casters,2003年就开始了这个项目,最新稳定版为7.1。
2005年12月,Kettle从2.1版本开始进入了开源领域,一直到4.1版本遵守LGPL协议,从4.2版本开始遵守Apache Licence 2.0协议。
Kettle在2006年初加入了开源的BI公司Pentaho, 正式命名为:Pentaho Data Integeration,简称“PDI”。
自2017年9月20日起,Pentaho已经被合并于日立集团下的新公司: Hitachi Vantara。
总之,Kettle可以简化数据仓库的创建,更新和维护,使用Kettle可以构建一套开源的ETL解决方案。
架构
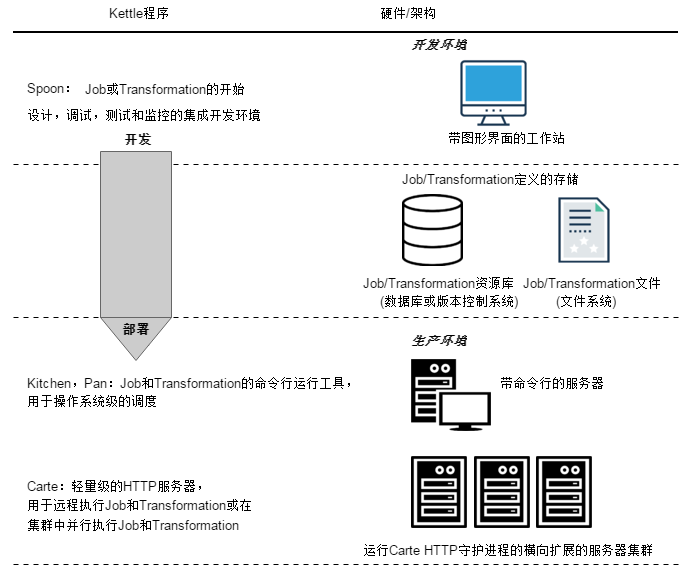
Kettle是一个组件化的集成系统,包括如下几个主要部分:
1.Spoon:图形化界面工具(GUI方式),Spoon允许你通过图形界面来设计Job和Transformation,可以保存为文件或者保存在数据库中。
也可以直接在Spoon图形化界面中运行Job和Transformation,
2.Pan:Transformation执行器(命令行方式),Pan用于在终端执行Transformation,没有图形界面。
3.Kitchen:Job执行器(命令行方式),Kitchen用于在终端执行Job,没有图形界面。
4.Carte:嵌入式Web服务,用于远程执行Job或Transformation,Kettle通过Carte建立集群。
5.Encr:Kettle用于字符串加密的命令行工具,如:对在Job或Transformation中定义的数据库连接参数进行加密。
基本概念
1.Transformation:定义对数据操作的容器,数据操作就是数据从输入到输出的一个过程,可以理解为比Job粒度更小一级的容器,我们将任务分解成Job,然后需要将Job分解成一个或多个Transformation,每个Transformation只完成一部分工作。
2.Step:是Transformation内部的最小单元,每一个Step完成一个特定的功能。
3.Job:负责将Transformation组织在一起进而完成某一工作,通常我们需要把一个大的任务分解成几个逻辑上隔离的Job,当这几个Job都完成了,也就说明这项任务完成了。
4.Job Entry:Job Entry是Job内部的执行单元,每一个Job Entry用于实现特定的功能,如:验证表是否存在,发送邮件等。可以通过Job来执行另一个Job或者Transformation,也就是说Transformation和Job都可以作为Job Entry。
5.Hop:用于在Transformation中连接Step,或者在Job中连接Job Entry,是一个数据流的图形化表示。
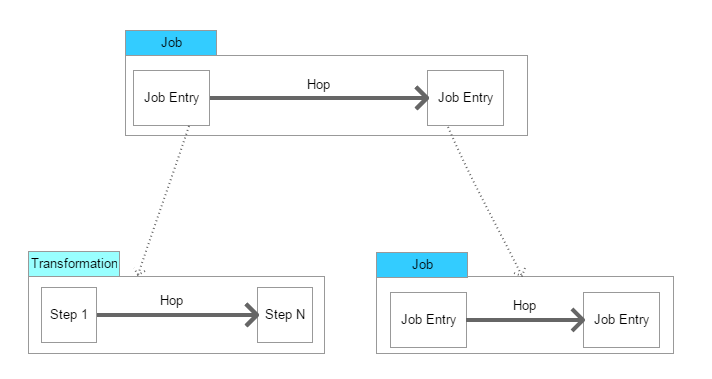
在Kettle中Job中的JobEntry是串行执行的,故Job中必须有一个Start的JobEntry;Transformation中的Step是并行执行的。
Why
组件对比
目前,ETL工具的典型代表有:
- 商业软件:Informatica PowerCenter,IBM InfoSphere DataStage,Oracle Data Integrator,Microsoft SQL Server Integration Services等
- 开源软件:Kettle,Talend,Apatar,Scriptella等
纯java编写,可以跨平台运行,绿色无需安装,数据抽取高效稳定。

相对于传统的商业软件,Kettle是一个易于使用的,低成本的解决方案。
Spoon是基于SWT(SWT使用了本地操作系统的组件库,性能更好,界面更符合本地操作系统的风格)开发的,支持多平台:
- Microsoft Windows: all platforms since Windows 95, including Vista
- Linux GTK: on i386 and x86_64 processors, works best on Gnome
- Apple's OSX: works both on PowerPC and Intel machines
- Solaris: using a Motif interface (GTK optional)
- AIX: using a Motif interface
- HP-UX: using a Motif interface (GTK optional)
- FreeBSD: preliminary support on i386, not yet on x86_64
Kettle使用场景
- Migrating data between applications or databases 在应用程序或数据库之间进行数据迁移
- Exporting data from databases to flat files 从数据库导出数据到文件
- Loading data massively into databases 导入大规模数据到数据库
- Data cleansing 数据清洗
- Integrating applications 集成应用程序
How
1.下载
https://community.hds.com/docs/DOC-1009855
也可以自己build,Maven项目架构。
mvn clean package -Drelease -Dmaven.test.skip=true
详见:https://github.com/pentaho/pentaho-kettle
2.安装
安装JRE1.7+(Pan需要在JRE1.7+下运行)。
Kettle免安装,在windows环境下,直接解压到指定目录即可。
3.实践
(1)在Spoon中设计Transformation和Job
运行Transformation和Job有2种方式。
方式一:直接在Spoon中运行。
方式二:在控制台终端运行(可以传递命令行参数),例如:
- 使用Pan运行Transformation:
Pan.bat /file C:\\Users\\chench9\\Desktop\\Tutorial\\hello.ktr - 使用Kitchen运行Job:
Kitchen.bat /file C:\\Users\\chench9\\Desktop\\Tutorial\\hello.kjb list /norep
(2)运行结果Step Metrics解读
- Read: the number of rows coming from previous Steps.
- Written: the number of rows leaving from this Step toward the next.
- Input: the number of rows read from a file or table.
- Output: the number of rows written to a file or table.
- Errors: errors in the execution. If there are errors, the whole row will become red.
(3)Kettle Java API
可以通过Java API的方式,将Kettle与第三方应用程序集成。
Kettle本身不提供对外的REST API,但是有一个Step为REST Client。
引用了Kettle所依赖的lib包之后,可以通过Java API方式在第三方应用中运行Job或Transformation
(4)集群部署
Kettle集群是一个Master/Slave架构。
Kettle集群是通过Carte服务组建的,集群模式主要用于远程执行Job。
本质上来讲Carte就是一个Web服务,其实就是使用了一个嵌入式Jetty容器。
初次调用Carte HTTP服务时用户名/密码: cluster/cluster。
- 启动master节点
启动master节点很简单,直接启动Carte服务即可,如:sh carte.sh localhost 8080
或者通过配置文件启动Master节点,首先编辑Master配置内容如下:
<slave_config>
<slaveserver>
<name>master1</name>
<hostname>moc.bankcomm.com</hostname>
<port>8080</port>
<username>cluster</username>
<password>cluster</password>
<master>Y</master>
</slaveserver>
</slave_config>
- 启动slave节点
在Slave节点上添加配置文件:slave_dyn_8080.xml,编辑内容如下:
<slave_config>
<masters>
<slaveserver>
<name>master1</name>
<hostname>moc.bankcomm.com</hostname>
<port>8080</port>
<username>cluster</username>
<password>cluster</password>
<master>Y</master>
</slaveserver>
</masters>
<report_to_masters>Y</report_to_masters>
<slaveserver>
<name>slave1-8080</name>
<hostname>kettle.slave1</hostname>
<port>8080</port>
<username>cluster</username>
<password>cluster</password>
<master>N</master>
</slaveserver>
</slave_config>
启动slave节点:Carte.bat D:\\pdi-ce-8.1-SNAPSHOT\\data-integration\\slave_dyn_8080.xml
(5)Kettle内置的Step
https://wiki.pentaho.org/display/EAI/List+of+Available+Pentaho+Data+Integration+Plug-Ins Kettle插件
(6) 总结
- 使用简单,学习曲线平缓
- 无需编写SQL就可以实现ETL
注意事项
- 运行Transformation或Job时,在Spoon中设置的环境变量在重启之后需要重新设置;如果是命令行参数,在终端运行时作为参数传递即可。
- 在使用Java API调用Job和Transformation时,除了需要引用kettle所依赖的lib包,在代码中初始化Kettle运行时环境之前,需要添加插件。参考:https://stackoverflow.com/questions/44866152/pentaho-kettle-cant-run-transformation-due-to-plugin-missing
- 在使用Java API运行Job和Transformation时,环境变量可以在2个地方设置:${user.home}/.kettle/kettle.properties,System.setProperty()
- 在Transformation中类型为command line argument的参数在集成Kettle API的应用中可以通过System.setProperty()设置并传递
kettle的坑
1.集群化部署
(1)不能在<slaveserver>节点中使用<network_interface>替代<hostname>,否则启动时报错:
java.lang.NullPointerException
at org.pentaho.di.core.Const.getIPAddress(Const.java:1775)
at org.pentaho.di.www.SlaveServerConfig.checkNetworkInterfaceSetting(SlaveServerConfig.java:378)
at org.pentaho.di.www.SlaveServerConfig.<init>(SlaveServerConfig.java:200)
at org.pentaho.di.www.Carte.parseAndRunCommand(Carte.java:202)
at org.pentaho.di.www.Carte.main(Carte.java:162)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.pentaho.commons.launcher.Launcher.main(Launcher.java:92)
(2)当集群中的slave节点失效之后,master不会更新slave列表。
虽然官方宣称每隔30秒就会检测slave的状态,但是实际部署时发现master并不会更新slave列表。
2.高可用支持
3.如何避坑
4.基于开源版我们可以用来做什么,如何实现定时调度,如何实现高可用
5.开源社区版本与企业版本主要区别是什么?
企业版Kettle不是独立的,而是集成在Pentaho Business Analytics商业套件中,作为ETL组件。在企业版中Kettle多一个Pentaho资源库。
【参考资料】
http://www.pentaho.com/ Pentaho主页
https://github.com/pentaho/pentaho-kettle Kettle源码
https://wiki.pentaho.com/display/EAI/ 文档(最新)
https://forums.pentaho.com/ Kettle论坛
《解决方案:使用PDI构建开源ETL解决方案 》
开源ETL工具之Kettle介绍的更多相关文章
- 开源ETL工具kettle系列之常见问题
开源ETL工具kettle系列之常见问题 摘要:本文主要介绍使用kettle设计一些ETL任务时一些常见问题,这些问题大部分都不在官方FAQ上,你可以在kettle的论坛上找到一些问题的答案 1. J ...
- ETL工具之Kettle的简单使用一(不同数据库之间的数据抽取-转换-加载)
ETL工具之Kettle将一个数据库中的数据提取到另外一个数据库中: 1.打开ETL文件夹,双击Spoon.bat启动Kettle 2.资源库选择,诺无则选择取消 3.选择关闭 4.新建一个转换 5. ...
- ETL工具之——kettle使用简介
ETL工具之——kettle使用简介 https://yq.aliyun.com/articles/157977?spm=5176.10695662.1996646101.searchclickres ...
- 开源ETL工具kettle--数据迁移
背景 因为项目的需求,须要将数据从Oracle迁移到MSSQL,不是简单的数据复制,而是表结构和字段名都不一样.甚至须要处理编码规范不一致的情况,例如以下图所看到的 watermark/2/text/ ...
- etl工具,kettle实现循环
Kettle是一款国外开源的ETL工具,纯Java编写,可以在Window.Linux.Unix上运行,绿色无需安装,数据抽取高效稳定. 业务模型: 在关系型数据库中有张很大的数据存储表,被设计成奇偶 ...
- etl工具,kettle实现了周期
Kettle这是国外的来源ETL工具,纯java写.能Window.Linux.Unix在执行.绿色无需安装,稳定高效的数据提取. 业务模型: 在关系型数据库中有张非常大的数据存储表,被设计成奇偶库存 ...
- 【转】开源性能测试工具 - Apache ab 介绍
版权声明:本文可以被转载,但是在未经本人许可前,不得用于任何商业用途或其他以盈利为目的的用途.本人保留对本文的一切权利.如需转载,请在转载是保留此版权声明,并保证本文的完整性.也请转贴者理解创作的辛劳 ...
- 【dataX】阿里开源ETL工具——dataX简单上手
一.概述 1.是什么? DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL.Oracle.SqlServer.Postgre.HDFS.Hive.ADS.HBase. ...
- python自学笔记之开源小工具:SanicDB介绍
SanicDB 是为 Python的异步 Web 框架 Sanic 方便操作MySQL而开发的工具,是对 aiomysql.Pool 的轻量级封装.Sanic 是异步IO的Web框架,同时用异步IO读 ...
随机推荐
- python学习日记(数据结构习题)
元素分类 有如下值li= [11,22,33,44,55,66,77,88,99,90],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中.即: {'k1' ...
- python学习日记(格式化输出,初始编码,运算符)
格式化输出 顾名思义,按照个人意愿定制想输出的格式. name = input('请输入姓名:') age = int(input('请输入年龄:')) job = input('请输入工作:') h ...
- 【BZOJ5285】[HNOI2018]寻宝游戏(神仙题)
[BZOJ5285][HNOI2018]寻宝游戏(神仙题) 题面 BZOJ 洛谷 题解 既然是二进制按位的运算,显然按位考虑. 发现这样一个关系,如果是\(or\)的话,只要\(or\ 1\),那么无 ...
- 【BZOJ3165】[HEOI2013]Segment(李超线段树)
[BZOJ3165][HEOI2013]Segment(李超线段树) 题面 BZOJ 洛谷 题解 似乎还是模板题QwQ #include<iostream> #include<cst ...
- 【博弈论】浅谈泛Nim游戏
Nim游戏在ACM中碰到了,就拎出来写写. 一般Nim游戏:有n堆石子,每堆石子有$a_i$个,每次可以取每堆石子中$[0,a_i-1]$,问先手是否有必胜策略. 泛Nim游戏:每堆石子有$a_i$个 ...
- 【docker】docker安装和使用
一.docker简介: docker是容器技术的一个代表,而容器技术是将程序打包和隔离的一种技术,其实它并不是一个新技术,之前在linux内核中早已存在,真正被大众所用所了解是因为docker的出现. ...
- Gym-100451B:Double Towers of Hanoi
题目链接 题目大意:把汉诺双塔按指定顺序排好的最少步数 我写这题写了很久...终于发现不dp不行 把一个双重塔从一根桩柱移动到另一根桩柱需要移动多少次? 最佳策略是移动一个双重 (n-1) 塔,接着移 ...
- springboot 后台运行
https://zhuanlan.zhihu.com/p/25102504?refer=dreawer 酱油一篇,整理一下关于Spring Boot后台运行的一些配置方式.在介绍后台运行配置之前,我们 ...
- TestNg 10. 多线程测试-xml文件实现
代码如下: package com.course.testng.multiThread; import org.testng.annotations.Test; public class MultiT ...
- 计算机基础:计算机网络-chapter6应用层
应用层为协议最顶部,为用户服务. 常见的服务:邮件,万维网,DNS等 DNS:使用UDP承载,部分使用TCP协议 作用 将域名映射为IP 域名格式:自己到上级域名的访问 DNS服务器提供域名的资源记录 ...