苏州市java岗位的薪资状况(2)
上一篇已经统计出了起薪最高的top 10:

接着玩,把top 10 中所有职位的详细信息爬取下来。某一职位的详情是这样:
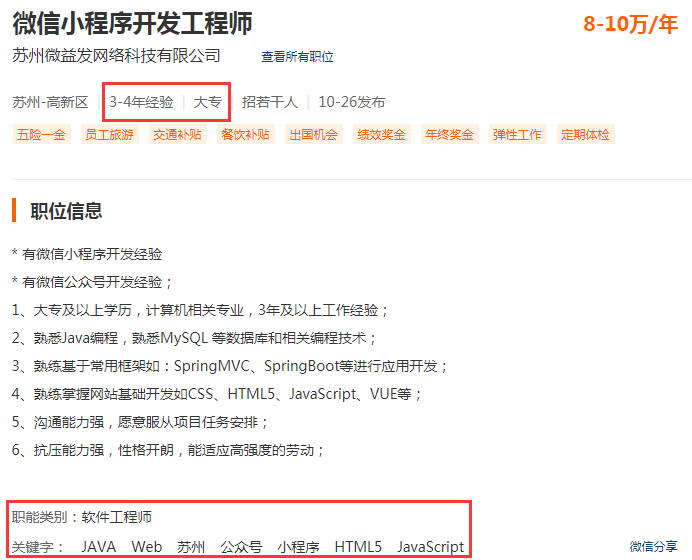
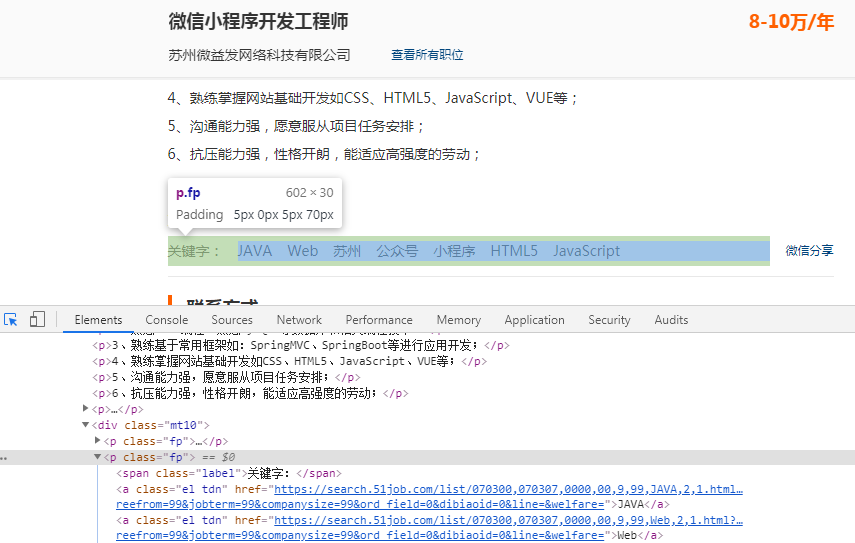
我们需要把工作经验、学历、职能、关键字爬取下来。
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
import csv
from itertools import chain
import threading def load_datas():
'''
从joblist.csv中装载数据
:return: 数据集 datas
'''
datas = []
with open('high10_url.csv', encoding='utf-8') as fp:
r = csv.reader(fp)
for row in r:
datas.append(row[0])
return datas def get_desc(url):
''' 爬取职位的详细信息,包括:经验, 学历, 职位, 技能关键字 '''
try:
html = urlopen(url)
except HTTPError as e:
print('Page was not found', e.filename)
return [] job_desc = [] # 职位详情
try:
exp, edu, position, keys = '', '', '', [] # 经验, 学历, 职位, 技能关键字
bsObj = BeautifulSoup(html.read())
contents = bsObj.find('p', {'class': 'msg ltype'}).contents
exp = contents[2].strip() # 经验
edu = contents[4].strip() # 学历
print(edu)
a_list = bsObj.findAll('a', {'class': 'el tdn'})
for i, a in enumerate(a_list):
if i == 0:
position = a.get_text() # 职位
else:
keys.append(a.get_text()) # 技能关键字
job_desc.append((exp, edu, position, keys))
except AttributeError as e:
print(e)
job_desc = []
return job_desc def crawl(urls):
'''
:param urls: 职位详情
'''
print('开始爬取数据...')
job_desc = [get_desc(url) for url in urls]
print('爬取结束')
return job_desc def save_data(all_jobs, f_name):
'''
将信息保存到目标文件
:param all_jobs: 二维列表,每个元素是一页的职位信息
'''
print('正在保存数据...')
with open(f_name, 'w', encoding='utf-8', newline='') as fp:
w = csv.writer(fp)
# 将二维列表转换成一维
t = list(chain(*all_jobs))
w.writerows(t)
print('保存结束,共{}条数据'.format(len(t))) urls = load_datas()
job_desc = crawl(urls)
print(job_desc)
save_data(job_desc, 'job_desc.csv')
high10_url.csv中已经预先存储了top 10的所有64个url。job_desc.csv中的结果如下:

学历列出现了问题,第5行显示的是“招1人”,实际上这个职位没有学历要求,把所有“招x人”的记录都改成“无要求”。
接下来可以按照经验、学历、职能分别统计:
import csv
import pandas as pd
import numpy as np def load_datas():
'''
从joblist.csv中装载数据
:return: 数据集 datas
'''
datas = []
with open('job_desc.csv', encoding='utf-8') as fp:
r = csv.reader(fp)
for row in r:
datas.append(row)
return datas def analysis(datas):
''' 数据分析 '''
df = pd.DataFrame({'exp': datas[:, 0],
'edu': datas[:, 1],
'position': datas[:, 2],
'keys': datas[:, 3]})
count(df, 'exp', '经验') # 按经验统计
count(df, 'edu', '学历') # 按学历统计
count(df, 'position', '职位') # 按职位统计 def count(df, idx, name):
''' 分组统计 '''
print(('按' + name + '分组').center(60, '-'))
c = df[idx].value_counts(sort=True)
print(c) if __name__ == '__main__':
# 读取并清洗数据
datas = np.array(load_datas())
analysis(datas)
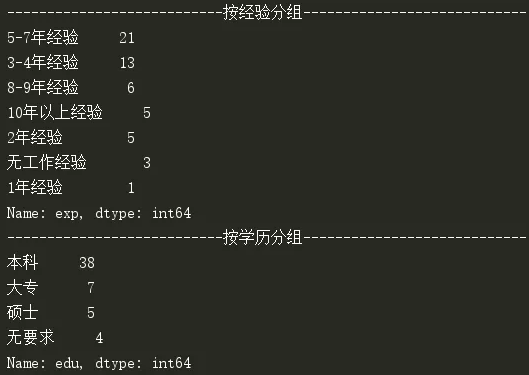
5~7年经验果然是最容易找到高薪职位的,而且用人单位大多要求本科学历。
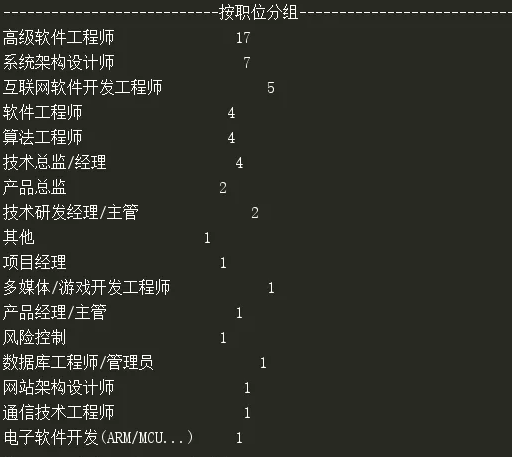
职能的统计比较杂乱,高级软件工程师和架构师的岗位较多,项目经理这类职位的薪水一般低于工程师,这也和预计的相同:
技能关键字看起来并不友好:

第一条记录很好地反应了技能要求,第二条就没什么用了,这是由于关键字信息是HR自行添加的,大多数HR都不太了解技术,因此也就出现了像第二条那样对本次分析没什么作用的关键字。
看来得求助于一些分词技术,从职位信息中抽取一些关键字。
下篇继续,看看哪些技能是抢手的。
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注公作者众号“我是8位的”

苏州市java岗位的薪资状况(2)的更多相关文章
- 苏州市java岗位的薪资状况(1)
8月份已经正式离职,这两个月主要在做新书校对工作.9月份陆续投了几份简历,参加了两次半面试,第一次是家做办公自动化的公司,开的薪水和招聘信息严重不符,感觉实在是在浪费时间,你说你给不了那么多为什还往上 ...
- 2014广州Java岗位面试汇总
本文记录了最近一些朋友提供的面试经历,真实数据,仅供广州求职的朋友参考.为行文方便,一律用主语”我“进行.部分词语可能造成读者不良反应,敬请留意. 1 广州沣首信息科技有限公司 公司所在区域相对较偏 ...
- Python基础学习笔记(一)python发展史与优缺点,岗位与薪资
相信有好多朋友们都是第一次了解python吧,可能大家也听过或接触过这个编程语言.那么到底什么是python呢?它在什么机缘巧合下诞生的呢?又为什么在短短十几年时间内就流行开来呢?就请大家带着疑问,让 ...
- Java岗位面试题分享:jvm+分布式+消息队列+协议(已拿offer)
个人近期面试情况 今年二月以来,我的面试除了一个用友的,基本其他都被毙了,可以说是非常残酷的.其中有很多自己觉得还面的不错的岗位,比如百度.跟谁学.好未来等公司.说实话,打击比较大. 情况基本上是从三 ...
- 野村证券伦敦分部面试 - Java岗位
第一轮 1. 笔试 30 mins 一共六道大题,前两题有4-5个小题. 第一道大题主要是考察Java Collections: a. LinkedList和ArrayList的区别 b. Set和L ...
- 掌握Python可以去哪些岗位?薪资如何?
一.人工智能 Python作为人工智能的黄金语言,选择人工智能作为就业方向是理所当然的,就业前景也还不错.人工智能工程师的招聘起薪一般在20K-35K,如果是初级工程师,起薪一般12K. 二.大数据 ...
- 使用java检测网络连接状况
windows中可以通过在cmd中使用ping命令来检测网络连接状况,如下: 网络连接正常时: 网络未连接时: 在java中可以通过调用ping命令来判断网络是否连接正常: package modul ...
- 成都传智播客java就业班(14.04.01班)就业快报(Java程序猿薪资一目了然)
这是成都传智播客Java就业班的就业情况,很多其它详情请见成都传智播客官网:http://cd.itcast.cn?140812ls 姓名 入职公司 入职薪资(¥) 方同学 安**软件成都有限公司(J ...
- 9大行为导致Java程序员薪资过低, 你有几个?
Java程序员薪水有高有低,有的人一个月可能拿30K.50K,有的人可能只有2K.3K.同样有五年工作经验的Java程序员,可能一个人每月拿20K,一个拿5K.是什么因素导致了这种差异?本文整理导致J ...
随机推荐
- HTML DOM的创建,删除及替换
创建HTML元素 document.appendChild() 将新元素作为父元素的最后一个子元素进行添加 如需向HTML DOM添加新元素,首先必须创建该元素,然后把它追加到已有的元素上 var n ...
- Orcle如何获取当前时间
Oracle获取当月所有日期: SELECT TRUNC(SYSDATE, 'MM') + ROWNUM - 1 FROM DUAL CONNECT BYROWNUM <= TO_NUMBER( ...
- Spring Boot Quartz 分布式集群任务调度实现
Spring Boot Quartz 主要内容 Spring Scheduler 框架 Quartz 框架,功能强大,配置灵活 Quartz 集群 mysql 持久化定时任务脚本(tables_mys ...
- idea使用maven中的tomcat插件开启服务出现java.net.BindException: Address already in use: JVM_Bind :8080错误原因
[INFO] create webapp with contextPath: /maven_web 五月 11, 2019 6:05:26 下午 org.apache.coyote.AbstractP ...
- table表格中的 colspan rowspan cellpadding cellspacing
横跨两列的单元格: colspan 属性规定单元格可横跨的列数 colspan="2" <table border="1"> <tr> ...
- Cocos2d-x.3.0开发环境搭建
配置:win7 + VS2012 + Cocos2d-x.3.0 + Cocos Studio v1.4.0.1 前言:本文介绍在上述配置下进行游戏开发的环境搭建.开发语言为C++.如果读者不需要查看 ...
- redis 开源客户端下载
redis 开源客户端下载地址: https://github.com/qishibo/AnotherRedisDesktopManager/releases
- python发送邮件(smtplib)
我们在测试完成后,都会发一份邮件也就是我们的测试报告,那么既然要自动化,是不是也可以通过python帮助我们发送邮件?当然这么强大的python可以帮助你完成这个需求 SMTP SMTP(Simple ...
- gitlab-CI作业-yml
stages: - build - deploy before_script: - echo "Restore NuGet Packages..." - echo "do ...
- HTTP常见响应状态码及解释、常用请求头及解释
1.HTTP常见响应状态码及解释2XX Success(成功状态码) 200 表示从客户端发来的请求在服务器端被正常处理204 该状态码表示服务器接收的请求已成功处理,但在返回的响应报文中不含实体的主 ...