idea配置pyspark
默认python已经配好,并已经导入idea,只剩下pyspark的安装
1、解压spark-2.1.0-bin-hadoop2.7放入磁盘目录
D:\spark-2.1.0-bin-hadoop2.7
2、将D:\spark-2.1.0-bin-hadoop2.7\python\pyspark拷贝到目录Python的Lib\site-packages
3、在idea中配置spark环境变量
(1)

(2)
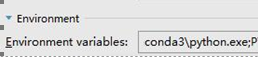
(3)

其中,需要配置的是SPARK_HOME。
如果系统中有多个版本的python,或者系统找不到python的位置,则需要配置PYSPARK_PYTHON ,我这里使用的是conda的python, E:\Program Files\Anaconda3\python.exe
(4) 安装py4j
pip install py4j
4、创建session需要注意的地方
from pyspark.sql import SparkSession
# appName中的内容不能有空格,否则报错
spark = SparkSession.builder.master("local[*]").appName("WordCount").getOrCreate() #获取上下文
sc = spark.sparkContext
带有空格报错情况如下:

5、创建上下文,两种方式
#第一种
conf = SparkConf().setAppName('test').setMaster('local')
sc = SparkContext(conf=conf)
#第二种
sc=SparkContext('local','test')
6、实例(读取文件并打印)
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName('test').setMaster('local')
sc = SparkContext(conf=conf)
rdd = sc.textFile('d:/scala/log.txt')
print(rdd.collect())
结果:

注意:还有一种错误如下所示
Java.util.NoSuchElementException: key not found: _PYSPARK_DRIVER_CALLBACK_HOST
这是因为版本的问题,可能pyspark的版本与spark不匹配
例如:
spark是2.1.0
所以当使用pip安装pyspark时需要带上版本号:
pip install pyspark==2.1.;
皆为2.1版本
idea配置pyspark的更多相关文章
- win10下Anaconda3在虚拟环境python_version=3.5.3 中配置pyspark
1. 序经过了一天的修炼,深深被恶心了,在虚拟环境中配置pyspark花式报错,由于本人实在是不想卸载3.6版的python,所以硬刚了一天,终于摸清了配置方法,并且配置成功,不抱怨了,开讲: 2. ...
- Anaconda中配置Pyspark的Spark开发环境
1.windows下载并安装Anaconda集成环境 URL:https://www.continuum.io/downloads 2.在控制台中测试ipython是否启动正常 3.安装JDK 3.1 ...
- 如何在windows下安装配置pyspark notebook
第一步:安装anaconda anaconda自带一系列科学计算包 下载链接:http://pan.baidu.com/s/1b4jWlg 密码:fqq3 接着配置环境变量:如我安装在D盘下 试一 ...
- (1)安装----anaconda3下配置pyspark【单机】
1.确保已经安装jdk和anaconda3.[我安装的jdk为1.8,anaconda的python为3.6] 2.安装spark,到官网 http://spark.apache.org/downlo ...
- pycharm中配置pyspark
1 下载官网spark-2.1.1-bin-hadoop2.7.tgz(版本自己选择),解压将文件放在了指定路径下,这个文件夹里面有python文件,python文件下还有两个压缩包py4j-some ...
- Ubuntu下导入PySpark到Shell和Pycharm中(未整理)
实习后面需要用到spark,虽然之前跟了edX的spark的课程以及用spark进行machine learning,但那个环境是官方已经搭建好的,但要在自己的系统里将PySpark导入shell(或 ...
- 大数据高可用集群环境安装与配置(09)——安装Spark高可用集群
1. 获取spark下载链接 登录官网:http://spark.apache.org/downloads.html 选择要下载的版本 2. 执行命令下载并安装 cd /usr/local/src/ ...
- Spark 的 python 编程环境
Spark 可以独立安装使用,也可以和 Hadoop 一起安装使用.在安装 Spark 之前,首先确保你的电脑上已经安装了 Java 8 或者更高的版本. Spark 安装 访问Spark 下载页面, ...
- windows下安装spark-python
首先需要安装Java 下载安装并配置Spark 从官方网站Download Apache Spark™下载相应版本的spark,因为spark是基于hadoop的,需要下载对应版本的hadoop才行, ...
随机推荐
- Zabbix-3.4简介及安装配置
一.概述 1.为什么选择Zabbix? Zabbix是一款能够监控各种网络参数以及服务器健康性和完整性的软件.Zabbix使用灵活的通知机制,允许用户为几乎任何事件配置基于邮件的告警.这样可以快速反馈 ...
- BitMap原理
BitMap原理
- 创建可执行的JAR包并运行
将一个应用程序制作成可执行的JAR包,通过JAR包来发布应用程序.创建可执行JAR包的关键在于:让java -jar命令知道JAR包中哪个类是主类,java -jar命令可以通过运行该主类来运行程序. ...
- Pairs Forming LCM (LightOJ - 1236)【简单数论】【质因数分解】【算术基本定理】(未完成)
Pairs Forming LCM (LightOJ - 1236)[简单数论][质因数分解][算术基本定理](未完成) 标签: 入门讲座题解 数论 题目描述 Find the result of t ...
- JavaScript -- 筑基
本片博客记录了我JavaScript筑基阶段的学习内容,JavaScript不是Java,但是我下意识的把它和java对比学习,有些地方比较有趣,有些地方从java角度看,简直匪夷所思,不过现在总体感 ...
- SpringBoot的启动流程分析(2)
我们来分析SpringApplication启动流程中的run()方法,代码如下 public ConfigurableApplicationContext run(String... args) { ...
- C#_.NetFramework_Web项目_EXCEL数据导出
[推荐阅读我的最新的Core版文章,是最全的介绍:C#_.NetCore_Web项目_EXCEL数据导出] 项目需引用NPOI的NuGet包: A-2:EXCEL数据导出--Web项目--C#代码导出 ...
- Command CompileSwiftSources failed with a nonzero exit code
Xcode错误提示:Command CompileSwiftSources failed with a nonzero exit code,网上找了好多才搞定,通过在Build Setting里面自添 ...
- vs code 运行 Django 怎么修改端口
1.具体操作步骤如下 默认情况下,通过 python manage.py runserver 命令行模式默认打开是 8000 端口,如下图所示: 在浏览器预览效果如下: 为了防止端口冲突,我们一般会修 ...
- git submodule git 子模块管理相关操作
Git 子模块操作相关的一些命令备忘: # 当使用git clone下来的工程中带有submodule时,初始的时候 submodule的内容并不会自动下载下来的,需执行如下命令: git submo ...