idea配置pyspark
默认python已经配好,并已经导入idea,只剩下pyspark的安装
1、解压spark-2.1.0-bin-hadoop2.7放入磁盘目录
D:\spark-2.1.0-bin-hadoop2.7
2、将D:\spark-2.1.0-bin-hadoop2.7\python\pyspark拷贝到目录Python的Lib\site-packages
3、在idea中配置spark环境变量
(1)

(2)
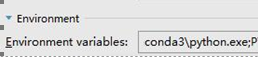
(3)

其中,需要配置的是SPARK_HOME。
如果系统中有多个版本的python,或者系统找不到python的位置,则需要配置PYSPARK_PYTHON ,我这里使用的是conda的python, E:\Program Files\Anaconda3\python.exe
(4) 安装py4j
pip install py4j
4、创建session需要注意的地方
from pyspark.sql import SparkSession
# appName中的内容不能有空格,否则报错
spark = SparkSession.builder.master("local[*]").appName("WordCount").getOrCreate() #获取上下文
sc = spark.sparkContext
带有空格报错情况如下:

5、创建上下文,两种方式
#第一种
conf = SparkConf().setAppName('test').setMaster('local')
sc = SparkContext(conf=conf)
#第二种
sc=SparkContext('local','test')
6、实例(读取文件并打印)
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName('test').setMaster('local')
sc = SparkContext(conf=conf)
rdd = sc.textFile('d:/scala/log.txt')
print(rdd.collect())
结果:

注意:还有一种错误如下所示
Java.util.NoSuchElementException: key not found: _PYSPARK_DRIVER_CALLBACK_HOST
这是因为版本的问题,可能pyspark的版本与spark不匹配
例如:
spark是2.1.0
所以当使用pip安装pyspark时需要带上版本号:
pip install pyspark==2.1.;
皆为2.1版本
idea配置pyspark的更多相关文章
- win10下Anaconda3在虚拟环境python_version=3.5.3 中配置pyspark
1. 序经过了一天的修炼,深深被恶心了,在虚拟环境中配置pyspark花式报错,由于本人实在是不想卸载3.6版的python,所以硬刚了一天,终于摸清了配置方法,并且配置成功,不抱怨了,开讲: 2. ...
- Anaconda中配置Pyspark的Spark开发环境
1.windows下载并安装Anaconda集成环境 URL:https://www.continuum.io/downloads 2.在控制台中测试ipython是否启动正常 3.安装JDK 3.1 ...
- 如何在windows下安装配置pyspark notebook
第一步:安装anaconda anaconda自带一系列科学计算包 下载链接:http://pan.baidu.com/s/1b4jWlg 密码:fqq3 接着配置环境变量:如我安装在D盘下 试一 ...
- (1)安装----anaconda3下配置pyspark【单机】
1.确保已经安装jdk和anaconda3.[我安装的jdk为1.8,anaconda的python为3.6] 2.安装spark,到官网 http://spark.apache.org/downlo ...
- pycharm中配置pyspark
1 下载官网spark-2.1.1-bin-hadoop2.7.tgz(版本自己选择),解压将文件放在了指定路径下,这个文件夹里面有python文件,python文件下还有两个压缩包py4j-some ...
- Ubuntu下导入PySpark到Shell和Pycharm中(未整理)
实习后面需要用到spark,虽然之前跟了edX的spark的课程以及用spark进行machine learning,但那个环境是官方已经搭建好的,但要在自己的系统里将PySpark导入shell(或 ...
- 大数据高可用集群环境安装与配置(09)——安装Spark高可用集群
1. 获取spark下载链接 登录官网:http://spark.apache.org/downloads.html 选择要下载的版本 2. 执行命令下载并安装 cd /usr/local/src/ ...
- Spark 的 python 编程环境
Spark 可以独立安装使用,也可以和 Hadoop 一起安装使用.在安装 Spark 之前,首先确保你的电脑上已经安装了 Java 8 或者更高的版本. Spark 安装 访问Spark 下载页面, ...
- windows下安装spark-python
首先需要安装Java 下载安装并配置Spark 从官方网站Download Apache Spark™下载相应版本的spark,因为spark是基于hadoop的,需要下载对应版本的hadoop才行, ...
随机推荐
- python将字符串插入表中避免单双引号问题
调用pymysql.escape_string('向数据库插入的数据') 例如: import pymysql str = 'as"sdf' print(pymysql.escape_str ...
- 如何在linux终端创建文件
我们都知道可以用mkdir命令创建一个新的目录,但更多时候如果能直接创建一个文件(普通文件)会让人感觉更愉悦:这样就可以不用在去打开一个专门的创建文本文件的软件,然后还要设置文件名,保存路径那样的繁琐 ...
- 09-Node.js学习笔记-异步编程
同步API,异步API 同步API:只有当前API执行完成后,才能继续执行下一个API console.log('before'); console.log('after'); 异步API:当前API ...
- 手机投屏工具与HOSTS切换工具
ApowerMirror windows -->switchhosts
- java学习路线推荐,希望能帮到你
很多小白刚开始学习java时,肯定迷惘过,因为对java基本是啥也不懂的,一直想知道java的具体学习路线,我曾经也看了许许多多的java经验分享的帖子,评论,以及其他各种培训机构所谓的学习路线,特别 ...
- quarter软件的破解
链接;http://www.openedv.com/forum.php?mod=viewthread&tid=275857&extra=page%3D1 这个是正点原子提供的破解方法, ...
- TopCoder12727 「SRM590Hard」FoxAndCity 最小割离散变量模型
问题描述 一张 \(N\) 个点无向图,边权都为 \(1\) ,添加若干条边,最小化 \(\sum\limits_{1 \le i \le n,i \in N_{+}}{(a_i-b_i)^2}\). ...
- Swoole如何处理高并发
有需要学习交流的友人请加入swoole交流群的咱们一起,有问题一起交流,一起进步!前提是你是学技术的.感谢阅读! 点此加入该群 swoole如何处理高并发 ①Reactor模型介绍 IO复用异步非阻塞 ...
- IT兄弟连 HTML5教程 CSS3揭秘 CSS3概述
对于Web开发者来说,CSS3不只是一门新奇的技术,更重要的是这些全新概念的Web应用给开发人员带来了无限的可能性,也极大地提高了开发效率.我们不必再依赖图片或者JavaScript去完成圆角.多背景 ...
- 01-Vue.js基础
一.Vue基础 1.介绍 Vue是一套用于构建用户界面的渐进式框架.Vue的核心库只关注视图层,不仅容易上手,还便于与第三方库或既有的项目整合.兼容性:Vue 不支持 IE8 及以下版本,因为 Vue ...