增强学习Q-learning分析与演示(入门)
这篇写的是不太对的,详细还是找个靠谱的吧!
一些说明、参阅
https://www.cnblogs.com/hhh5460/p/10134018.html
http://baijiahao.baidu.com/s?id=1597978859962737001&wfr=spider&for=pc
https://www.jianshu.com/p/29db50000e3f
问题提出
为了实现自走的路径,并尽量避免障碍,设计一个路径。
如图所示,当机器人在图中的任意网格中时,怎样让它明白周围环境,最终到达目标位置。
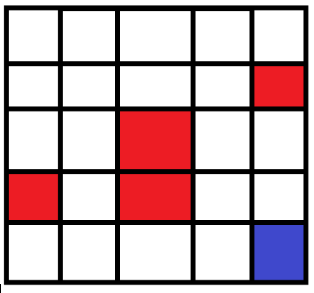
这里给出一个运行结果:
首先给他们编号如下:作为位置的标识。
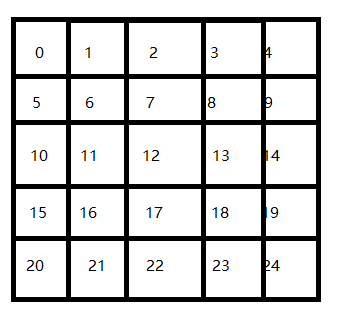
然后利用Q-Learning的奖赏机制,完成数据表单更新,最终更新如下:
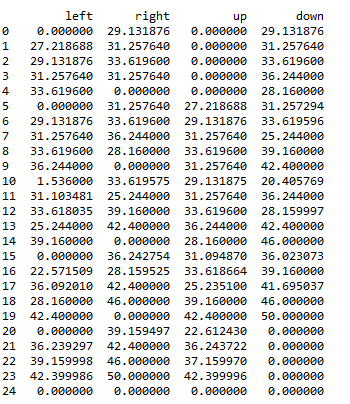
在机器人实际选择路径时,按照该表中的最大值选择,最终走到24号位置,并避开了红色方块。
如初始位置在4时候,首先选择了最大值向左到3,然后在3处选择了最大值向下,然后到8处选择了向下,等等,最终完成路径的选择。而这种选择正是使用Q-Learning实现的。
Q-learning的想法
奖赏机制
在一个陌生的环境中,机器人首先的方向是随机选择的,当它从起点开始出发时,选择了各种各样的方法,完成路径。
但是在机器人碰到红色方块后,给予惩罚,则经过多次后,机器人会避开惩罚位置。
当机器人碰到蓝色方块时,给予奖赏,经过多次后,机器人倾向于跑向蓝色方块的位置。
具体公式
完成奖赏和惩罚的过程表达,就是用值表示吧。
首先建立的表是空表的,就是说,如下这样的表是空的,所有值都为0:

在每次行动后,根据奖惩情况,更新该表,完成学习过程。在实现过程中,将奖惩情况也编制成一张表。表格式如上图类似。
而奖惩更新公式为:
贝尔曼方程:
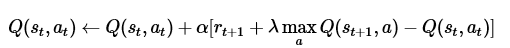
其中的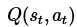 表示当前的Q表,就是上图25行4列的表单。
表示当前的Q表,就是上图25行4列的表单。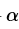 表示学习率,
表示学习率, 表示下一次行为会得到的奖惩情况,
表示下一次行为会得到的奖惩情况,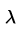 表示一个贪婪系数,在这里的公式中,就是说,如果它的数值比较大,则更倾向于对远方的未来奖赏。
表示一个贪婪系数,在这里的公式中,就是说,如果它的数值比较大,则更倾向于对远方的未来奖赏。
(该式子在很多网页文本中并没有固定的格式,如贪婪系数,在有些时候是随着步数的增加而递减的(可能)。
推荐阅读:
https://www.jianshu.com/p/29db50000e3f
等,其中包括了更新Q表中的一些过程。
代码实现-准备过程
他的代码讲解:https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/2-1-general-rl/
他设计了一种方案实现了机器人在一维空间中如何移动,但是不涉及障碍物的问题,并使用了较高的编程能力,有显示路径过程。
而本文侧重于如何表示出路径,完成思路示例。
导入对应的库函数,并建立问题模型:
import numpy as np
import pandas as pd
import time
N_STATES = 25 # the length of the 2 dimensional world
ACTIONS = ['left', 'right','up','down'] # available actions
EPSILON = 0.3 # greedy police
ALPHA = 0.8 # learning rate
GAMMA = 0.9 # discount factor
MAX_EPISODES = 100 # maximum episodes
FRESH_TIME = 0.00001 # fresh time for one move
创建Q表的函数:
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))), # q_table initial values
columns=actions, # actions's name
)
return table
行为选择的函数:
行为选择过程中,使用这样长的表示也就是为了表达:在边界时候,机器人的路径有些不能选的,要不就超出索引的表格了。。
当贪婪系数更小时,更倾向于使用随机方案,或者当表初始时所有数据都为0,则使用随机方案进行行为选择。
当np.random.uniform()< =EPSILON时,则使用已经选择过的最优方案完成Qlearning的行为选择,也就是说,机器人并不会对远方的未知目标表示贪婪。(这里的表达是和上述公式的贪婪系数大小的作用是相反过来的)
def choose_action(state, q_table):
state_actions = q_table.iloc[state, :]
if (np.random.uniform() > EPSILON) or ((state_actions == 0).all()): # act non-greedy or state-action have no value
if state==0:
action_name=np.random.choice(['right','down'])
elif state>0 and state<4:
action_name=np.random.choice(['right','down','left'])
elif state==4:
action_name=np.random.choice(['left','down'])
elif state==5 or state==15 or state==10 :
action_name=np.random.choice(['right','up','down'])
elif state==9 or state==14 or state==19 :
action_name=np.random.choice(['left','up','down'])
elif state==20:
action_name=np.random.choice(['right','up'])
elif state>20 and state<24:
action_name=np.random.choice(['right','up','left'])
elif state==24:
action_name=np.random.choice(['left','up'])
else:
action_name=np.random.choice(ACTIONS)
else: # act greedy
action_name = state_actions.idxmax() # replace argmax to idxmax as argmax means a different function in newer version of pandas
return action_name
奖赏表达:
函数中参数S,表示state(状态),a表示action(行为),行为0到3分别表示左右上下。该表中,给出了在当前状态下,下一个方向会导致的奖惩情况。
def get_init_feedback_table(S,a):
tab=np.ones((25,4))
tab[8][1]=-10;tab[4][3]=-10;tab[14][2]=-10
tab[11][1]=-10;tab[13][0]=-10;tab[7][3]=-10;tab[17][2]=-10
tab[16][0]=-10;tab[20][2]=-10;tab[10][3]=-10;
tab[18][0]=-10;tab[16][1]=-10;tab[22][2]=-10;tab[12][3]=-10
tab[23][1]=50;tab[19][3]=50
return tab[S,a]
获取奖惩:
该函数调用了上一个奖惩表示的函数,获得奖惩信息,其中的参数S,A,同上。
当状态S,A符合了下一步获得最终的结果时,则结束(终止),表示完成了目标任务。否则更新位置S
def get_env_feedback(S, A):
action={'left':0,'right':1,'up':2,'down':3};
R=get_init_feedback_table(S,action[A])
if (S==19 and action[A]==3) or (S==23 and action[A]==1):
S = 'terminal'
return S,R
if action[A]==0:
S-=1
elif action[A]==1:
S+=1
elif action[A]==2:
S-=5
else:
S+=5
return S, R
代码实现-开始训练
首先初始化Q表,然后设定初始路径就是在0位置(也就是说每次机器人,从位置0开始出发)
训练迭代次数MAX_EPISODES已经在之前设置。
在每一代的训练过程中,选择行为(随机或者使用Q表原有),然后根据选择的行为和当前的位置,获得奖惩情况:S_, R
当没有即将发生的行为不会到达最终目的地时候,使用:
q_target = R + GAMMA * q_table.iloc[S_, :].max()
q_table.loc[S, A] += ALPHA * (q_target - q_table.loc[S, A])
这两行完成q表的更新。(对照贝尔曼方程)
当完成时候,即终止,开始下一代的训练。
def rl():
# main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS)
for episode in range(MAX_EPISODES):
S = 0
is_terminated = False while not is_terminated:
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A) # take action & get next state and reward
if S_ != 'terminal':
q_target = R + GAMMA * q_table.iloc[S_, :].max() # next state is not terminal
else:
print(1)
q_target = R # next state is terminal
is_terminated = True # terminate this episode q_table.loc[S, A] += ALPHA * (q_target - q_table.loc[S, A]) # update
S = S_ # move to next state
return q_table if __name__ == "__main__":
q_table = rl()
print('\r\nQ-table:\n')
print(q_table)
效果-总结
效果其实和开头一样,调整合适的参数,最终输出的q表自然有对应的影响。
明显可以得到的是,贪婪系数会影响训练时间等。
所有代码就是以上。可以使用eclipse的pydev下进行运行,调试。并观察没一步对表格的影响
增强学习Q-learning分析与演示(入门)的更多相关文章
- 增强学习(五)----- 时间差分学习(Q learning, Sarsa learning)
接下来我们回顾一下动态规划算法(DP)和蒙特卡罗方法(MC)的特点,对于动态规划算法有如下特性: 需要环境模型,即状态转移概率\(P_{sa}\) 状态值函数的估计是自举的(bootstrapping ...
- 增强学习Reinforcement Learning经典算法梳理3:TD方法
转自:http://blog.csdn.net/songrotek/article/details/51382759 博客地址:http://blog.csdn.net/songrotek/artic ...
- 增强学习(Reinforcement Learning and Control)
增强学习(Reinforcement Learning and Control) [pdf版本]增强学习.pdf 在之前的讨论中,我们总是给定一个样本x,然后给或者不给label y.之后对样本进行 ...
- 强化学习9-Deep Q Learning
之前讲到Sarsa和Q Learning都不太适合解决大规模问题,为什么呢? 因为传统的强化学习都有一张Q表,这张Q表记录了每个状态下,每个动作的q值,但是现实问题往往极其复杂,其状态非常多,甚至是连 ...
- 深度增强学习--Deep Q Network
从这里开始换个游戏演示,cartpole游戏 Deep Q Network 实例代码 import sys import gym import pylab import random import n ...
- 强化学习_Deep Q Learning(DQN)_代码解析
Deep Q Learning 使用gym的CartPole作为环境,使用QDN解决离散动作空间的问题. 一.导入需要的包和定义超参数 import tensorflow as tf import n ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- 增强学习(四) ----- 蒙特卡罗方法(Monte Carlo Methods)
1. 蒙特卡罗方法的基本思想 蒙特卡罗方法又叫统计模拟方法,它使用随机数(或伪随机数)来解决计算的问题,是一类重要的数值计算方法.该方法的名字来源于世界著名的赌城蒙特卡罗,而蒙特卡罗方法正是以概率为基 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
随机推荐
- Linux下Docker以及portainer相关配置
一.安装使用Docer CE 本文以CentOS 7为例,安装docker CE版本,docker有两种版本,社区版本CE和企业版本EE,此处学习研究以CE版本为例, 两种安装方式可选:1.使用yum ...
- UnityShader之积雪效果
积雪效果是比较简单的,只需要计算顶点法线方向和世界向上方向之间的点乘,将得到的值与预设的阀值比较,小于阀值为0,用这个值进行插值就OK了 代码: Shader "MyShader/SnowS ...
- mongoDB的CRUD的总结
今天开始接触非关系型数据库的mongoDB,现在将自己做的笔记发出来,供大家参考,也便于自己以后忘记了可以查看. 首先,mongoDB,是一种数据库,但是又区别与mysql,sqlserver.orc ...
- 100天搞定机器学习|Day16 通过内核技巧实现SVM
前情回顾 机器学习100天|Day1数据预处理100天搞定机器学习|Day2简单线性回归分析100天搞定机器学习|Day3多元线性回归100天搞定机器学习|Day4-6 逻辑回归100天搞定机器学习| ...
- git语句(后续补充)
如果你是windows用户,需要下载一个git应用程序,一路点就行,没有什么需要注意的地方 安装完成后在任一文件夹内右键都有显示,单击git bash here即可 简易的命令行入门教程: Git 全 ...
- .net软件开发脚本规范-JS标准
一. JS标准 新增页面表单检查方法名称固定为checkForm. 查询页面表单检查方法名称固定为checkSearchForm. 检查表单方法checkForm与checkSearchForm固定放 ...
- Day 03--设计与完善(一)
1.今天我们把软件原型基本完成了,功能流程一套下来,像一个真正的软件了.这是几个主要模块: 首先是首页,登入小程序后可以直观地看到各个食堂,并显示自己的定位.屏幕下方还可以时刻切换查看自己以前的订单. ...
- Mac 打造开发工作环境
近日公司配的dell笔记本越来越难担重任(主要是CPU太差,本人是Java开发,IDE一编译CPU就100%),于是狠下心入手了一台常规顶配Macbook Pro,现记录新本本的调教过程. Homeb ...
- Freemarker提供了3种加载模板目录的方法
Freemarker提供了3种加载模板目录的方法 原创 2016年08月24日 14:50:13 标签: freemarker / Configuration 8197 Freemarker提供了3种 ...
- JS基础-该如何理解原型、原型链?
JS的原型.原型链一直是比较难理解的内容,不少初学者甚至有一定经验的老鸟都不一定能完全说清楚,更多的"很可能"是一知半解,而这部分内容又是JS的核心内容,想要技术进阶的话肯定不能对 ...