node爬虫之图片下载
背景:针对一些想换头像的玩家,而又不知道用什么头像的,作为一名代码爱好者,能用程序解决的,就不用程序来换头像,说干就干,然后就整理了一下。
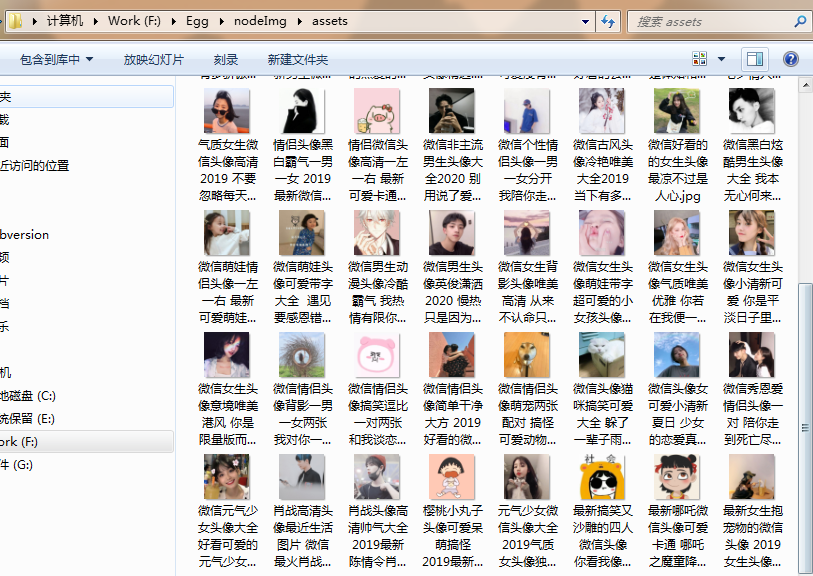
效果图
环境配置
- 安装node环境
- node -v
- node版本最好在8.11.1以上
项目结构
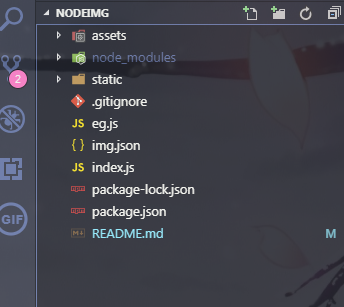
assets是存放所下载的图片
static是静态资源页面
eg.js是下载图片示例(node eg.js)
img.json是网页所获取的json数据
index.js属于服务端
安装依赖
npm init ( 会生成一个package.json) npm i express --save-dev npm i cheerio--save-dev npm i superagent--save-dev npm i superagent-charset--save-dev npm i request--save-dev
- SuperAgent 是一个轻量级、灵活的、易读的、低学习曲线的客户端请求代理模块,使用在NodeJS环境中
- superagent-charset 防止爬取下来的数据乱码,更改字符格式
- cheerio 是jquery核心功能的一个快速灵活而又简洁的实现,主要是为了用在服务器端需要对DOM进行操作的地方。
- request 的功能比较强大,在 这里只是为了下载图片用的
代码区
1. eg.js
var fs = require('fs');
var request = require("request");
var path = require('path');
var src = "https://pic.qqtn.com/up/2019-6/2019061811092772406.jpg";
var writeStream = fs.createWriteStream('./assets/aa.png');
var readStream = request(src)
readStream.pipe(writeStream);
readStream.on('end', function() {
console.log('文件下载成功');
});
readStream.on('error', function() {
console.log("错误信息:" + err)
})
writeStream.on("finish", function() {
console.log("文件写入成功");
writeStream.end();
});
2.index.js
var superagent = require('superagent');
var charset = require('superagent-charset');
charset(superagent);
var express = require('express');
var baseUrl = 'https://www.qqtn.com/';
const cheerio = require('cheerio');
var request = require("request");
var fs = require('fs')
var path = require('path')
var checkDir = fs.existsSync("assets");
var app = express();
app.use(express.static('static'))
app.get('/index', function (req, res) {
//设置请求头
res.header("Access-Control-Allow-Origin", "*");
res.header('Access-Control-Allow-Methods', 'PUT, GET, POST, DELETE, OPTIONS');
res.header("Access-Control-Allow-Headers", "X-Requested-With");
res.header('Access-Control-Allow-Headers', 'Content-Type');
//类型
console.log(req.query, '类型')
var type = req.query.type;
//页码
var page = req.query.page;
type = type || 'weixin';
page = page || '';
var route = `tx/${type}tx_${page}.html`
//网页页面信息是gb2312,所以chaeset应该为.charset('gb2312'),一般网页则为utf-8,可以直接使用.charset('utf-8')
superagent.get(baseUrl + route)
.charset('gb2312')
.end(function (err, sres) {
var items = [];
if (err) {
console.log('ERR: ' + err);
res.json({ code: , msg: err, sets: items });
return;
}
var $ = cheerio.load(sres.text);
$('div.g-main-bg ul.g-gxlist-imgbox li a').each(function (idx, element) {
var $element = $(element);
var $subElement = $element.find('img');
var thumbImgSrc = $subElement.attr('src');
items.push({
title: $(element).attr('title'),
href: $element.attr('href'),
thumbSrc: thumbImgSrc
});
});
if (!checkDir) {
fs.mkdir('assets', function (error) {
if (error) {
console.log(error);
return false;
}
console.log('创建目录成功');
})
}
fs.access(path.join(__dirname, '/img.json'), fs.constants.F_OK, err => {
if (err) { // 文件不存在
fs.writeFile(path.join(__dirname, '/img.json'), JSON.stringify([
{
route,
items
}
]), err => {
if (err) {
console.log(err)
return false
}
console.log('保存成功')
})
} else {
fs.readFile(path.join(__dirname, '/img.json'), (err, data) => {
if (err) {
return false
}
data = JSON.parse(data.toString())
let exist = data.some((page, index) => {
return page.route == route
})
if (!exist) {
fs.writeFile(path.join(__dirname, 'img.json'), JSON.stringify([
...data,
{
route,
items
},
]), err => {
if (err) {
return false
}
})
}
})
}
res.json({ code: , msg: "", data: items });
})
try {
fs.readFile(path.join(__dirname, '/img.json'), (err, data) => {
if (err) {
return false
}else{
data = JSON.parse(data.toString());
data.map((v, i) => {
v.items.map((v,i) => {
i = request(v.thumbSrc)
// 后缀.jpg可用正则匹配
i.pipe(fs.createWriteStream('./assets/' + v.title + '.jpg'));
})
})
}
})
} catch(err){}
})
});
app.get('/show', (req, res) => {
fs.readFile(path.join(__dirname, 'img.json'), (err, data) => {
if (err) {
console.log(err)
return false
}
res.json(data.toString())
})
})
var server = app.listen(, function () {
var host = server.address().address
var port = server.address().port
})
3.static文件夹下index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
</head>
<body>
<script src="./index.js"></script>
</body>
</html>
4.static文件夹下index.js
fetch('/index', {
method: 'GET'
}).then(res => {
return res.json()
}).then(res => {
if (res.code == ) {
fetch('/show', {
method: 'GET'
}).then(res => {
return res.json()
}).then(res => {
res = JSON.parse(res)
console.log(res, res.length)
document.body.innerHTML = res.map((page, index) => {
console.log(page)
return page.items.map((item, itemIndex) => {
return `<a href="${item.thumbSrc}" ><img src="${item.thumbSrc}" width="" height=""/></a>`
}).join('')
}).join('')
})
}
})
总结
写到这里基本是结束了,对于node我还是怀着一个敬畏的心,摸摸索索终于把这个demo写完了,项目也传到gitHub了如有需要可私信
node爬虫之图片下载的更多相关文章
- Node.js制作图片下载爬虫的一般步骤
图片下载爬虫分两部分:爬页面和下载图片. 爬页面时先看网址是https还是http的,然后选择不同的内置对象: 其次看编码,如果是charset=gb2312的网页就需要iconv帮忙转码,好在大部分 ...
- node爬虫 -- 网页图片
相信大家都听说过爬虫,我们也听说过Python是可以很方便地爬取网络上的图片,但是奈何本人不会Python,就只有通过 Node 来实践一下了. 接下来看我如何 板砖 ! !!
- Node.js mimimn图片批量下载爬虫 1.00
这个爬虫在Referer设置上和其它爬虫相比有特殊性.代码: //====================================================== // mimimn图片批 ...
- Node.js meitulu图片批量下载爬虫1.01版
在 http://www.cnblogs.com/xiandedanteng/p/7614051.html 一文我曾经书写过一个图片下载爬虫,但原有程序不是为下载图片而设计故有些绕,于是稍微改写了一下 ...
- node 爬虫 --- 批量下载图片
步骤一:创建项目 npm init 步骤二:安装 request,cheerio,async 三个模块 request 用于请求地址和快速下载图片流. https://github.com/reque ...
- python简易爬虫来实现自动图片下载
菜鸟新人刚刚入住博客园,先发个之前写的简易爬虫的实现吧,水平有限请轻喷. 估计利用python实现爬虫的程序网上已经有太多了,不过新人用来练手学习python确实是个不错的选择.本人借鉴网上的部分实现 ...
- (8)分布式下的爬虫Scrapy应该如何做-图片下载(源码放送)
转载主注明出处:http://www.cnblogs.com/codefish/p/4968260.html 在爬虫中,我们遇到比较多需求就是文件下载以及图片下载,在其它的语言或者框架中,我们可能 ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
- 手把手教你写基于C++ Winsock的图片下载的网络爬虫
手把手教你写基于C++ Winsock的图片下载的网络爬虫 先来说一下主要的技术点: 1. 输入起始网址,使用ssacnf函数解析出主机号和路径(仅处理http协议网址) 2. 使用socket套接字 ...
随机推荐
- git分支合并解决冲突
git分支合并,解决冲突 1.手动解决冲突 手动解决冲突,需要使用编辑器,把所有文件中出现的冲突地方修改,然后再添加到暂存区再提交 >>>>>>brancha so ...
- JS字符串替换,将一个字符串中的特定字符串换成其他字符串
- JNDI和JDBC的区别-个人理解
网上关于JNDI和JDBC的定义有很多,但是都很官方不容易理解,下面是我最近查阅资料得出的心得体会.希望对你在理解上有一点点的帮助,说的不对的请指正哦. JDBC: 看到最多的就是 Java Data ...
- 黄聪:不使用 webpack,vuejs 异步加载模板
webpack 打包不会玩,整了这么个小玩具 一段 vue 绑定代码,关键点在 gmallComponent 1.异步加载外部 vue 文件(非 .vue) 2.按一定规则拆分 template.sc ...
- 【UOJ#242】【UR#16】破坏蛋糕(计算几何)
[UOJ#242][UR#16]破坏蛋糕(计算几何) 题面 UOJ 题解 为了方便,我们假定最后一条直线是从上往下穿过来的,比如说把它当成坐标系的\(y\)轴. 于是我们可以处理出所有交点,然后把它们 ...
- 使用dapper遇到的问题及解决方法
在使用dapper进行数据查询时遇到的一个问题,今天进行问题重现做一个记录,免得忘记以后又犯同样的错误. 自己要实现的是:select * from tablename where id in(1,2 ...
- go开发注意事项和dos的一些操作
不需要加分号 写法 go编译器一行一行编译,所以多条语句不能写在同一行,否则会报错 go语言定义的变量或者import的包如果没有使用到,代码不能通过编译 func main() { ... } 只能 ...
- Taro聊天室|react+taro仿微信聊天App界面|taro聊天实例
一.项目简述 taro-chatroom是基于Taro多端实例聊天项目,运用Taro+react+react-redux+taroPop+react-native等技术开发的仿微信App界面聊天室,实 ...
- JavaScript几种继承方式
我们先构建一个Person的构造函数 function Person(name) { this.name=name; } Person.prototype.sayHi=function () { co ...
- 在Dynamics CRM中自定义一个通用的查看编辑注释页面
关注本人微信和易信公众号: 微软动态CRM专家罗勇 ,回复162或者20151016可方便获取本文,同时可以在第一时间得到我发布的最新的博文信息,follow me! 注释在CRM中的显示是比较特别, ...