《机器学习技法》---核型SVM
(本文内容和图片来自林轩田老师《机器学习技法》)
1. 核技巧引入
如果要用SVM来做非线性的分类,我们采用的方法是将原来的特征空间映射到另一个更高维的空间,在这个更高维的空间做线性的SVM。即:

在这里我们计算这个向量内积有两种方法:一种是对Φ(x)给出明确的定义,分别算出两个高维向量,再做内积;另一种就是利用核函数,直接算出高维的内积。我们以一个例子来看这两种方法,定义一个二次转化:

我们可以直接计算出内积:
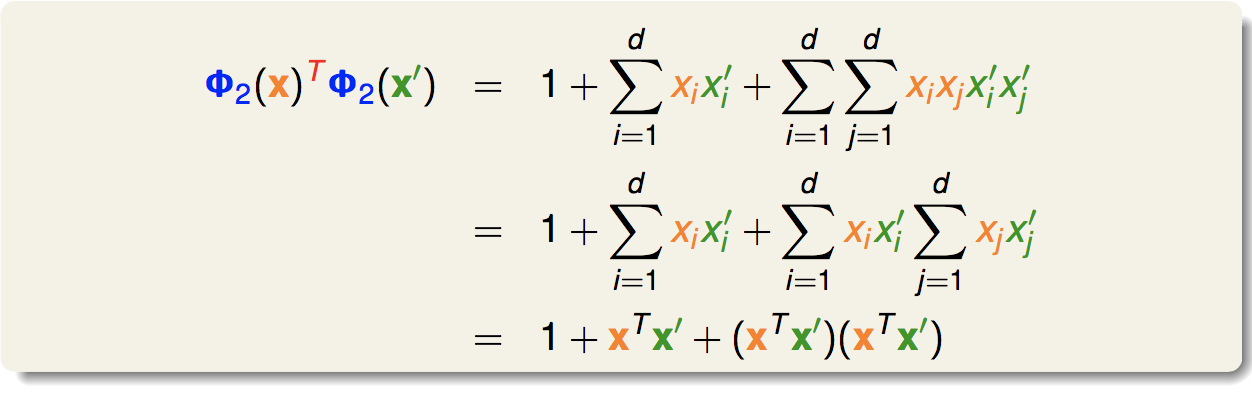
可以看出,最后的结果能够用x和x一撇表示出来,这就是一个核函数:

在这里,我们是给出了一个Φ(x)来推出它的核函数。但事实上,我们可以直接给一个核函数(只要我们能证明它是一个核函数),而不用知道它对应的Φ(x)是什么。这样做的一个好处就是我们不用求出高维向量在做内积,可以通过形式简单的核函数直接计算内积,计算复杂度降低了,到后面我们用核函数甚至可以引入无限维的转换。
我们的b值就是:
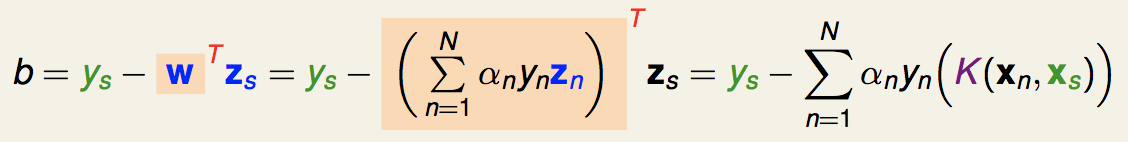
最终得到的分离超平面就是:
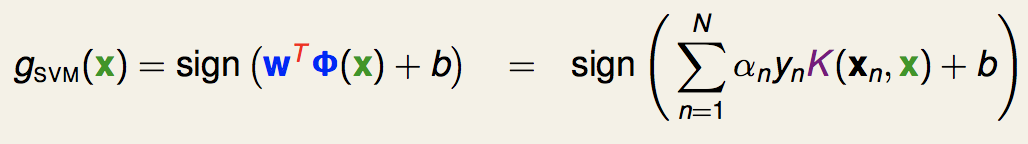
可以看出,不管是求解的优化问题还是最后的模型,我们都可以用核函数来表示。(这里我们不用知道w是什么)
因此,通过核函数的引入,我们相当于隐式的在高维空间进行线性SVM,而不用知道低维到高维的具体映射是什么。
关于使用核函数后的时间复杂度的优化,如下:

2 .多项式核函数
首先对一个常用的核函数——二次多项式核函数做导出:

对于不同的二次核,我们产生的决策边界是不同的:
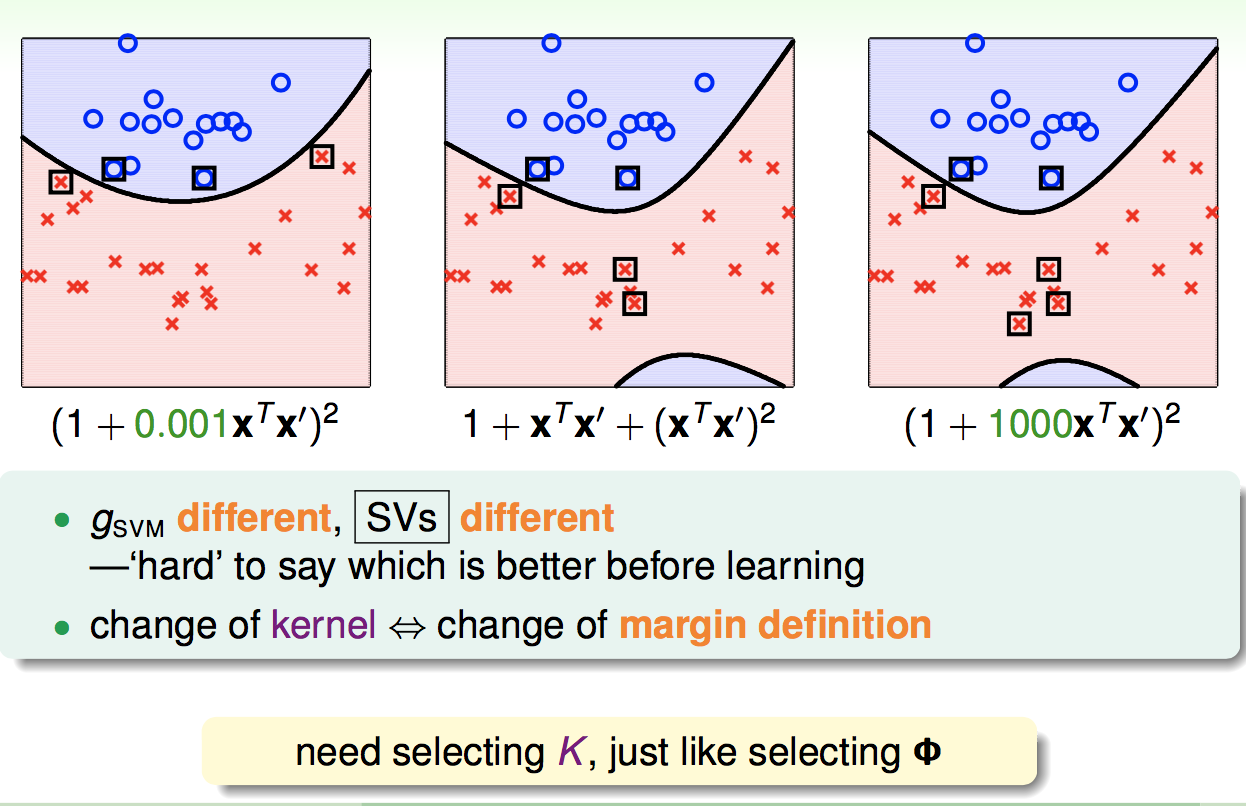
之后我们可以推广出通用的多项式核函数:

3. 高斯核函数
我们可以证明高斯核函数是一个核函数,并且它对应一个到无限维的映射:
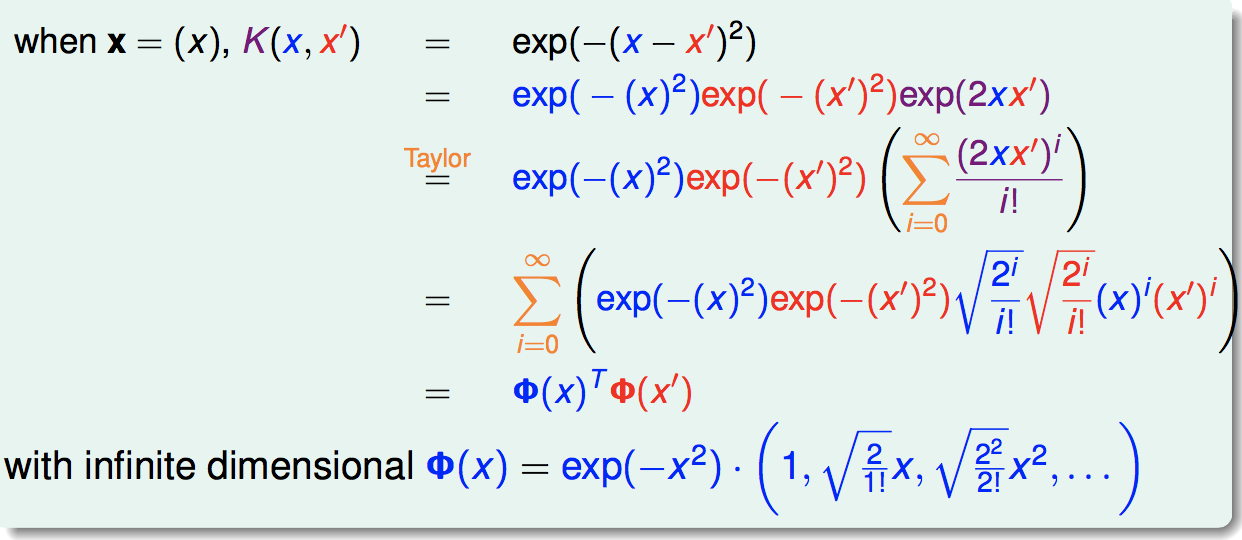
更通用的高斯核函数为:
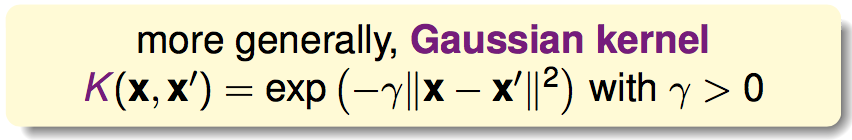
高斯核SVM的分离超平面就是:

可以看出,模型是一堆中心在支撑向量上的高斯函数的线性组合,因此高斯核SVM也被称为RBF。
总结一下,SVM可以做的事情:

首先是有分离超平面,然后引入了的高维度转换(使得我们可以做非线性分类),然后使用了核技巧(使得我们降低了复杂度并且可以引入无限维的转换),在这些基础上,SVM有它的large-margin机制来确保我们的模型复杂度比较小(泛化能力)。
最后存储模型的时候,我们不用存储高维度的w,存储的是支持向量以及它们对应的阿尔法值。
接下来我们看看不同的高斯核svm产生的边界:
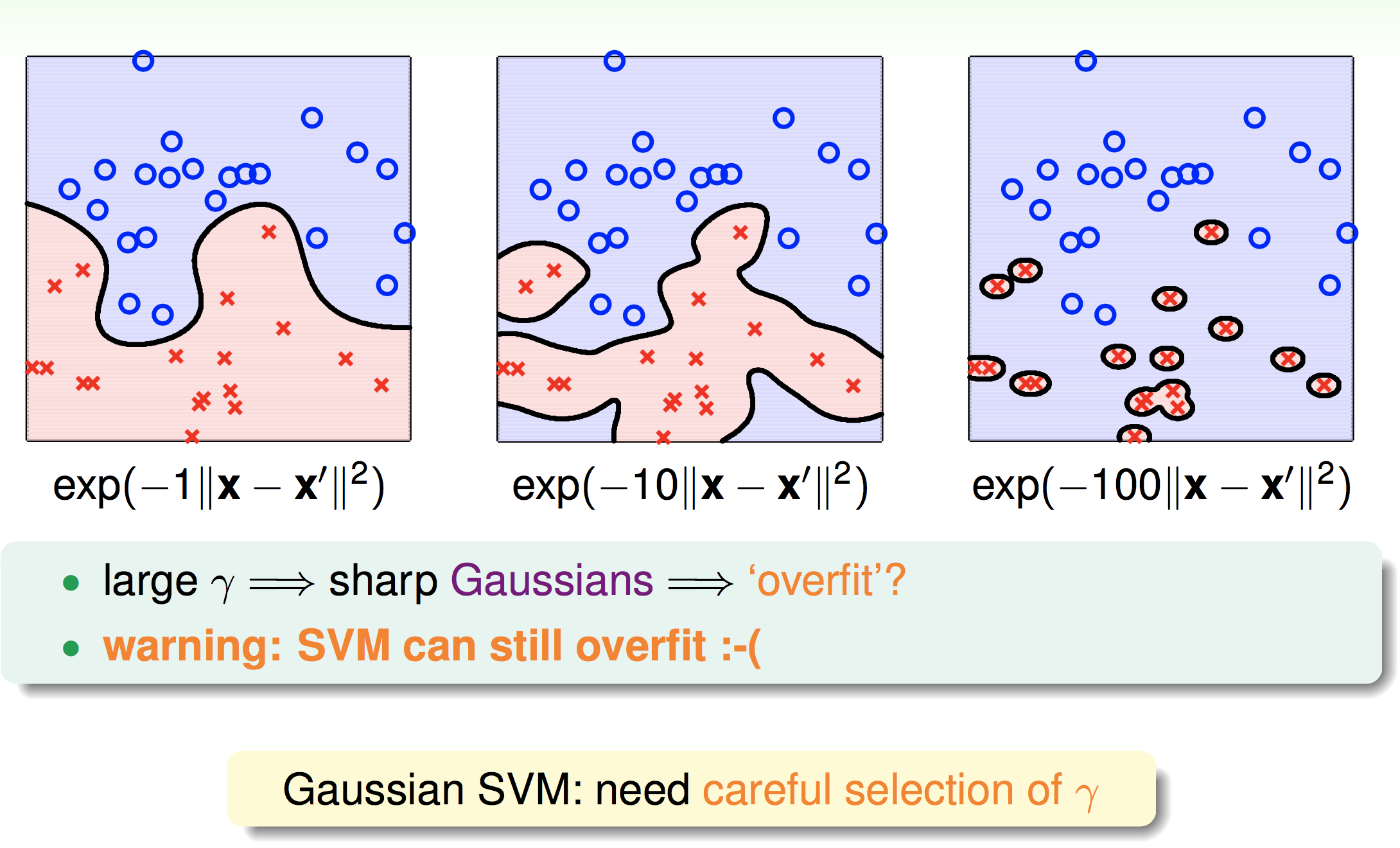
因此,即使SVM有large-margin的保护,但是还是要慎选伽马的值,否则仍然会过拟合。
4.几种核函数的比较
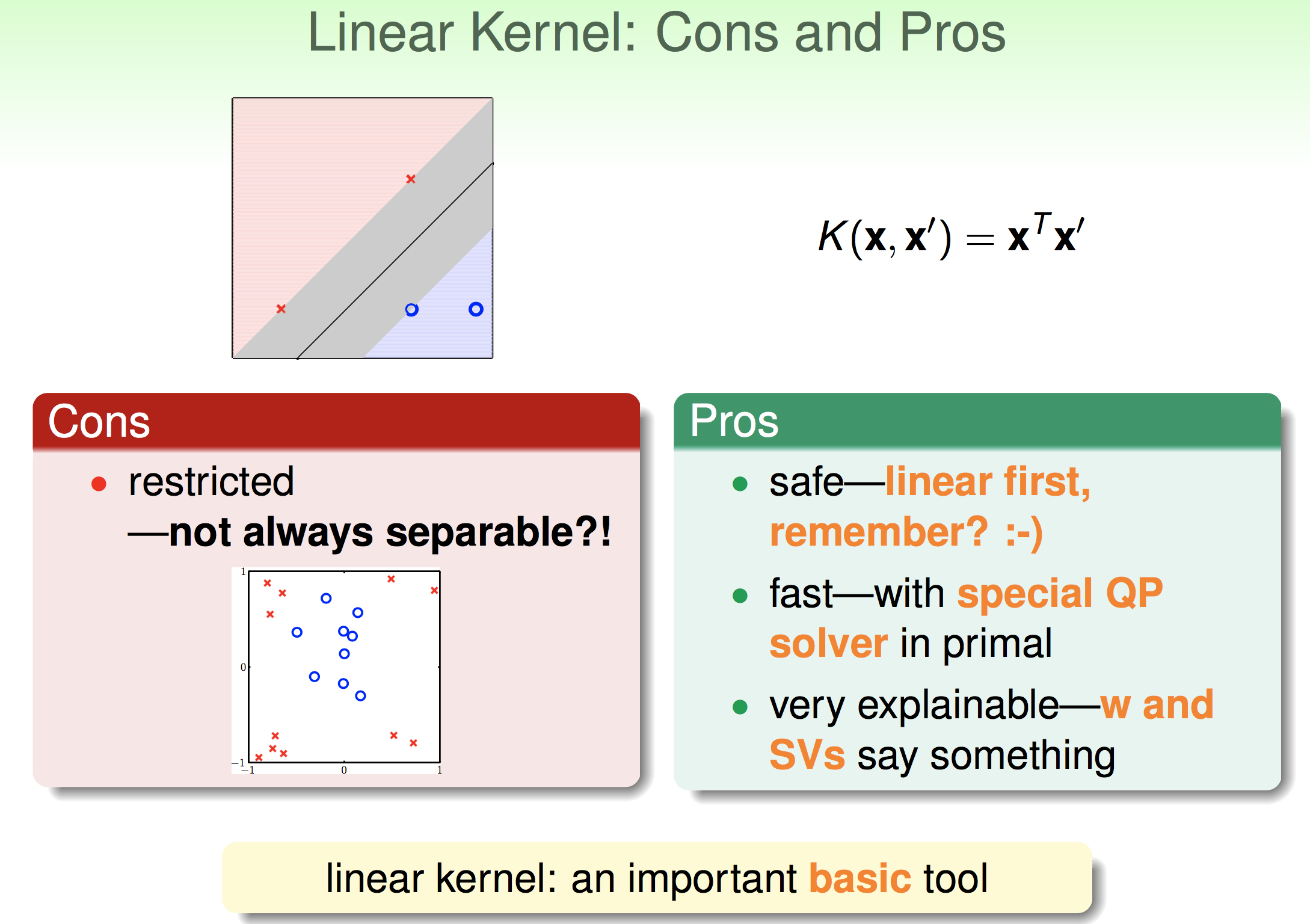


《机器学习技法》---核型SVM的更多相关文章
- Coursera台大机器学习技法课程笔记01-linear hard SVM
极其淡腾的一学期终于过去了,暑假打算学下台大的这门机器学习技法. 第一课是对SVM的介绍,虽然之前也学过,但听了一次感觉还是很有收获的.这位博主总结了个大概,具体细节还是 要听课:http://www ...
- 《机器学习技法》---线性SVM
(本文内容和图片来自林轩田老师<机器学习技法>) 1. 线性SVM的推导 1.1 形象理解为什么要使用间隔最大化 容忍更多的测量误差,更加的robust.间隔越大,噪声容忍度越大: 1.2 ...
- 机器学习技法笔记(2)-Linear SVM
从这一节开始学习机器学习技法课程中的SVM, 这一节主要介绍标准形式的SVM: Linear SVM 引入SVM 首先回顾Percentron Learning Algrithm(感知器算法PLA)是 ...
- 核型SVM
(本文内容和图片来自林轩田老师<机器学习技法>) 1. 核技巧引入 如果要用SVM来做非线性的分类,我们采用的方法是将原来的特征空间映射到另一个更高维的空间,在这个更高维的空间做线性的SV ...
- 机器学习技法课之Aggregation模型
Courses上台湾大学林轩田老师的机器学习技法课之Aggregation 模型学习笔记. 混合(blending) 本笔记是Course上台湾大学林轩田老师的<机器学习技法课>的学习笔记 ...
- 机器学习技法之Aggregation方法总结:Blending、Learning(Bagging、AdaBoost、Decision Tree)及其aggregation of aggregation
本文主要基于台大林轩田老师的机器学习技法课程中关于使用融合(aggregation)方法获得更好性能的g的一个总结.包含从静态的融合方法blending(已经有了一堆的g,通过uniform:voti ...
- 机器学习——支持向量机(SVM)
机器学习--支持向量机(SVM) 支持向量机(Support Vector Machine)广泛地应用于分类问题,回归问题和异常检测问题.支持向量机一个很好的性质是其与凸优化问题相对应,局部最优解就是 ...
- 遵循统一的机器学习框架理解SVM
遵循统一的机器学习框架理解SVM 一.前言 我的博客仅记录我的观点和思考过程.欢迎大家指出我思考的盲点,更希望大家能有自己的理解. 本文参考了李宏毅教授讲解SVM的课程和李航大大的统计学习方法. 二. ...
- Python机器学习笔记:SVM(1)——SVM概述
前言 整理SVM(support vector machine)的笔记是一个非常麻烦的事情,一方面这个东西本来就不好理解,要深入学习需要花费大量的时间和精力,另一方面我本身也是个初学者,整理起来难免思 ...
随机推荐
- c++学习书籍推荐《C++程序设计语言(特别版)》下载
百度云及其他网盘下载地址:点我 编辑推荐 <C++程序设计语言(特别版•十周年中文纪念版)>编辑推荐:十周年纪念版,体味C++语言的精妙与魅力,享受与大师的心灵对话.1979年,Biarn ...
- 如何编写无须人工干预的shell脚本
在使用基本的一些shell命令时,机器需要与人进行互动来确定命令的执行.比如 cp test.txt boo/test.txt,会询问是否覆盖?ssh远程登陆时,需要输入人工密码后,才可以继续执行ss ...
- [Poi2012]Festival 题解
[Poi2012]Festival 时间限制: 1 Sec 内存限制: 64 MB 题目描述 有n个正整数X1,X2,...,Xn,再给出m1+m2个限制条件,限制分为两类: 1. 给出a,b (1 ...
- 程序员要搞明白CDN,这篇应该够了
最近在了解边缘计算,发现我们经常听说的CDN也是边缘计算里的一部分.那么说到CDN,好像只知道它中文叫做内容分发网络.那么具体CDN的原理是什么?能够为用户在浏览网站时带来什么好处呢?解决这两个问题是 ...
- C程序疑问解答 ——可怕的野指针
本篇为原创,禁止任何形式的他用! 一.疑问点 指针是C语言一个很强大的功能,同时也是很容易让人犯错的一个功能,用错了指针,轻者只是报个错,重者可能整个系统都崩溃了.下面是大家在编写C程 ...
- ServiceFabric极简文档-1.3删除群集
删除群集 若要删除群集,请运行包文件夹中的 RemoveServiceFabricCluster.ps1 Powershell 脚本,并传入 JSON 配置文件的路径. 可以选择性地指定删除日志的位置 ...
- weblogic10.3.6重置/修改控制台账号密码
weblogic部署服务后由于交接过程中文档不完整导致有一个域的控制台账号密码遗失, 在此整理记录一下重置控制台账号密码的过程: 注:%DOMAIN_HOME%:指WebLogic Server 域( ...
- 个人永久性免费-Excel催化剂功能第76波-图表序列信息维护
在之前开发过的图表小功能中,可以让普通用户瞬间拥有高级图表玩家所制作的精美图表,但若将这些示例数据的图表转换为自己实际所要的真实数据过程中,仍然有些困难,此篇推出后,再次拉低图表制作门槛,让真实的数据 ...
- Js中关于内部方法、实例方法、原型方法、静态方法的个人见解。
function foo(name){ this.name=name; // 实例方法 this.GetName=function(){ console.log("my name is &q ...
- md文档的书写《三》
markdown语法 官网 这是标题 "#加空格" 是标题,通常可以设置六级标题. 内容下 空格是换行 列表 无序列表:使用" - + * "任何一种加空格都可 ...