Spring Cloud Ribbon---微服务调用和客户端负载均衡
前面分析了Eureka的使用,作为服务注册中心,Eureka 分为 Server 端和 Client 端,Client 端作为服务的提供者,将自己注册到 Server 端,Client端高可用的方式是使用多机部署然后注册到Server,Server端为了保证服务的高可用,也可以使用多机部署的方式。前面简单搭建了Eureka Client 和 Server,然后将Client成功注册到 Server,本节我们将来看看如何调用Eureka服务,在多机部署情况下如何保证负载均衡。Spring Cloud 提供了一个组件:Ribbon。
Ribbon是客户端负载均衡器,可以对HTTP和TCP客户端的行为进行大量控制。Ribbon中的中心概念是指定客户端的概念。
关于服务的负载均衡,硬要是分的话可以分两种:
- 服务端负载均衡。将多个服务注册到一个公共的注册中心,服务调用者访问注册中心,由注册中心提供服务的负载均衡。
- 客户端负载均衡。将多个服务注册到一个注册中心,注册中心维护一个注册表,如果有另一个服务想要调用这个服务,那么访问注册中心即可,注册中心返回注册表信息给服务端,服务端通过特定的平衡算法来决定要调用注册表中的哪个提供者。
服务端负载均衡:

客户端负载均衡:
服务端负载均衡的代表性例子就是nginx,LVS。那么客户端的负载均衡就是我们要说的Ribbon。Ribbon主要提供客户端负载平衡算法,除此之外,Ribbon还提供:
- 服务发现集成 :功能区负载平衡器在动态环境(如云)中提供服务发现。功能区库中包含与Eureka和Netflix服务发现组件的集成;
- 容错 : Ribbon API可以动态确定服务器是否已在实时环境中启动并运行,并且可以检测到那些已关闭的服务器;
- 可配置的负载平衡规则 : Ribbon支持开箱即用的RoundRobinRule,AvailabilityFilteringRule,WeightedResponseTimeRule,还支持定义自定义规则。
Ribbon API提供以下组件供我们使用:
- Rule :定义负载均衡策略;
- Ping : 定义如何ping目标服务实例来判断是否存活, ribbon使用单独的线程每隔一段时间(默认10s)对本地缓存的ServerList做一次检查;
- ServerList :定义如何获取服务实例列表. 两种实现基于配置的
ConfigurationBasedServerList和基于Eureka服务发现的DiscoveryEnabledNIWSServerList; - ServerListFilter: 用来使用期望的特征过滤静态配置动态获得的候选服务实例列表. 若未提供, 默认使用
ZoneAffinityServerListFilter; - ILoadBalancer: 定义了软负载均衡器的操作的接口. 一个典型的负载均衡器至少需要一组用来做负载均衡的服务实例, 一个标记某个服务实例不在旋转中的方法, 和对应的方法调用从实例列表中选出某一个服务实例;
- ServerListUpdater: DynamicServerListLoadBalancer用来更新实例列表的策略(推
EurekaNotificationServerListUpdater/拉PollingServerListUpdater, 默认是拉)
配置服务策略
全局策略设置
使用以下方式配置的策略表示对该项目中调用的所有服务生效。
@Configuration
public class MyConfiguration{
@Bean
public IRule ribbonRule(){
return new RandomRule();
}
//定义一个负载均衡的RestTemplate
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
上面的配置表示:
- 定义了一个随机方式的服务调用方式,即随即调用某个服务的提供者;
- 定义一个负载均衡的 RestTemplate,使用了 @LoadBalanced注解,该注解配合覆盖均衡策略一起使用 RestTemplate 发出的请求才能生效。
RestTemplate是 Spring 提供的用于访问Rest服务的客户端模板工具集,Ribbon并没有创建新轮子,基于此通过负载均衡配置发出HTTP请求。
ribbon的负载均衡策略主要包括以下几种:
| 策略类 | 命名 | 描述 |
|---|---|---|
| RandomRule | 随机策略 | 随机选择server |
| RoundRobinRule | 轮询策略 | 按顺序选择server |
| RetryRule | 重试策略 | 在一个配置时间段内当选择的server不成功,则继续轮训,一直尝试选择一个可用的server |
| BestAvailableRule | 最低并发策略 | 先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务。 |
| AvailabilityFilteringRule | 可用过滤策略 | 先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,以及并发连接数超过阈值的服务,剩下的服务,使用轮询策略 |
| ResponseTimeWeightedRule | 响应时间加权策略 | 根据server的响应时间分配权重。响应时间越长,权重越低,被选择到的概略就越低,权重越高,被选择到的概率就越高 |
| ZoneAvoidanceRule | 区域权衡策略 | 综合判断server所在的区域的性能和server的可用性轮询选择server,并且判定一个AWS Zobe的运行性能是否可用,提出不可用的Zone中所有server |
局部策略设置
如果在项目中你想对某些服务使用指定的负载均衡策略,那么可以如下配置:
@Configuration
@RibbonClients({
@RibbonClient(name = "user-service",configuration = UserServiceConfig.class),
@RibbonClient(name = "order-service",configuration = OrderServiceConfig.class)
})
public class RibbonConfig {
}
@RibbonClients 中可以包含多个@RibbonClient。每个@RibbonClient表示一个服务名,后面对应的类表示该服务配套的策略规则。
如果你只想对一个服务应用某种规则,那么可以省略:@RibbonClients:
@Configuration
@RibbonClient(name = "order-service",configuration = OrderServiceConfig.class)
public class RibbonConfig {
}
超时重试
HTTP请求不免的会有网络不好的情况出现超时,Ribbon提供了超时重试机制,提供如下参数可以设置:
ribbon-client:
ribbon:
ConnectTimeout: 3000
ReadTimeout: 60000
MaxAutoRetries: 1 #对第一次请求的服务的重试次数
MaxAutoRetriesNextServer: 1 #要重试的下一个服务的最大数量(不包括第一个服务)
OkToRetryOnAllOperations: true
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
饥饿加载
Ribbon在进行客户端负载均衡的时候并不是在启动的时候就加载上下文的,实在实际请求的时候才加载,有点像servlet的第一次请求的时候才去生成实例,这回导致第一次请求会比较的缓慢,甚至可能会出现超时的情况。所以我们可以指定具体的客户端名称来开启饥饿加载,即在启动的时候便加载素养的配置项的应用上下文。
ribbon:
eager-load:
enabled: true
clients: ribbon-client-1, ribbon-client-2, ribbon-client-3
Ribbon负载均衡示例
下面看一下整合Eureka 和 Ribbon如何实现服务调用 和 负载均衡。有了Eureka之后,服务调用就无需关注服务提供者的IP。
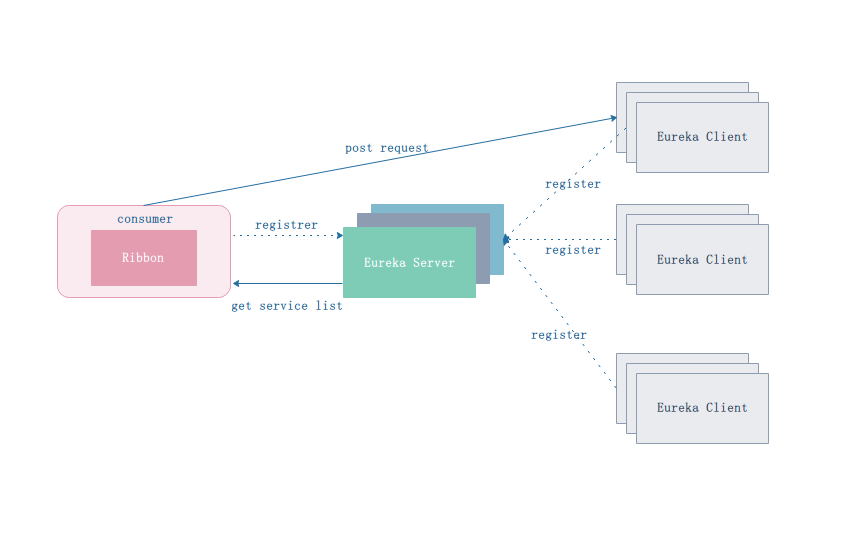
服务的整体流程如上图,一个集成了Ribbon的Eureka Client 从Eureka Server中获取服务,首先拉取服务list,然后Ribbon服务会根据配置的负载均衡策略选取合适的服务提供者,向该提供者发送请求获取结果。
工程结构如下:

一个 Eureka Server,3个Eureka Client,一个集成了Ribbon 的Consumer。整体代码我就不贴了,已经上传至GitHub自行下载。Demo 工程见这里:
简单说一下关于 Ribbon consumer的配置:
pom文件中需要引入关于Ribbon的包,同时consumer也是一个Eureka Client要去拉 Eureka Server的配置,所以需要Eureka client的包。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
在启动类中初始化了两个bean:
import com.netflix.loadbalancer.IRule;
import com.netflix.loadbalancer.RandomRule;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@EnableDiscoveryClient
@SpringBootApplication
public class RibbonDemoApplication {
public static void main(String[] args) {
SpringApplication.run(RibbonDemoApplication.class, args);
}
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
@Bean
public IRule ribbonRule() {
return new RandomRule();//这里配置策略,和配置文件对应
}
}
RestTemplate 和 IRule负载均衡策略。
然后就可以使用已经配置了负载均衡的 RestTemplate 发起请求了:
@Service
public class DemoService {
@Autowired
RestTemplate restTemplate;
public String hello(String name) {
return restTemplate.getForEntity("http://eureka-client/hello/" + name, String.class).getBody();
}
}
大家自行下载Demo工程进行调试。
Spring Cloud Ribbon---微服务调用和客户端负载均衡的更多相关文章
- 微服务调用之feign负载均衡及服务降级
一,负载均衡: feign已经集成了ribbon,将service1,service2在不同端口启动多个实例可以自动负载均衡 idea: application.yml中server.port: ${ ...
- 利用Spring Cloud实现微服务- 熔断机制
1. 熔断机制介绍 在介绍熔断机制之前,我们需要了解微服务的雪崩效应.在微服务架构中,微服务是完成一个单一的业务功能,这样做的好处是可以做到解耦,每个微服务可以独立演进.但是,一个应用可能会有多个微服 ...
- Spring Cloud构建微服务架构(一)服务注册与发现
Spring Cloud简介 Spring Cloud是一个基于Spring Boot实现的云应用开发工具,它为基于JVM的云应用开发中的配置管理.服务发现.断路器.智能路由.微代理.控制总线.全局锁 ...
- Spring Cloud构建微服务架构(二)服务消费者
Netflix Ribbon is an Inter Process Communication (IPC) cloud library. Ribbon primarily provides clie ...
- Spring Cloud构建微服务架构(五)服务网关
通过之前几篇Spring Cloud中几个核心组件的介绍,我们已经可以构建一个简略的(不够完善)微服务架构了.比如下图所示: 我们使用Spring Cloud Netflix中的Eureka实现了服务 ...
- Spring Cloud构建微服务架构 - 服务网关
通过之前几篇Spring Cloud中几个核心组件的介绍,我们已经可以构建一个简略的(不够完善)微服务架构了.比如下图所示: alt 我们使用Spring Cloud Netflix中的Eureka实 ...
- 基于Spring Cloud的微服务入门教程
(本教程的原地址发布在本人的简书上:http://www.jianshu.com/p/947d57d042e7,若各位看官有什么问题或不同看法请在这里或简书留言,谢谢!) 本人也是前段时间才开始接触S ...
- 干货|基于 Spring Cloud 的微服务落地
转自 微服务架构模式的核心在于如何识别服务的边界,设计出合理的微服务.但如果要将微服务架构运用到生产项目上,并且能够发挥该架构模式的重要作用,则需要微服务框架的支持. 在Java生态圈,目前使用较多的 ...
- 基于Spring Cloud的微服务落地
微服务架构模式的核心在于如何识别服务的边界,设计出合理的微服务.但如果要将微服务架构运用到生产项目上,并且能够发挥该架构模式的重要作用,则需要微服务框架的支持. 在Java生态圈,目前使用较多的微服务 ...
随机推荐
- python关于try except的使用方法
一.常见错误总结 AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x IOError 输入/输出异常;基本上是无法打开文件 ImportError 无法引入 ...
- ABAP开发环境语法高亮的那些事儿
关于SAP ABAP开发环境,Jerry之前写过几篇公众号文章: 那些年我用过的SAP IDE 不喜欢SAP GUI?那试试用Eclipse进行ABAP开发吧 使用Visual Studio Code ...
- wokerman随笔
linux环境检查是否满足workerman要求: curl -Ss http://www.workerman.net/check.php | php workerman依赖扩展:pcntl扩展.po ...
- leetcode 学习心得 (1) (24~300)
源代码地址:https://github.com/hopebo/hopelee 语言:C++ 24.Swap Nodes in Pairs Given a linked list, swap ever ...
- Linux命令——gdisk、fdisk、partprobe
gdisk.fdisk MBR分区表请使用fdisk分区,GPT分区表请使用gdisk分区 MBR与GPT区别参考:Linux磁盘管理——MBR 与 GPT gdisk.gdisk这两个命令参数不需要 ...
- 快速部署ldap服务
快速部署ldap服务 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.LDAP概述 .什么是目录服务 ()目录是一类为了浏览和搜索数据二十几的特殊的数据库,例如:最知名的的微软公 ...
- django 项目需要注意的一些点
1.创建新项目 把静态文件夹的名字放在settings文件里面 STATIC_URL = '/static/' STATICFILES_DIRS=[ os.path.join(BASE_DIR, ...
- 深入详解JVM内存模型
JVM内存结构 由上图可以清楚的看到JVM的内存空间分为3大部分: 堆内存 方法区 栈内存 其中栈内存可以再细分为java虚拟机栈和本地方法栈,堆内存可以划分为新生代和老年代,新生代中还可以再次划分为 ...
- 51nod1463 找朋友
[传送门] 写的时候一直没有想到离线解法,反而想到两个比较有趣的解法.一是分块,$f[i][j]$表示第$i$块块首元素到第$j$个元素之间满足条件的最大值(即对$B_l + B_r \in K$的$ ...
- ML.NET 笔记
ROC曲线 ROC空间将偽陽性率(FPR)定義為 X 軸,真陽性率(TPR)定义为 Y 轴. TPR:在所有實際為陽性的樣本中,被正確地判斷為陽性之比率. FPR:在所有實際為阴性的样本中,被錯誤地判 ...