VQA视觉问答基础知识
本文记录简单了解VQA的过程,目的是以此学习图像和文本的特征预处理、嵌入以及如何设计分类loss等等.
参考资料:
https://zhuanlan.zhihu.com/p/40704719
https://www.youtube.com/watch?v=ElZADFTer4I
https://www.youtube.com/watch?v=cgOmpgcELPQ https://tryolabs.com/blog/2018/03/01/introduction-to-visual-question-answering/
https://tryolabs.com/blog/2018/03/01/introduction-to-visual-question-answering/
VQA定义:
给定一张图像和一个相关文字问题,从若干候选文字回答中选出正确答案.
常用策略是CNN提取图像特征,RNN提取文本特征,将图像特征和文本特征进行融合,然后通过全连接层进行分类.关键在于如何融合这两个模态.
Visual Question Answering (VQA) by Devi Parikh
Why Words and Pictures?
Applications.应用场景很广.
Measuring and demonstrating AI capabilities.通过对image和language的理解,衡量并展现AI的能力.
Beyond “bucket” recognition.跳出通常的对于AI任务的分类.
Image captions即为图片加上文字描述,可能存在的问题是,文字描述太过通用,无法详细地描绘出图像中的细节.
构建VQA:
创建数据集,包括coco数据集中的254721张图片、50000张卡通,从Amazon Mechanical Turk为每张图片收集3个问题,每个问题收集10个回答.
38%的问题是binary yes/no, 99%的问题有着<=3个单词的答案.这使得评估变得可行.
Input: image和question Output: answer.
Image用CNN, Question用RNN和LSTM, 输出是1 of K个最可能的答案.
What such a model can‘t do?
例如“pizza box中剩下了几片菜叶子“的问题.因为该模型不具有计数的功能,
Introduction to Visual Question Answering: Datasets, Approaches and Evaluation
A multi-discipline problem:
VQA是跨学科的,至少需要NLP、CV、Knowledge Representation & Resoning等知识.
Available datasets:
好的datasets结合恰当的评估方法是解决许多问题的关键.
VQA非常复杂,因此一个好的dataset要足够大,能包含尽可能多种类的图片和问题.许多datasets从COCO(Microsoft Common Objects in Context)数据集中获取图片.
COCO数据集大大简化和加速了VQA dataset的构建过程,但仍存在问题.例如收集广泛的、恰当的、没有歧义的probelm,以及可能被利用的biases.
The DAQUAR dataset是第一个重要的VQA dataset.全称是DAtaset for QUestion Answering on Real-world images.它的图片基于NYU-Depth V2 Dataset, 包含6974个training问答和5674个testing问答.它的缺点是只包含了室内图像,并且光照条件使得很难回答问题.
The COCO-QA dataset包含123287张图片, 78736个training问答和38948testing问答.值得注意的是它的所有答案都是一个单词.缺点是由于问题是由nlp生成的,因此存在一些奇怪的内容,并且只包含目标、颜色、计数和定位的问题.
The VQA dataset包含204721张COCO中的图片和50000张卡通图片.每个图片对应3个问题,每个问题对应10个答案.
Current Approaches:
VQA所需要的方法大致是:从问题中抽取特征、从图片中抽取特征、将两种特征结合来生成答案.
对于text features,有BoW, LSTM encoders等方法.
对于image features, 有pre-trained CNNs on ImageNet是最常用的.对于Answer, 模型一般会将问题视作一个分类任务.
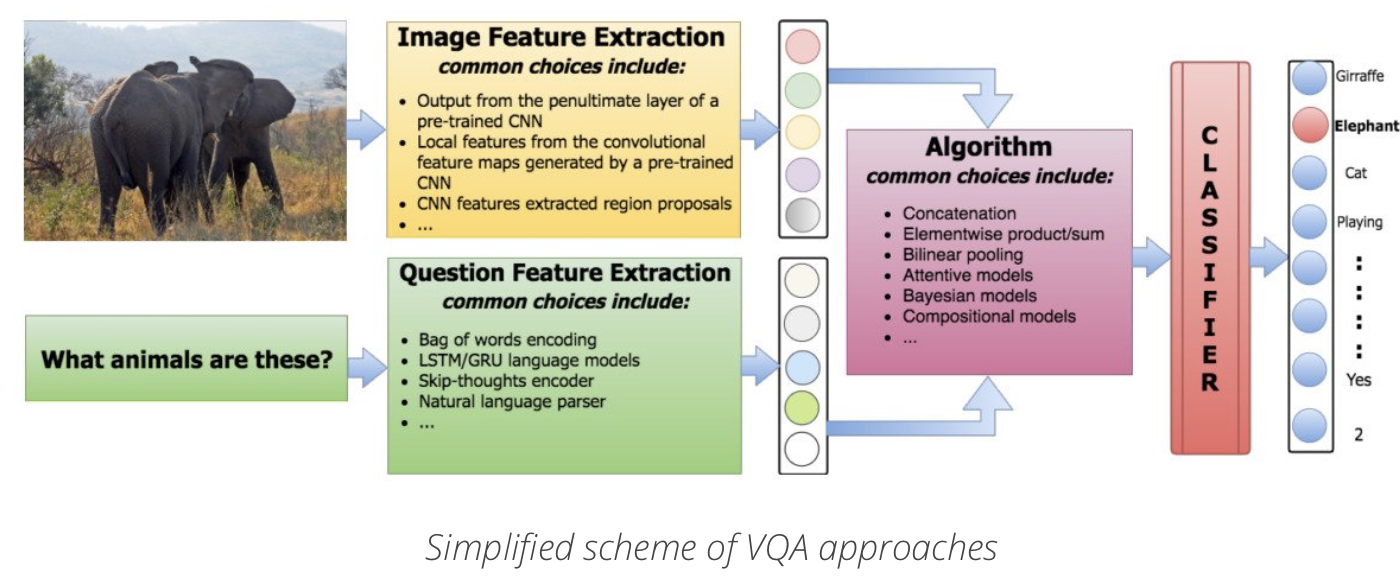
不同方法的主要区别就是如何结合textual and image features.
一个不好的baseline很可能会给出最频繁出现的答案,或者是随机挑选答案.因此baseline的设计很关键.比较常用的方法是训练一个线性分类器或是网络,将features作为input.
Attention-based approaches是让算法专注于最相关的部分.例如“What color is the ball”的关键词就是“color”和“ball”,图像也会认为ball是最重要的一块区域.应用在VQA中,一般会使用spatial attention来生成区域特定特征,用于训练CNN.
Bayesian approaches的思想是对于问题和图像特征中同时出现的数据进行建模,作为一种推理关系的方式.
Evaluation metrics:
传统的classic accuracy对于有选项的回答系统不错,但是对于开放式回答系统起不到作用.
WUPS估计一个回答和标准答案的语义距离,结果在0和1之间.使用WorldNet来计算语义树中的距离,从而衡量相似性.另外还会将相似性较低的答案的得分额外下降.缺点是太依赖WorldNet.
VQA视觉问答基础知识的更多相关文章
- CSS基础知识—【结构、层叠、视觉格式化】
结构和层叠 选择器的优先级顺序: style[内联元素]选择器>Id选择器>类选择器 属性选择器>元素选择器>通配器选择器 重要性:@important 有这个标记的属性值,优 ...
- 【论文小综】基于外部知识的VQA(视觉问答)
我们生活在一个多模态的世界中.视觉的捕捉与理解,知识的学习与感知,语言的交流与表达,诸多方面的信息促进着我们对于世界的认知.作为多模态领域的一个典型场景,VQA旨在结合视觉的信息来回答所提出的问题 ...
- 【自然语言处理】--视觉问答(Visual Question Answering,VQA)从初始到应用
一.前述 视觉问答(Visual Question Answering,VQA),是一种涉及计算机视觉和自然语言处理的学习任务.这一任务的定义如下: A VQA system takes as inp ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- JavaSE 基础知识(常识概念 + 基础语法)问答总结/面试题 —— 讲给应届生的 Java 开源知识项目
写在最前面 这个项目是从20年末就立好的 flag,经过几年的学习,回过头再去看很多知识点又有新的理解.所以趁着找实习的准备,结合以前的学习储备,创建一个主要针对应届生和初学者的 Java 开源知识项 ...
- java中文乱码解决之道(二)-----字符编码详解:基础知识 + ASCII + GB**
在上篇博文(java中文乱码解决之道(一)-----认识字符集)中,LZ简单介绍了主流的字符编码,对各种编码都是点到为止,以下LZ将详细阐述字符集.字符编码等基础知识和ASCII.GB的详情. 一.基 ...
- WCF入门教程:WCF基础知识问与答(转)
学习WCF已有近两年的时间,其间又翻译了Juval的大作<Programming WCF Services>,我仍然觉得WCF还有更多的内容值得探索与挖掘.学得越多,反而越发觉得自己所知太 ...
- WPF Step By Step -基础知识介绍
回顾 上一篇我们介绍了WPF基本的知识.并且介绍了WPF与winform传统的cs桌面应用编程模式上的变化,这篇,我们将会对WPF的一些基础的知识做一个简单的介绍,关于这些基础知识更深入的应用则在后续 ...
- java中文乱码解决之道(二)—–字符编码详解:基础知识 + ASCII + GB**
原文出处:http://cmsblogs.com/?p=1412 在上篇博文(java中文乱码解决之道(一)—–认识字符集)中,LZ简单介绍了主流的字符编码,对各种编码都是点到为止,以下LZ将详细阐述 ...
随机推荐
- 在linux上安装taiga
# taiga 安装配置 1.简介 本文档介绍了如何部署完整的Taiga服务(每个模块都是Taiga平台的一部分). Taiga平台由三个主要组件组成,每个组件在编译时和运行时都有自己的依赖关系: t ...
- bean的shutdown
使用@Bean注解,在不配置destroyMethod时,其默认值为: String destroyMethod() default AbstractBeanDefinition.INFER_METH ...
- SSM基本依赖及配置
需要了解具体配置文件的作用到:SSM基本配置详解 示例项目:SSMDemo 依赖 基本依赖 <properties> <spring.version>5.0.6.RELEASE ...
- java8时间处理实例
实例: package com.javaBase.time; import java.time.Clock; import java.time.LocalDate; import java.time. ...
- jQuery.form 上传文件
今年大部分是都在完善产品,这几天遇到了一个问题,原来的flash组件不支持苹果浏览器,需要改.在网上搜了下,看到一个jQuery.form插件可以上传文件,并且兼容性很好,主要浏览器大部分都兼容,插件 ...
- 搜索引擎elasticsearch监控利器cat命令
目录 一.Cat通用参数 二.cat命令 三.示例 查询aurajike索引下的总文档数和有效文档数 查询aurajike各分片的调度情况 一.Cat通用参数 参数名 指令示例 功能 Verbose ...
- js生成一定范围内的随机整数
Math.floor(Math.random()*(m-n+1)+n) Math.floor(Math.random() * (50 - 1 + 1) + 1): 生成1-50内的随机整数
- 学习笔记之UML ( Unified Modeling Language )
Unified Modeling Language - Wikipedia https://en.wikipedia.org/wiki/Unified_Modeling_Language The Un ...
- html基础简介
一.html概念 1.定义:(Hyper Text Markup Language)超文本标记语言,主要是通过html标记对网页中的文本,图片,声音等内容进行描述,同时也可以在文本中包含“超级链接”, ...
- 【数据库】数据库入门(四): SQL查询 - SELETE的进阶使用
集合操作常用的集合操作主要有三种:UNION(联合集).INTERSECT(交叉集).EXCEPT(求差集).以上三种集合的操作都是直接作用在两个或者多个 SQL 查询语句之间,将所有的元组按照特定的 ...