【自然语言处理】--视觉问答(Visual Question Answering,VQA)从初始到应用
一、前述
视觉问答(Visual Question Answering,VQA),是一种涉及计算机视觉和自然语言处理的学习任务。这一任务的定义如下: A VQA system takes as input an image and a free-form, open-ended, natural-language question about the image and produces a natural-language answer as the output[1]。 翻译为中文:一个VQA系统以一张图片和一个关于这张图片形式自由、开放式的自然语言问题作为输入,以生成一条自然语言答案作为输出。简单来说,VQA就是给定的图片进行问答。
VQA系统需要将图片和问题作为输入,结合这两部分信息,产生一条人类语言作为输出。针对一张特定的图片,如果想要机器以自然语言来回答关于该图片的某一个特定问题,我们需要让机器对图片的内容、问题的含义和意图以及相关的常识有一定的理解。VQA涉及到多方面的AI技术(图1):细粒度识别(这位女士是白种人吗?)、 物体识别(图中有几个香蕉?)、行为识别(这位女士在哭吗?)和对问题所包含文本的理解(NLP)。综上所述,VQA是一项涉及了计算机视觉(CV)和自然语言处理(NLP)两大领域的学习任务。它的主要目标就是让计算机根据输入的图片和问题输出一个符合自然语言规则且内容合理的答案。
二、具体步骤
2.1 第一步,生成答案
2.2 第二步,处理输⼊源数据
2.2.1 处理输⼊源数据:图⽚
卷积CNN结合VGG-16模型
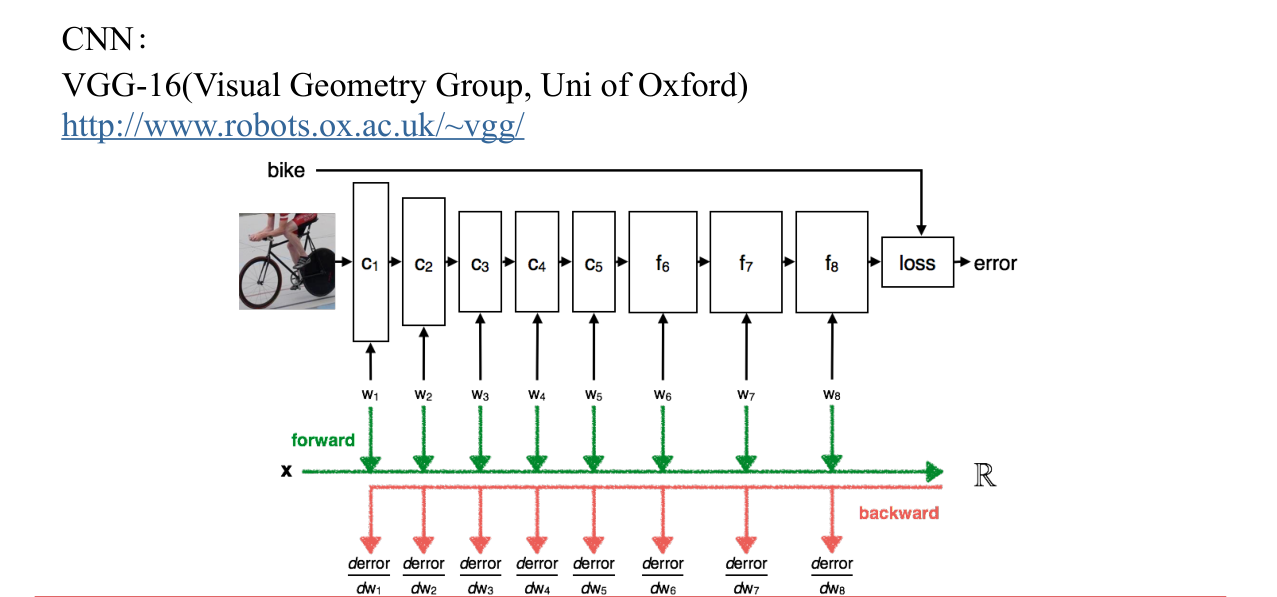
VGG-16的标准构造 (keras)
def VGG_16(weights_path=None):
model = Sequential()
model.add(ZeroPadding2D((1,1),input_shape=(3,224,224)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation='softmax'))
if weights_path:
model.load_weights(weights_path)
return model
2.2.2 处理输⼊源数据:⽂字
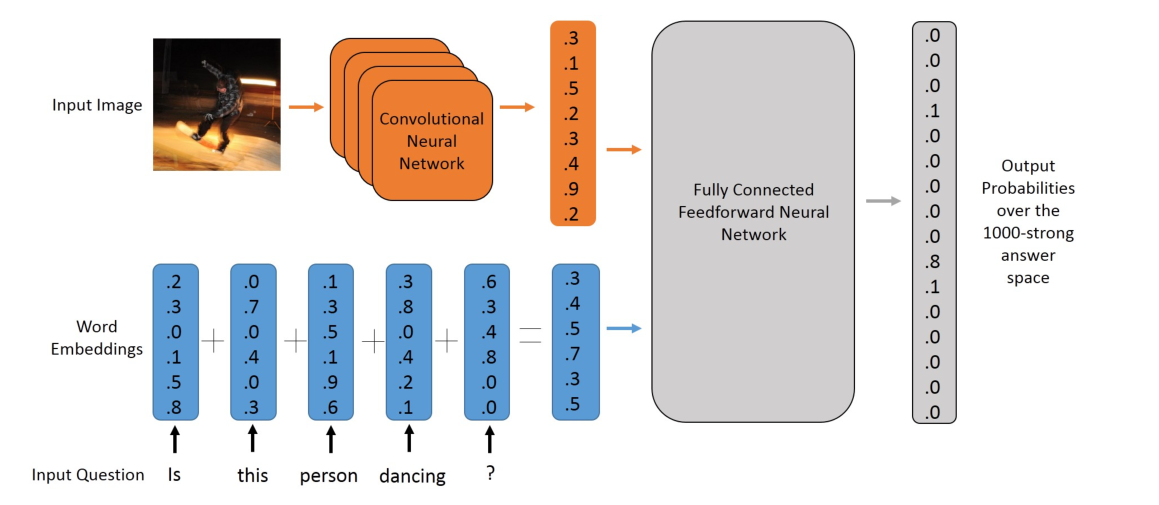
2.3 第三步, 选取VQA模型-MLP
2.3.1 选取VQA模型-MLP
2.3.2 选取VQA模型-LSTM

【自然语言处理】--视觉问答(Visual Question Answering,VQA)从初始到应用的更多相关文章
- Hierarchical Question-Image Co-Attention for Visual Question Answering
Hierarchical Question-Image Co-Attention for Visual Question Answering NIPS 2016 Paper: https://arxi ...
- Visual Question Answering with Memory-Augmented Networks
Visual Question Answering with Memory-Augmented Networks 2018-05-15 20:15:03 Motivation: 虽然 VQA 已经取得 ...
- 第八讲_图像问答Image Question Answering
第八讲_图像问答Image Question Answering 课程结构 图像问答的描述 具备一系列AI能力:细分识别,物体检测,动作识别,常识推理,知识库推理..... 先要根据问题,判断什么任务 ...
- 论文笔记:Visual Question Answering as a Meta Learning Task
Visual Question Answering as a Meta Learning Task ECCV 2018 2018-09-13 19:58:08 Paper: http://openac ...
- 论文阅读:Learning Visual Question Answering by Bootstrapping Hard Attention
Learning Visual Question Answering by Bootstrapping Hard Attention Google DeepMind ECCV-2018 2018 ...
- Learning Conditioned Graph Structures for Interpretable Visual Question Answering
Learning Conditioned Graph Structures for Interpretable Visual Question Answering 2019-05-29 00:29:4 ...
- VQA视觉问答基础知识
本文记录简单了解VQA的过程,目的是以此学习图像和文本的特征预处理.嵌入以及如何设计分类loss等等. 参考资料: https://zhuanlan.zhihu.com/p/40704719 http ...
- 论文:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-阅读总结 笔记不能简单的抄写文中 ...
- 【论文小综】基于外部知识的VQA(视觉问答)
我们生活在一个多模态的世界中.视觉的捕捉与理解,知识的学习与感知,语言的交流与表达,诸多方面的信息促进着我们对于世界的认知.作为多模态领域的一个典型场景,VQA旨在结合视觉的信息来回答所提出的问题 ...
随机推荐
- APNS导致消息丢失和发送效率原因
http://blog.csdn.net/tlq1988/article/details/9612237 首先说明一下,本文只是介绍一些容易被开发者忽视,而导致性能低下问题.并不是介绍如何向苹果设备成 ...
- Python Assert 为何不尽如人意
Python中的断言用起来非常简单,你可以在assert后面跟上任意判断条件,如果断言失败则会抛出异常. >>> assert 1 + 1 == 2 >>> ass ...
- TestNG教程网站
比较简明的一些TestNG教程网站 : https://www.jianshu.com/p/74816a200221 http://www.yiibai.com/testng/parameterize ...
- bzoj 4916: 神犇和蒟蒻 (杜教筛+莫比乌斯反演)
题目大意: 读入n. 第一行输出“1”(不带引号). 第二行输出$\sum_{i=1}^n i\phi(i)$. 题解: 所以说那个$\sum\mu$是在开玩笑么=.= 设$f(n)=n\phi(n) ...
- Python Django 1.Hello Django
#安装Djangopip install Django #==版本号#选择路径:D:#任意文件夹名 cd Django #罗列Django所提供的命令,其中startproject命令来创建项目 dj ...
- vue不是内部或外部命令解决验证方案
一.前提 1.该教程是在你已经安装配置好node.js和express情况下 2.你已经完成了vue和vue-cli的全局安装 3.完成以上2步后,使用vue指令,会显示"vue不是内部或外 ...
- C# 指定父層級目錄
lstrcatW(pszpath, "\\..\\..\\"); DWORD dwlen = GetFullPathNameW(pszpath, 0u, null, null); ...
- OsharpNS轻量级.net core快速开发框架简明入门教程-代码生成器的使用
OsharpNS轻量级.net core快速开发框架简明入门教程 教程目录 从零开始启动Osharp 1.1. 使用OsharpNS项目模板创建项目 1.2. 配置数据库连接串并启动项目 1.3. O ...
- mpvue 小程序开发爬坑汇总
<!-- 小程序的爬坑记录 --> 1 微信小程序之动态获取元素宽高 var obj=wx.createSelectorQuery(); 2 微信小程序图片自适应 <image cl ...
- 第一课《.net之--泛型》
今天我来学习泛型,泛型是编程入门学习的基础类型,从.net诞生2.0开始就出现了泛型,今天我们开始学习泛型的语法和使用. 什么是泛型? 泛型(generic)是C#语言2.0和通用语言运行时(CLR) ...