查询接口---flask+python+mysql
环境准备
安装flask
pip install flask
项目结构如图
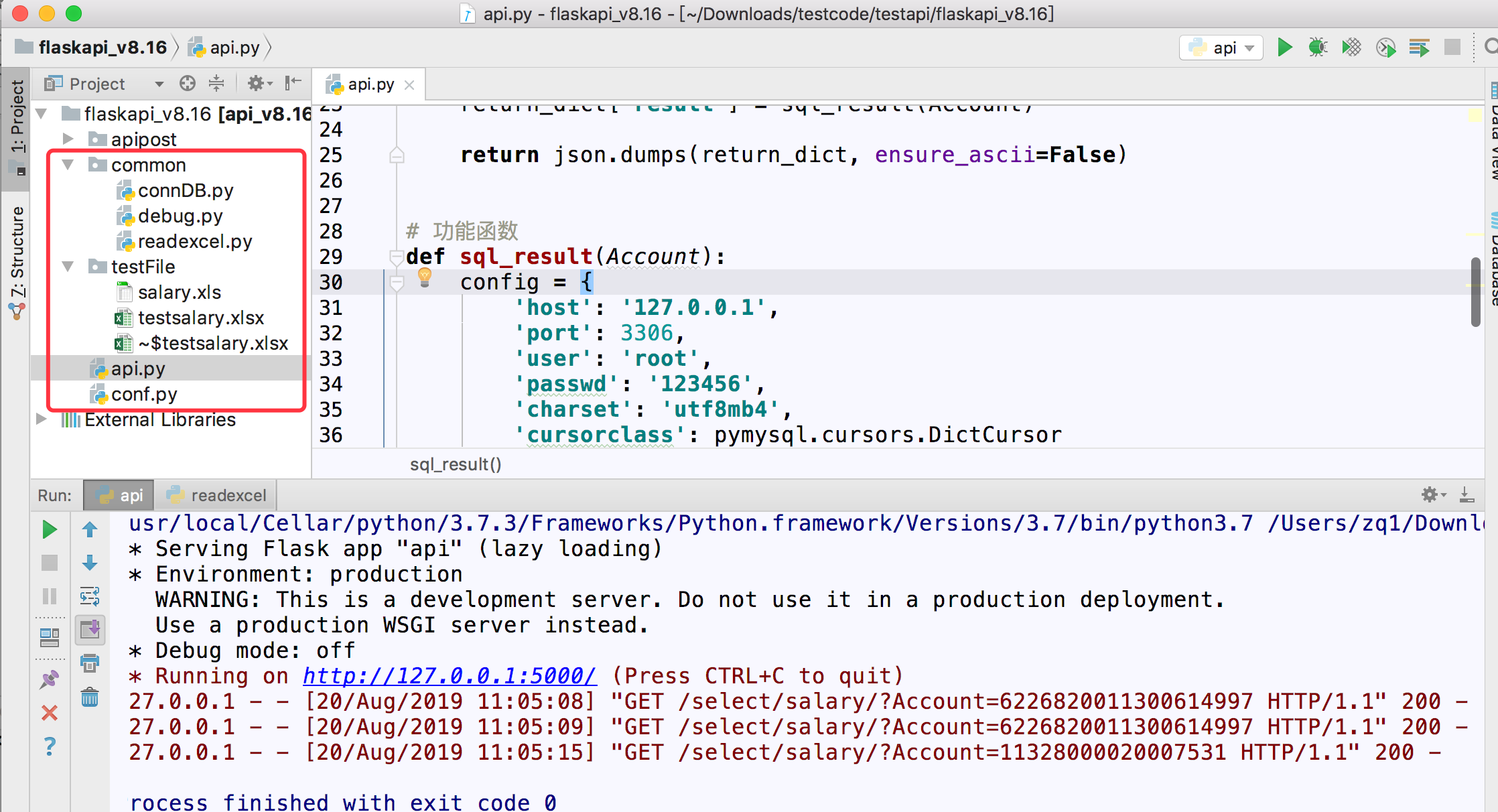
1.新建配置文件conf.py
#!/usr/bin/python
# -*- coding:utf-8 -*- import pymysql,os # ============================ Global parameter ==============================
proDir = os.path.split(os.path.realpath(__file__))[0]
print(proDir)
xlsPath = os.path.join(proDir, 'testFile')
#============================ DB Config ============================== config = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'passwd': 'pwd',
'charset': 'utf8mb4',
'cursorclass': pymysql.cursors.DictCursor
}
2.新建目录testFile,将excel表格放到此目录下
3.原始数据处理,excel表数据导入mysql库
新建readexcel.py,读取excel数据,返回格式为[(1,2,3),(3,4,5)]
import xlrd
from conf import xlsPath
class ExcelUtil():
'''
返回格式为[(1,2,3),(3,4,5)]
'''
def __init__(self, excelPath, sheetIndex=0):
self.data = xlrd.open_workbook(excelPath)
self.table = self.data.sheet_by_index(sheetIndex)
# 获取第一行作为key值
self.keys = self.table.row_values(0)
# 获取总行数
self.rowNum = self.table.nrows
# 获取总列数
self.colNum = self.table.ncols def dict_data(self):
r = []
j = 1
for i in list(range(self.rowNum-1)):
values = self.table.row_values(j)
r.append(tuple(values))
j += 1
return r if __name__ == "__main__":
filepath = xlsPath+'/testsalary.xlsx'
sheetIndex = 0
data = ExcelUtil(filepath, sheetIndex).dict_data()
print(data)
4.操作数据库connDB.py,将excel数据批量入库
#!/usr/bin/python
# -*- coding:utf-8 -*- import pymysql
from conf import config
from common.readexcel import ExcelUtil, xlsPath filepath = xlsPath + '/testsalary.xlsx'
sheetIndex = 0
data = ExcelUtil(filepath, sheetIndex).dict_data() def conn_db():
conn = pymysql.connect(**config)
conn.autocommit(1)
cursor = conn.cursor() try:
# 创建数据库
DB_NAME = 'test'
cursor.execute('DROP DATABASE IF EXISTS %s' % DB_NAME)
cursor.execute('CREATE DATABASE IF NOT EXISTS %s ' % DB_NAME)
conn.select_db(DB_NAME) # 创建表
TABLE_NAME = 'user'
cursor.execute(
'CREATE TABLE %s(company varchar(30),Account varchar(30) primary key,'
'name varchar(30), Duties varchar(30), Jobwages varchar(30),'
'Rankwages varchar(30),'
'workyears varchar(30),70percent varchar(30),'
'30percent varchar(30),'
'totoal_wages varchar(30),housing_fund varchar(30),'
'Medical_insurance varchar(30),Pension varchar(30),'
'Career_Annuities varchar(30),Taxes varchar(30),'
'total_Deduction varchar(30),Actual_wages varchar(30))' % TABLE_NAME) # 批量插入纪录
values = []
for i in data:
values.append(i)
cursor.executemany('INSERT INTO user VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)', values)
# 查询数据条
cursor.execute('SELECT * FROM %s' % TABLE_NAME)
print('total records:', cursor.rowcount)
result = cursor.fetchall()
return result except:
import traceback
traceback.print_exc()
# 发生错误时会滚
conn.rollback()
finally:
# 关闭游标连接
cursor.close()
# 关闭数据库连接
conn.close() if __name__ == "__main__":
print(conn_db())
5.数据准备好,开始写接口,新建api.py
from flask import Flask, request
import json
import pymysql
from conf import config app = Flask(__name__) # 只接受get方法访问
@app.route("/select/salary/", methods=["GET"])
def check():
# 默认返回内容
return_dict = {'code': '200', 'msg': '处理成功', 'result': False}
# 判断入参是否为空
if request.args is None:
return_dict['return_code'] = '504'
return_dict['return_info'] = '请求参数为空'
return json.dumps(return_dict, ensure_ascii=False)
# 获取传入的参数
get_data = request.args.to_dict()
Account = get_data.get('Account')
# age = get_data.get('age')
# 对参数进行操作
return_dict['result'] = sql_result(Account) return json.dumps(return_dict, ensure_ascii=False) # 功能函数
def sql_result(Account):
conn = pymysql.connect(**config)
conn.autocommit(1)
conn.select_db('test')
cursor = conn.cursor()
cursor.execute('SELECT * FROM test.user WHERE Account= %s' % Account)
# print('total records:', cursor.rowcount)
result = cursor.fetchall()
conn.close()
return result[0] if __name__ == "__main__":
app.run(host='127.0.0.1',port=5000)
6.浏览器访问
http://127.0.0.1:5000/select/salary/?Account=62268200113006149

查询接口---flask+python+mysql的更多相关文章
- 使用Flask开发简单接口(3)--引入MySQL
前言 前面的两篇文章中,我们已经学习了通过Flask开发GET和POST请求接口,但一直没有实现操作数据库,那么我们今天的目的,就是学习如何将MySQL数据库运用到当前的接口项目中. 本人环境:Pyt ...
- python爬取免费优质IP归属地查询接口
python爬取免费优质IP归属地查询接口 具体不表,我今天要做的工作就是: 需要将数据库中大量ip查询出起归属地 刚开始感觉好简单啊,毕竟只需要从百度找个免费接口然后来个python脚本跑一晚上就o ...
- Python + MySQL 批量查询百度收录
做SEO的同学,经常会遇到几百或几千个站点,然后对于收录情况去做分析的情况 那么多余常用的一些工具在面对几千个站点需要去做收录分析的时候,那么就显得不是很合适. 在此特意分享给大家一个批量查询百度收录 ...
- python mysql 简单总结(MySQLdb模块 需另外下载)
python 通过DB-API规范了它所支持的不同的数据库,使得不同的数据库可以使用统一的接口来访问和操作. 满足DB-API规范的的模块必须提供以下属性: 属性名 描述 apilevel DB-AP ...
- Python MySQL(MySQLdb)
From: http://www.yiibai.com/python/python_mysql.html Python标准的数据库接口的Python DB-API(包括Python操作MySQL).大 ...
- 10分钟教你Python+MySQL数据库操作
欲直接下载代码文件,关注我们的公众号哦!查看历史消息即可! 本文介绍如何利用python来对MySQL数据库进行操作,本文将主要从以下几个方面展开介绍: 1.数据库介绍 2.MySQL数据库安装和设置 ...
- 三、Django学习之单表查询接口
查询接口 all() 查询所有结果,结果是queryset类型 filter(**kwargs) and条件关系:参数用逗号分割表示and关系 models.Student.objects.filte ...
- Python MySQL ORM QuickORM hacking
# coding: utf-8 # # Python MySQL ORM QuickORM hacking # 说明: # 以前仅仅是知道有ORM的存在,但是对ORM这个东西内部工作原理不是很清楚, ...
- python 之路,Day11(上) - python mysql and ORM
python 之路,Day11 - python mysql and ORM 本节内容 数据库介绍 mysql 数据库安装使用 mysql管理 mysql 数据类型 常用mysql命令 创建数据库 ...
随机推荐
- 苹果开发之App签名
如果你的Apple ID账号(可使用邮箱来注册)为Apple developer类型的话,登录之后是看不到Certificates, Indentifiers & Profiles信息的 Ap ...
- 第23课 优先选用make系列函数
一. make系列函数 (一)三个make函数 1. std::make_shared:用于创建shared_ptr.GCC编译器中,其内部是通过调用std::allocate_shared来实现的. ...
- 用欧拉计划学Rust语言(第7~12题)
最近想学习Libra数字货币的MOVE语言,发现它是用Rust编写的,所以先补一下Rust的基础知识.学习了一段时间,发现Rust的学习曲线非常陡峭,不过仍有快速入门的办法. 学习任何一项技能最怕没有 ...
- vs2019 更新之后无法用ctrl+d再设置回来..
工具-选项-环境-键盘
- 容斥原理--计算错排的方案数 UVA 10497
错排问题是一种特殊的排列问题. 模型:把n个元素依次标上1,2,3.......n,求每一个元素都不在自己位置的排列数. 运用容斥原理,我们有两种解决方法: 1. 总的排列方法有A(n,n),即n!, ...
- linux centos7下源码 tar安装mysql5.7.22或mysql5.7.20 图文详解
之前用的rpm安装的每次安装都是最新的,,,导致每次版本不统一... 现在用tar包安装5.7.22和5.7.20一样的 5.7.20之后的和之前的版本还是有点不一样的 官网地址 https:// ...
- keyword:react native bridge
js engine native react native bridge https://cn.bing.com/images/search?view=detailV2&id=AAF39636 ...
- 【05】C#特有的ref、out参数
java和C#非常相似,它们大部分的语法是一样的,但尽管如此,也有一些地方是不同的. 为了更好地学习java或C#,有必要分清它们两者到底在哪里不同. 我们这次要来探讨C#特有的ref.out参数. ...
- 记录一次排查使用HttpWebRequest发送请求的发生“基础连接已关闭:接收时发生错误”异常问题的过程
描述:某次更新程序,需要给测试员MM测试,之前都是正常的,更新后给MM测试就报异常System.Net.WebException 基础连接已经关闭:接收时发生错误 -------> System ...
- Python连接MongoDB数据库并执行操作
原文:https://blog.51cto.com/1767340368/2092813 环境设置: [root@mongodb ~]# cat /etc/redhat-release CentOS ...