Presto: SQL on Everything
Presto是FB开源出来的实时分析引擎,可以federated的从多种数据源去读取数据,做联合查询,支持实时Interactive BI或bath ETL的需求


从其问题域来看,基本是和spark是重合的,那么两者区别是什么?
https://stackoverflow.com/questions/50014017/why-presto-is-faster-than-spark-sql


这两个答案说的比较清楚,
所以可以看出,Presto并没有什么创新的东西,对于Spark而言,主要是做减法,降低overhead,提升性能
所以Presto更偏实时一些,更适用于MPP的场景,较为简单的SQL
Presto的架构和查询流程,都是典型的MPP方式
特点是,执行都是pipeline的方式,所有中间数据和状态都放在内存中,这样比spark那样落盘,再读出的方式要快
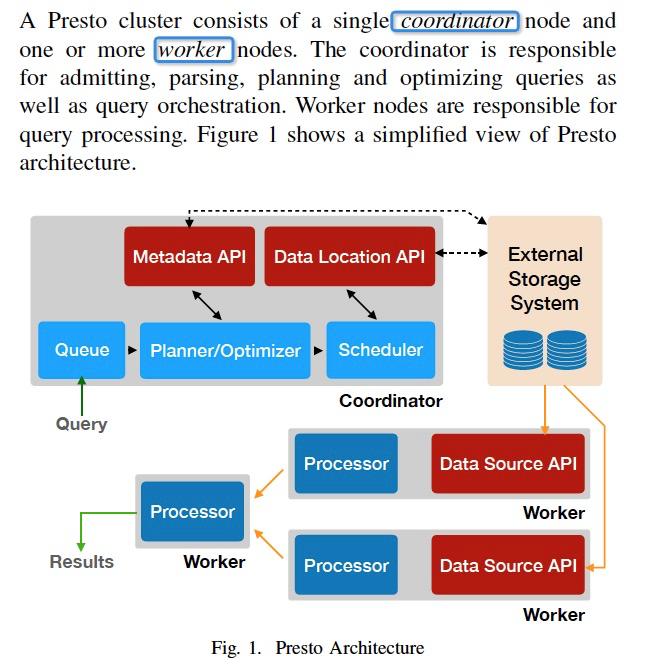

查询过程,
首先是parsing,并形成逻辑计划,
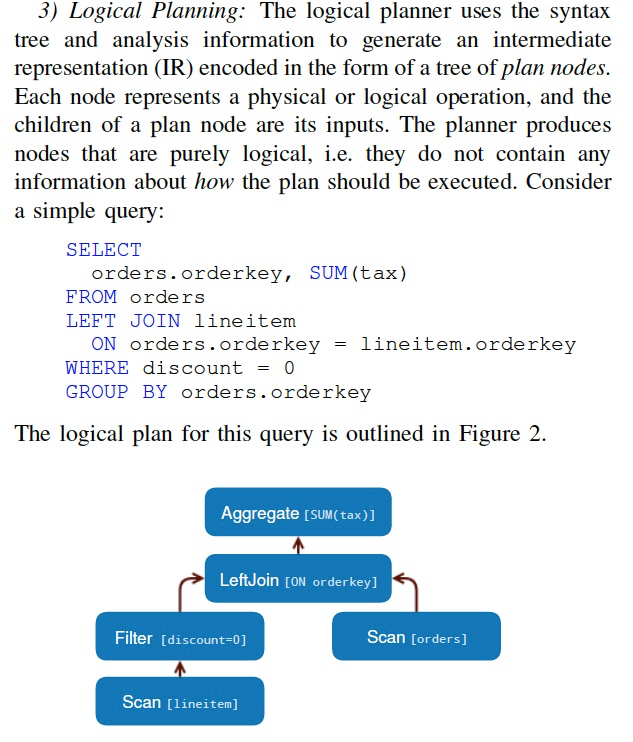
接着是查询优化,和生成物理执行计划
Presto的查询优化没啥创新的
需要注意的是,
首先他也有stage的概念,和spark一样,stage里面可以直接local完成的,所以上面的逻辑计划,
被分成5个stage,stage之间需要shuffle,做过流系统的都知道,一旦shuffle,性能就不行了,对cpu,网络,buffer的消耗都很大
Inter-node,节点间的并行,通过在不同的worker上并行相同的task,处理不同的数据split

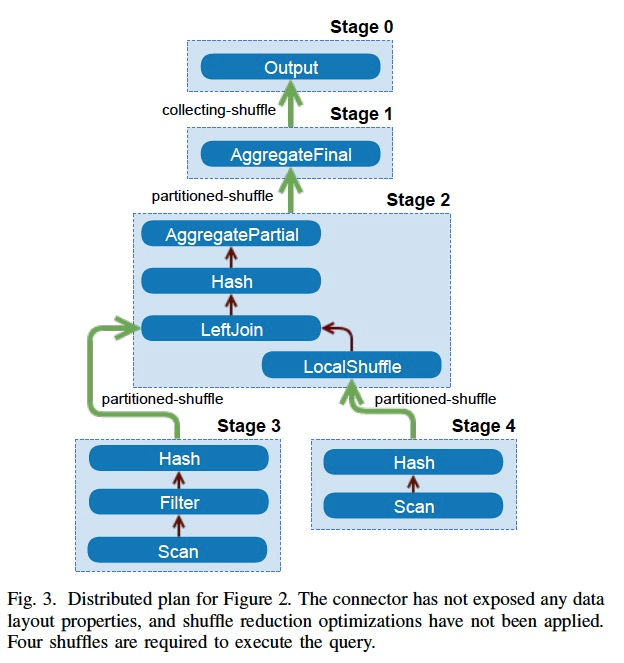
所以思路一定是要尽量减少shuffle,思路也比较直观,比如做join,如果相同join id的数据都在一个节点,就不用shuffle
这个就叫,Data Layout Properties,数据分布

还有,Node Properties,根据node的属性来,减少不必要的shuffle,合并stage


再者,看看Intra-node,节点内的并行,通过thread,这个应该是Presto的特点,可以大大提升查询性能
右图可以看出,在pipeline1,pipeline2中加了很多并发的thread来并行的做

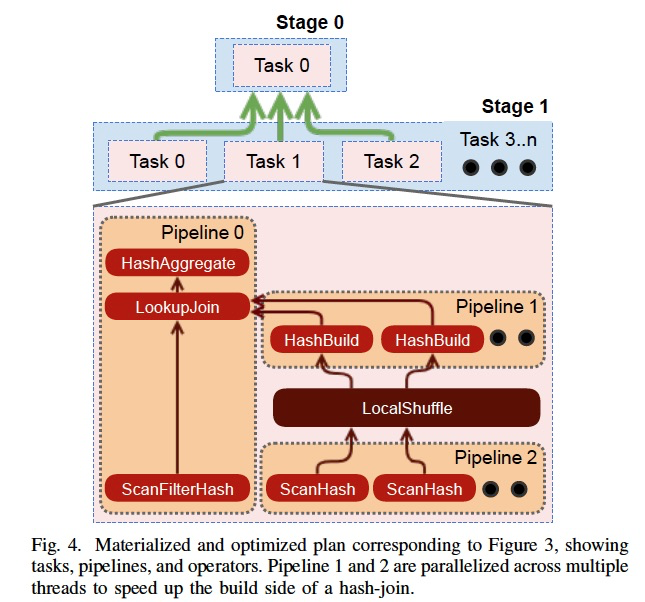
计划生成完后,就是调度,
Coordinator将plan stages以可执行tasks,分发到各个workers上去,task一个执行单元
Task中又包含很多pipelines,pipeline由operators组成

调度分为3种,
Stage调度,可以all in,或分阶段
all in,延迟会小,但会耗费更多的资源

Task Scheduling,

Split Scheduling
最终还要给各个leaf stage分配splits,因为leaf stage必须要被分配splits后才能启动
presto这里的优化,先只会enumerate一小批的splits,分配给各个task,不会一下把所有的splits都捞出来分配,优点下面也说了


调度完,最后就是执行
Query Execution
开始执行,driver loop开始pass split
这里产生page的概念,source从split读出的结构就是pages,Operator的输入输出也是pages,类似spark中的RDD
从右图可以看出,page是一种以column方式组织的结构,便于AP


第二步是shuffle,
presto是延迟优先的,所以shuffle的中间结果不能落盘,放在memory buffer里面
其他worker通过Http Long-Polling的方式来拉数据
同时要监控,output和input的buffer的使用情况,来调整并发,避免内存占用过高
output buffer太大了,让写并发降一些,如果input buffer太大,让读并发降些,这样也会触发前面的写并发的反压

最后是把结果写出,
写吞吐如果要高,多开写并发,但是写并发高,对存储的要求就比较高,
比如对于S3,每个并发都需要写一个文件,会导致很多小文件,查询起来就很麻烦
Presto采用的是adaptive来决定写并发

Presto: SQL on Everything的更多相关文章
- Hive sql和Presto sql的一些对比
最近由于工作上和生活上的一些事儿好久没来博客园了,但是写博客的习惯还是得坚持,新的一年需要更加努力,困知勉行,终身学习,每天都保持空杯心态.废话不说,写一些最近使用到的Presto SQL和Hive ...
- facebook Presto SQL分析引擎——本质上和spark无异,分解stage,task,MR计算
Presto 是由 Facebook 开源的大数据分布式 SQL 查询引擎,适用于交互式分析查询,可支持众多的数据源,包括 HDFS,RDBMS,KAFKA 等,而且提供了非常友好的接口开发数据源连接 ...
- 探究Presto SQL引擎(3)-代码生成
vivo 互联网服务器团队- Shuai Guangying 探究Presto SQL引擎 系列:第1篇<探究Presto SQL引擎(1)-巧用Antlr>介绍了Antlr的基本用法 ...
- 探究Presto SQL引擎(4)-统计计数
作者:vivo互联网用户运营开发团队 - Shuai Guangying 本篇文章介绍了统计计数的基本原理以及Presto的实现思路,精确统计和近似统计的细节及各种优缺点,并给出了统计计数在具体业务 ...
- 探究Presto SQL引擎(1)-巧用Antlr
一.背景 自2014年大数据首次写入政府工作报告,大数据已经发展7年.大数据的类型也从交易数据延伸到交互数据与传感数据.数据规模也到达了PB级别. 大数据的规模大到对数据的获取.存储.管理.分析超出了 ...
- presto的动态化应用(一):presto节点的横向扩展与伸缩
一.presto动态化概述 近年来,基于hadoop的sql框架层出不穷,presto也是其中的一员.从2012年发展至今,依然保持年轻的活力(版本迭代依然很快),presto的相关介绍,我们就不赘述 ...
- Presto 学习
Presto 基础知识与概念学习可以参考这些博客: presto 0.166概述 https://www.cnblogs.com/sorco/p/7060166.html Presto学习-prest ...
- presto调研和json解析函数的使用
presto简单介绍 presto是一个分布式的sql交互式查询引擎.可以达到hive查询效率的5到10倍.支持多种数据源的秒级查询. presto是基于内存查询的,这也是它为什么查询快的原因.除了基 ...
- sqlalchemy presto 时间比较
大数据统计时,需要计算开仓订单减掉经纪商时间差,等于n 小时 或 星期几的订单. presto sql语句如下: select sum(profit) from t_table where open_ ...
随机推荐
- gulp与webpack的区别?是一种工具吗?
问:gulp和webpack什么关系,是一种东西吗?可以只用gulp,不用webpack吗 或者反过来?有什么区别? 答:gulp是工具链.自动化构建工具,可以配合各种插件,我们不用再做机械重复的工作 ...
- 学校老师没重点讲的C语言
格式说明由“%”和格式字符组成,如%d%f等.它的作用是将输出的数据转换为指定的格式输出.格式说明总是由“%”字符开始的.不同类型的数据用不同的格式字符. 格式字符有d,o,x,u,c,s,f,e,g ...
- Es查询工具使用
Kibana按照索引过滤数据 1.创建索引模式 2.查询索引中的数据 Es查询不返回数据 创建索引的时候指定mapping mappings={ "mappings": { &qu ...
- 微信小程序 - scroll-view的scroll-into-view属性 - 在页面打开后滚动到指定的项
需求: 这是一个可横向滚动的导航条,现在要求我,从别的页面reLaunch回到首页这里,刷新页面内容的同时,菜单项要滚动出来 (如果该菜单项不在可视区域),而不是让他被挡住. 代码:<scrol ...
- CentOS6.7安装部署之Tomcat多实例
Tomcat单机多实例配置 操作前的准备:关闭防火墙,配置好IP地址,安装好JAVA环境 1.首先创建tomcat所有实例共同的工作目录/data/webapps以及tomcat所有实例的所在目录/d ...
- The Preliminary Contest for ICPC Asia Nanjing 2019 H. Holy Grail
题目链接:https://nanti.jisuanke.com/t/41305 题目说的很明白...只需要反向跑spfa然后输入-dis,然后添-dis的一条边就好了... #include < ...
- linux使用useradd创建的用户没有目录的解决办法
转载请注明来源https://www.cnblogs.com/sogeisetsu/p/11401562.html或https://blog.csdn.net/suyues/article/detai ...
- Educational Codeforces Round 69 (Rated for Div. 2) E. Culture Code
Educational Codeforces Round 69 (Rated for Div. 2) E. Culture Code 题目链接 题意: 给出\(n\)个俄罗斯套娃,每个套娃都有一个\( ...
- 斐波那契数性质 gcd(F[n],F[m])=F[gcd(n,m)]
引理1 结论: \[F(n)=F(m)F(n-m+1)+F(m-1)F(n-m)\] 推导: \[ \begin{aligned} F(n) &= F(n-1)+F(n-2) \\ & ...
- Nginx——跨域造成的504问题
前言 前台域名和后台域名是两个不同不同的二级域名,访问的时候造成了跨域,出现了504错误 解决 修改Nginx配置,将超时的时间设置为1200秒 keepalive_timeout 1200; pro ...