爬虫之scrapy框架应用selenium
一、利用selenium 爬取 网易军事新闻
使用流程:
'''
在scrapy中使用selenium的编码流程:
1.在spider的构造方法中创建一个浏览器对象(作为当前spider的一个属性)
2.重写spider的一个方法closed(self,spider),在该方法中执行浏览器关闭的操作
3.在下载中间件的process_response方法中,通过spider参数获取浏览器对象
4.在中间件的process_response中定制基于浏览器自动化的操作代码(获取动态加载出来的页面源码数据)
5.实例化一个响应对象,且将page_source返回的页面源码封装到该对象中
6.返回该新的响应对象
'''
首先需要在中间件导入
from scrapy.html import HtmlResponse
DownloadMiddleware函数
def process_response(self, request, response, spider):
# Called with the response returned from the downloader. # Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest # 获取动态加载出来的数据
print("即将返回一个新的响应对象")
bw = spider.bw
bw.get(url = request.url)
import time
# 防止数据加载过慢
time.sleep(3)
# 包含了动态加载的数据
page_text = bw.page_source
time.sleep(3)
return HtmlResponse(url=spider.bw.current_url,body=page_text,
encoding="utf8",request=request)
spider.py
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver class ScrapySeleniumSpider(scrapy.Spider):
name = 'scrapy_selenium'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://war.163.com/']
def __init__(self):
self.bw = webdriver.Chrome(executable_path="F:\爬虫+数据\chromedriver.exe") def parse(self, response):
div_list = response.xpath('//div[@class="data_row news_article clearfix "]')
for div in div_list:
title = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first()
print(title) def closed(self, spider):
print('关闭浏览器对象!')
self.bw.quit()
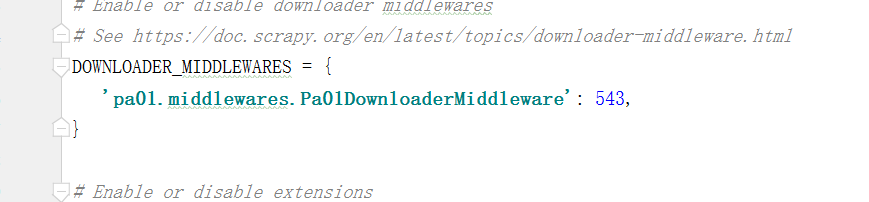
还需要注意的是使用中间件的同时需要在settings中解释一下Downloadmiddleware
结果是这样就成功喽

爬虫之scrapy框架应用selenium的更多相关文章
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- 爬虫06 /scrapy框架
爬虫06 /scrapy框架 目录 爬虫06 /scrapy框架 1. scrapy概述/安装 2. 基本使用 1. 创建工程 2. 数据分析 3. 持久化存储 3. 全栈数据的爬取 4. 五大核心组 ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 爬虫之scrapy框架
解析 Scrapy解释 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓 ...
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- 爬虫之Scrapy框架介绍
Scrapy介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内 ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- 5、爬虫之scrapy框架
一 scrapy框架简介 1 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Sc ...
随机推荐
- java.lang.ClassNotFoundException: com.netflix.hystrix.contrib.javanica.aop.aspectj.HystrixCommandAspect
添加这个依赖 <dependency> <groupId>com.netflix.hystrix</groupId> <artifactId>hystr ...
- 011-MySQL Query Cache 查询缓存设置操作
一.概述 MySQL Query Cache 会缓存select 查询,安装时默认是开启的,但是如果对表进行INSERT, UPDATE, DELETE, TRUNCATE, ALTER TABLE, ...
- Spring MVC -- 下载文件
像图片或者HTML文件这样的静态资源,在浏览器中打开正确的URL即可下载,只要该资源是放在应用程序的目录下,或者放在应用程序目录的子目录下,而不是放在WEB-INF下,tomcat服务器就会将该资源发 ...
- (CSDN 迁移) JAVA循环删除List的某个元素
若列表中只可能存在一个则可以用简单的循环删除,不多说. 若列表中可能存在多个,尤其是可能有多个连续的需要删除,用简单循环有可能发生异常. 需要使用迭代器(Iterator),两种具体实现: 逻辑上是一 ...
- oracle 在列名后的 (+)是什么意思,如何转换为mysql
外连接的意思select *from a,bwhere a.id=b.id(+)意思就是返回a,b中匹配的行 和 a中有但是b中没有的行. 参考https://www.cnblogs.com/Aaro ...
- Shadowing of static functions in Java
class A { static void fun() { System.out.println("A.fun()"); } } class B extends A { stati ...
- [转帖]教你如何破解IC卡的校验值
教你如何破解IC卡的校验值 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/weixin ...
- C/C++ 每日一题
超长正整数的相加,题目链接:https://www.nowcoder.com/practice/5821836e0ec140c1aa29510fd05f45fc?tpId #include<al ...
- 爬虫 request payloa
小知识点: https://blog.csdn.net/zwq912318834/article/details/79930423
- 【C语言】学不会的指针
指针 前言: 指针是C语言程序的核心,刚开始学指针,嗯....这样呀,貌似不难呀:之后开始用指针,&p,p,*p,**p,这些指针在用的时候,额.....什么东东?每次都要想半天,特别是遇到双 ...