爬虫之scrapy框架应用selenium
一、利用selenium 爬取 网易军事新闻
使用流程:
'''
在scrapy中使用selenium的编码流程:
1.在spider的构造方法中创建一个浏览器对象(作为当前spider的一个属性)
2.重写spider的一个方法closed(self,spider),在该方法中执行浏览器关闭的操作
3.在下载中间件的process_response方法中,通过spider参数获取浏览器对象
4.在中间件的process_response中定制基于浏览器自动化的操作代码(获取动态加载出来的页面源码数据)
5.实例化一个响应对象,且将page_source返回的页面源码封装到该对象中
6.返回该新的响应对象
'''
首先需要在中间件导入
from scrapy.html import HtmlResponse
DownloadMiddleware函数
def process_response(self, request, response, spider):
# Called with the response returned from the downloader. # Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest # 获取动态加载出来的数据
print("即将返回一个新的响应对象")
bw = spider.bw
bw.get(url = request.url)
import time
# 防止数据加载过慢
time.sleep(3)
# 包含了动态加载的数据
page_text = bw.page_source
time.sleep(3)
return HtmlResponse(url=spider.bw.current_url,body=page_text,
encoding="utf8",request=request)
spider.py
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver class ScrapySeleniumSpider(scrapy.Spider):
name = 'scrapy_selenium'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://war.163.com/']
def __init__(self):
self.bw = webdriver.Chrome(executable_path="F:\爬虫+数据\chromedriver.exe") def parse(self, response):
div_list = response.xpath('//div[@class="data_row news_article clearfix "]')
for div in div_list:
title = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first()
print(title) def closed(self, spider):
print('关闭浏览器对象!')
self.bw.quit()
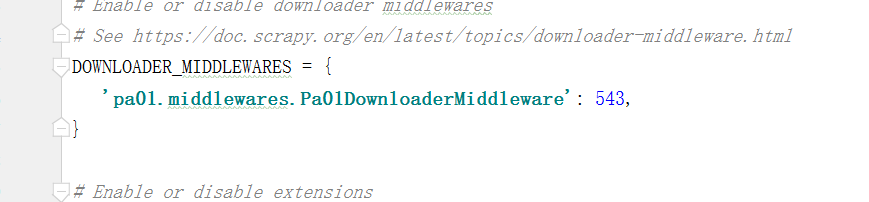
还需要注意的是使用中间件的同时需要在settings中解释一下Downloadmiddleware
结果是这样就成功喽

爬虫之scrapy框架应用selenium的更多相关文章
- Python网络爬虫之Scrapy框架(CrawlSpider)
目录 Python网络爬虫之Scrapy框架(CrawlSpider) CrawlSpider使用 爬取糗事百科糗图板块的所有页码数据 Python网络爬虫之Scrapy框架(CrawlSpider) ...
- 爬虫06 /scrapy框架
爬虫06 /scrapy框架 目录 爬虫06 /scrapy框架 1. scrapy概述/安装 2. 基本使用 1. 创建工程 2. 数据分析 3. 持久化存储 3. 全栈数据的爬取 4. 五大核心组 ...
- Python逆向爬虫之scrapy框架,非常详细
爬虫系列目录 目录 Python逆向爬虫之scrapy框架,非常详细 一.爬虫入门 1.1 定义需求 1.2 需求分析 1.2.1 下载某个页面上所有的图片 1.2.2 分页 1.2.3 进行下载图片 ...
- 爬虫之scrapy框架
解析 Scrapy解释 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓 ...
- Python爬虫进阶(Scrapy框架爬虫)
准备工作: 配置环境问题什么的我昨天已经写了,那么今天直接安装三个库 首先第一步: ...
- 爬虫之Scrapy框架介绍
Scrapy介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内 ...
- 16.Python网络爬虫之Scrapy框架(CrawlSpider)
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- python爬虫随笔-scrapy框架(1)——scrapy框架的安装和结构介绍
scrapy框架简介 Scrapy,Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 ...
- 5、爬虫之scrapy框架
一 scrapy框架简介 1 介绍 Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Sc ...
随机推荐
- vue install 组件
import share from './index.vue' export default { install: (Vue) => { Vue.prototype.$share = (opti ...
- Nginx学习之入门
1. 概念 (1) 什么是nginx? Nginx (engine x) 是一款轻量级的Web 服务器 .反向代理服务器及电子邮件(IMAP/POP3)代理服务器. (2) 什么是反向代 ...
- 阿里云composer 镜像
2019年12月2日13:54:32 https://developer.aliyun.com/composer 阿里云的镜像更新时间比较及时 本镜像与 Packagist 官方实时同步,推荐使用最新 ...
- linux添加虚拟内存交换内存,以及设置优先使用交换内存
场景:在网上买了台低配置服务器,1c1g,内存太小了,于是打起了交换内存的注意.上网一查,居然还真可以.以下是具体步骤 首先新建一个交换分区文件夹 dd if=/dev/zero of=/usr/sw ...
- JobStorage.Current property value has not been initialized. You must set it before using Hangfire Client or Server API.
JobStorage.Current property value has not been initialized. You must set it before using Hangfire Cl ...
- 微服务, 架构, 服务治理, 链路跟踪, 服务发现, 流量控制, Service Mesh
微服务, 架构, 服务治理, 链路跟踪, 服务发现, 流量控制, Service Mesh 微服务架构 本文将介绍微服务架构和相关的组件,介绍他们是什么以及为什么要使用微服务架构和这些组件.本文侧 ...
- OTP详解
OTP(One Time Programmable)是单片机的一种存储器类型,意思是一次性可编程:程序烧入单片机后,将不可再次更改和清除. 随着嵌入式应用的越来越广泛,产品的安全也显得越来越重要.一方 ...
- javascript jssdk微信上传一张图片的方法
javascript jssdk微信上传一张图片的方法 <pre> wx.chooseImage({ count: 1, // 默认9 sizeType: ['original', 'co ...
- Python入门学习(1)
静态语言: C/C++.Java 编译器一次性生成目标代码,优化更方便 程序运行速度快 动态语言: Python.JavaScript.PHP 执行程序时需要源代码,维护更灵活 源代码在维护灵活.跨多 ...
- Idea Spring 、SpringBoot相关设置技巧
1.Spring变量依赖注入出现红色波浪线 Could not autowire. No beans of 'UserMapper' type found. less... (Ctrl+F1) Che ...