第二十三节:scrapy爬虫识别验证码(二)图片验证码识别
图片验证码基本上是有数字和字母或者数字或者字母组成的字符串,然后通过一些干扰线的绘制而形成图片验证码。
例如:知网的注册就有图片验证码
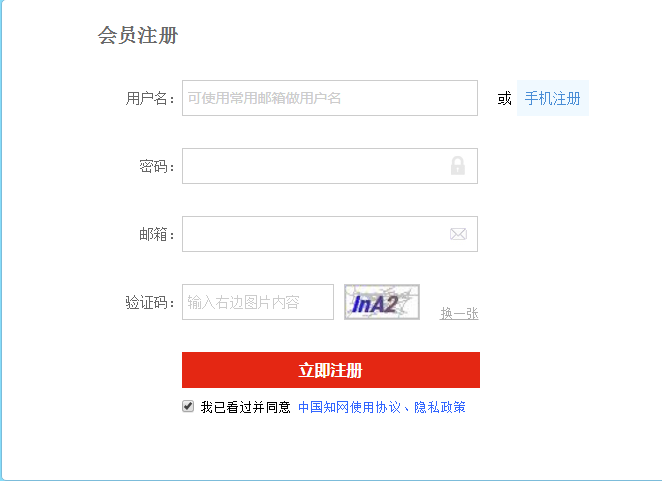
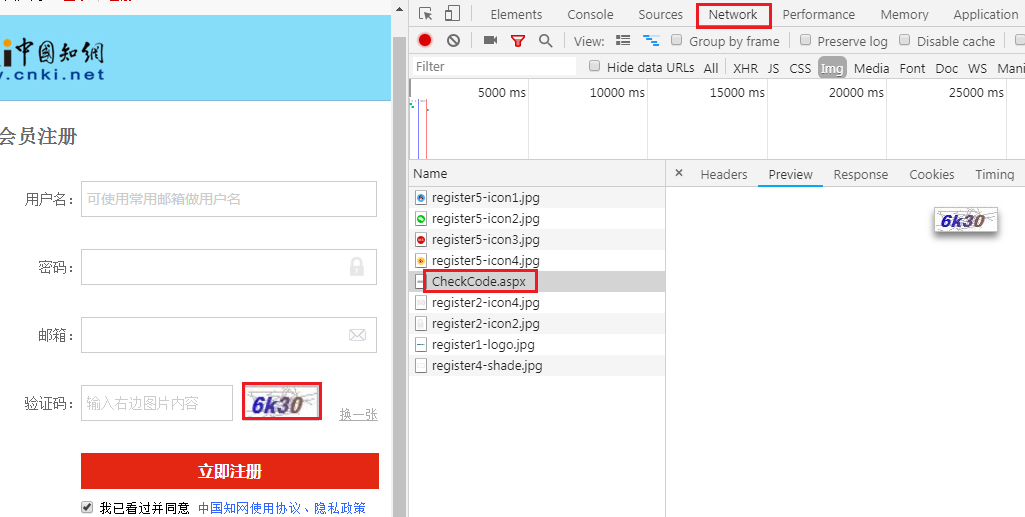
首先我们需要获取验证码图片,通过开发者工具我们可以得到验证码url链接
其次就是通过Pillow类库和tesserocr进行识别,代码如下:
# -*- coding:utf-8 -*-
import tesserocr
from PIL import Image
import requests # 通过url链接获取验证码图片,并写入本地文件夹里
def get_image(path,url):
"""
:param path: 文件夹路径
:param url: 验证码url链接
"""
respon = requests.get(url=url) # 请求验证码url
with open(path,"wb") as file:
file.write(respon.content) # 将验证码写到本地 # 由于验证码图片太小,需要对验证码图片放大处理,以便识别
def reset_image_size(image_path):
"""
:param image_path: 图片所在的路径
:return:
"""
image = Image.open(fp=image_path) # 打开图片
pic_resize = 5 # 设置图片放大或者缩小倍数
(x, y) = image.size # 获取图片的大小
x_s = int(x * pic_resize) # 放大5倍(可调)
y_s = int(y * pic_resize) # 放大5倍(可调)
out = image.resize((x_s, y_s), Image.ANTIALIAS) # ANTIALIAS表示高质量图片
out.save(image_path) # 读取验证码图片文本
def read_image(image_path):
"""
:param image_path: 验证码图片路径
:return:
"""
image = Image.open(fp=image_path) # 打开验证码图片
image = image.convert('L') # 将验证码图片转换为灰度图(L表示灰度图)
threshold = 127 # 设置灰度图二值化阈值
table = []
for i in range(256): # 像素为256
if i < threshold:
table.append(0)
else:
table.append(1)
image = image.point(table, '') # 二值化处理后的副本(1表示二值化)
image.show()
result = tesserocr.image_to_text(image) # 验证码图片转换为文本
return result # 验证码识别信息脏数据处理
def VerifInfo(result):
"""
:param result: 验证码图片通过初步识别后得到的脏数据
:return:
"""
verif_str = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890"
verif_list = []
for i in result:
if i in verif_str:
verif_list.append(i)
return "".join(verif_list) if __name__ == '__main__':
img_path = "D:\photo\image" # 文件夹目录
img_path = img_path + "\VerificationCode.png" # 验证码图片所在的目录及名称
img_url = "http://my.cnki.net/elibregister/CheckCode.aspx" # 验证码url
get_image(img_path,img_url) # 获取验证码图片
reset_image_size(img_path) # 调整验证码图片大小
result = read_image(img_path) # 读取验证码图片内容
verif_info = VerifInfo(result) # 验证码内容数据处理
verif_len = len(verif_info) # 验证码识别长度
if verif_len == 4 and verif_info:
print(verif_info)
else:
pass
图片字母数字验证码识别
最后就是看看识别的效果吧。前者为原始验证码图片,后者是经过二值化处理的图片。

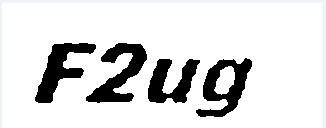
输出的结果为:FZug
显然使用tesserocr识别还是有误差的,以后可以用深度学习的方式训练处一个模型,可以提高识别效率,后期会跟进实现的。
第二十三节:scrapy爬虫识别验证码(二)图片验证码识别的更多相关文章
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- centos LNMP第一部分环境搭建 LAMP LNMP安装先后顺序 php安装 安装nginx 编写nginx启动脚本 懒汉模式 mv /usr/php/{p.conf.default,p.conf} php运行方式SAPI介绍 第二十三节课
centos LNMP第一部分环境搭建 LAMP安装先后顺序 LNMP安装先后顺序 php安装 安装nginx 编写nginx启动脚本 懒汉模式 mv /usr/local/php/{ ...
- (转)第二十三节 inotify事件监控工具
第二十三节 inotify事件监控工具 标签(空格分隔): Linux实战教学笔记-陈思齐 原文:http://www.cnblogs.com/chensiqiqi/p/6542268.html 第1 ...
- 风炫安全WEB安全学习第二十三节课 利用XSS获取COOKIE
风炫安全WEB安全学习第二十三节课 利用XSS获取COOKIE XSS如何利用 获取COOKIE 我们使用pikachu写的pkxss后台 使用方法: <img src="http:/ ...
- SpringCloud微服务实战——搭建企业级开发框架(二十四):集成行为验证码和图片验证码实现登录功能
随着近几年技术的发展,人们对于系统安全性和用户体验的要求越来越高,大多数网站系统都逐渐采用行为验证码来代替图片验证码.GitEgg-Cloud集成了开源行为验证码组件和图片验证码,并在系统中添加可配置 ...
- 潭州课堂25班:Ph201805201 django 项目 第十课 自定义错误码,完成图片验证码,用户是否被注册功能 (课堂笔记)
把 视图传到前台的 JsonResponse(data=data) 先进行处理,之后再传到前台, 处理:引用自定义错误代码,把错误代码返回给前台,前台根据错误代码中文提示 class Code: O ...
- Python识别字符型图片验证码
前言 验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越来越严峻.本文介绍了一套字符验证码识别的完整流程,对于验 ...
- 文字识别还能这样用?通过Python做文字识别到破解图片验证码
前期准备 1. 安装包,直接在终端上输入pip指令即可: # 发送浏览器请求 pip3 install requests # 文字识别 pip3 install pytesseract # 图片处理 ...
- 【图片识别】java 图片文字识别 ocr (转)
http://www.cnblogs.com/inkflower/p/6642264.html 最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为 ...
随机推荐
- WFS1.1.0协议(增删改查)+openlayers4.3.1前端构建+geoserver2.15.1安装部署+shpfile数据源配置
WFS简介 1.WFS即,Web要素服务,全称WebFeatureService.GIS下,支持对地理要素的插入,更新,删除,检索和发现服务. 2.属于OGC标准下的通信协议.OGC标准下的GIS服务 ...
- 初窥MySQL性能调优
本文涉及:MySQL自带的性能测试工具mysqlslap的使用及几个性能调优的方法 性能测试工具—mysqlslap mysqlslap是MySQL自带的一款非常优秀的性能测试工具.使用它可以 模拟多 ...
- C# DateTime.Now 详解
//2008年4月24日 System.DateTime.Now.ToString("D"); //2008-4-24 System.DateTime.Now.ToString(& ...
- Luogu P1233 木棍加工 【贪心/LIS】
题目描述 一堆木头棍子共有n根,每根棍子的长度和宽度都是已知的.棍子可以被一台机器一个接一个地加工.机器处理一根棍子之前需要准备时间.准备时间是这样定义的: 第一根棍子的准备时间为1分钟: 如果刚处理 ...
- ssh 公钥登录远程主机
ssh-keygen 然后一路回车就可以了 ssh-copy-id user@host user代表用户名,host代表主机地址 然后根据提示输入远程主机的密码,成功,再登录就不用输入密码了
- Code:Blocks 中文乱码问题原因分析和解决方法
下面说说修改的地方. 1.修改源文件保存编码在:settings->Editor->gernal settings 看到右边的Encoding group Box了吗?如下图所示: Use ...
- Tian Ji -- The Horse Racing HDU - 1052
Tian Ji -- The Horse Racing HDU - 1052 (有平局的田忌赛马,田忌赢一次得200块,输一次输掉200块,平局不得钱不输钱,要使得田忌得到最多(如果只能输就输的最少) ...
- 转 ORA-12638: 身份证明检索失败
ORA-12638: 身份证明检索失败 的解决办法 2008年06月25日 星期三 11:42 the NTS option makes the Oracle client attempt to us ...
- HashMap和List遍历方法总结及如何遍历删除元素
https://blog.csdn.net/demohui/article/details/77748809
- Swift 中的基础语法(二)
1.Swift 中的函数 /// 函数的定义 /// /// - Parameters: /// - x: 形参 /// - y: 形参 /// - Returns: 返回值 func sum(x: ...