关于HashMap中hash()函数的思考
关于HashMap中hash()函数的思考
JDK7中hash函数的实现
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
这段代码是为了对key的hashCode进行扰动计算,防止不同hashCode的高位不同但低位相同导致的hash冲突。简单点说,就是为了把高位的特征和低位的特征组合起来,降低哈希冲突的概率,也就是说,尽量做到任何一位的变化都能对最终得到的结果产生影响。
举个例子来说,我们现在想向一个HashMap中put一个K-V对,Key的值为“hollischuang”,经过简单的获取hashcode后,得到的值为“1011000110101110011111010011011”,如果当前HashTable的大小为16,即在不进行扰动计算的情况下,他最终得到的index结果值为11。由于15的二进制扩展到32位为“00000000000000000000000000001111”,所以,一个数字在和他进行按位与操作的时候,前28位无论是什么,计算结果都一样(因为0和任何数做与,结果都为0)。如下图所示。
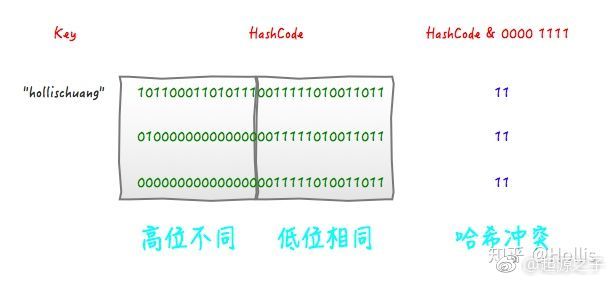
可以看到,后面的两个hashcode经过位运算之后得到的值也是11 ,虽然我们不知道哪个key的hashcode是上面例子中的那两个,但是肯定存在这样的key,这就产生了冲突。
那么,接下来,我看看一下经过扰动的算法最终的计算结果会如何。

从上面图中可以看到,之前会产生冲突的两个hashcode,经过扰动计算之后,最终得到的index的值不一样了,这就很好的避免了冲突。
static int indexFor(int h, int length) {
return h & (length-1);
}
我们一般对哈希表的散列很自然地会想到用hash值对length取模(即除法散列法),Hashtable中也是这样实现的,这种方法基本能保证元素在哈希表中散列的比较均匀,但取模会用到除法运算,效率很低,HashMap中则通过h&(length-1)的方法来代替取模,同样实现了均匀的散列,但效率要高很多,这也是HashMap对Hashtable的一个改进。
首先,length为2的整数次幂的话,h&(length-1)就相当于对length取模,这样便保证了散列的均匀,同时也提升了效率;其次,length为2的整数次幂的话,为偶数,这样length-1为奇数,奇数的最后一位是1,这样便保证了h&(length-1)的最后一位可能为0,也可能为1(这取决于h的值),即与后的结果可能为偶数,也可能为奇数,这样便可以保证散列的均匀性,而如果length为奇数的话,很明显length-1为偶数,它的最后一位是0,这样h&(length-1)的最后一位肯定为0,即只能为偶数,这样任何hash值都只会被散列到数组的偶数下标位置上,这便浪费了近一半的空间,因此,length取2的整数次幂,是为了使不同hash值发生碰撞的概率较小,这样就能使元素在哈希表中均匀地散列。
JDK8中hash函数的实现
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
java8将hash函数简化了,但目的和java7是一样的,这种做法可以称为“扰动函数”,目的就是为了是散列值能够解区并分散均匀(两个目的)。
理论上key.hashCode()方法得到的散列值为int是个32为带符号整数,范围从-2147483648到2147483648。前后加起来大概40亿的映射空间。只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。你想,HashMap扩容之前的数组初始大小才16。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来访问数组下标。
jdk8中没有定义单独的indexFor()函数而是在取模时直接用(n-1)&hash,原理和JDK7是一样的。以初始长度16为例,16-1=15。2进制表示是00000000 00000000 00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。
但这时候问题就来了,这样就算我的散列值分布再松散,要是只取最后几位的话,碰撞也会很严重。更要命的是如果散列本身做得不好,分布上成等差数列的漏洞,恰好使最后几个低位呈现规律性重复。
这时候“扰动函数”的价值就体现出来了,说到这里大家应该猜出来了。看下面这个图:
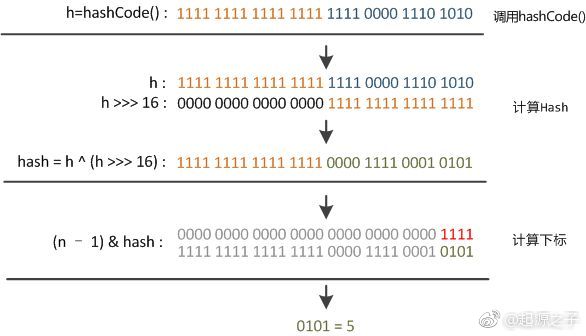
右位移16位,正好是32bit的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相保留下来。但明显Java 8觉得扰动做一次就够了,做4次的话,多了可能边际效用也不大,所谓为了效率考虑就改成一次了。
参考文献: 知乎问题:JDK 源码中 HashMap 的 hash 方法原理是什么?
关于HashMap中hash()函数的思考的更多相关文章
- K:HashMap中hash函数的作用
在分析了hashCode方法和equals方法之后,我们对hashCode方法和equals方法的相关作用有了大致的了解.在通过查看HashMap类的相关源码的时候,发现其中存在一个int has ...
- 关于《Head First Python》一书中print_lol()函数的思考
关于<Head First Python>一书中print_lol()函数的思考 在<Head First Python>第一章中,讲述到Python处理复杂数据(以电影数据列 ...
- Java中hashCode()方法以及HashMap()中hash()方法
Java的Object类中有一个hashCode()方法: public final native Class<?> getClass(); public native int hashC ...
- 深入理解HashMap(及hash函数的真正巧妙之处)
原文地址:http://www.iteye.com/topic/539465 Hashmap是一种非常常用的.应用广泛的数据类型,最近研究到相关的内容,就正好复习一下.网上关于hashmap的文章很多 ...
- hashmap的hash算法( 转)
HashMap 中hash table 定位算法: int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); 其中i ...
- HashMap中的hash函数
在写一个HashSet时候有个需求,是判断HashSet中是否已经存在对象,存在则取出,不存在则add添加.HashSet也是通过HashMap实现,只用了HashMap的key,value都存储一个 ...
- hashCode及HashMap中的hash()函数
一.hashcode是什么 要理解hashcode首先要理解hash表这个概念 1. 哈希表 hash表也称散列表(Hash table),是根据关键码值(Key value)而直接进行访问的数据结构 ...
- [ 转载 ]hashCode及HashMap中的hash()函数
hashCode及HashMap中的hash()函数 一.hashcode是什么 要理解hashcode首先要理解hash表这个概念 1. 哈希表 hash表也称散列表(Hash table),是 ...
- HashMap 中的 hash 函数
1. 什么是 hash 函数 hash 函数,即散列函数,或叫哈希函数.它可以将不定长的输入,通过散列算法转换成一个定长的输出,这个输出就是散列值.需要注意的是,不同的输入通过散列函数,也可能会得到同 ...
随机推荐
- alsa和oss声音系统比较
OSS(Open Sound System) OSS的含义为,Open Sound System,是unix平台上一个统一的音频接口.以前,每个Unix厂商都会提供一个自己专有的API,用来处理音频. ...
- hadoop Namenode因硬盘写满无法启动
当写元数据的分区写满,可能导致namenode挂掉从而导致及时清理出大块的空间也无法启动namenode,那此时系统namenode会报错 org.apache.hadoop.hdfs.server. ...
- BZOJ_4423_[AMPPZ2013]Bytehattan_对偶图+并查集
BZOJ_4423_[AMPPZ2013]Bytehattan_对偶图+并查集 Description 比特哈顿镇有n*n个格点,形成了一个网格图.一开始整张图是完整的. 有k次操作,每次会删掉图中的 ...
- 「HAOI2015」「LuoguP3178」树上操作(树链剖分
题目描述 有一棵点数为 N 的树,以点 1 为根,且树点有边权.然后有 M 个操作,分为三种: 操作 1 :把某个节点 x 的点权增加 a . 操作 2 :把某个节点 x 为根的子树中所有点的点权都增 ...
- 05:LGTB 与偶数
总时间限制: 10000ms 单个测试点时间限制: 1000ms 内存限制: 65536kB 描述 LGTB 有一个长度为 N 的序列.当序列中存在相邻的两个数的和为偶数的话,LGTB 就能把它 ...
- JAVA Synchronized (二)
一,介绍 本文介绍JAVA多线程中的synchronized关键字作为对象锁的一些知识点. 所谓对象锁,就是就是synchronized 给某个对象 加锁.关于 对象锁 可参考:这篇文章 二,分析 s ...
- 【转】在IDEA中创建maven项目
原文地址: https://blog.csdn.net/zzy1078689276/article/details/78732183 现在的JavaWeb项目中,绝大多数都是采用的maven结构的项目 ...
- JS按字节截取字符长度实例2
/* * param str 要截取的字符串 * param L 要截取的字节长度,注意是字节不是字符,一个汉字两个字节 * return 截取后的字符串 */ function cutStr(str ...
- 一文教您如何通过 Docker 快速搭建各种测试环境(Mysql, Redis, Elasticsearch, MongoDB) | 建议收藏
欢迎关注个人微信公众号: 小哈学Java, 文末分享阿里 P8 高级架构师吐血总结的 <Java 核心知识整理&面试.pdf>资源链接!! 个人网站: https://www.ex ...
- Unity陀螺仪
using UnityEngine; using System.Collections; using UnityEngine.UI; //摄像机 陀螺仪转动 public class TGyro : ...