python学习笔记——提取网页中的信息正则表达式re
被用来检索\替换那些符合某个模式(规则)的文本,对于文本过滤或规则匹配,最强大的就是正则表达式,是python爬虫里必不可少的神兵利器。
1 正则表达式re基本规则
[0-9] 任意一个数字,等价\d
[a-z] 任意一个小写字母
[A-Z]任意一个大写字母
[^0-9] 匹配非数字,等价\D
\w 等价[a-z0-9_],字母数字下划线
\W 等价对\w取非
. 任意字符
[] 匹配内部任意字符或子表达式
[^] 对字符集合取非
* 匹配前面的字符或者子表达式0次或多次
+ 匹配前一个字符至少1次
? 匹配前一个字符0次或1次
^ 匹配字符串开头
$ 匹配字符串结束
2 python的re模块
几个重要的方法:
match: 匹配一次从开头;
search: 匹配一次,从某位置;
findall: 匹配所有;
split: 分隔;
sub: 替换;
3 正则表达式的两种模式
3.1 贪婪模式:(.*)
import re
str = "hello_python3_world"
re_obj = re.compile(".*_")
data = re_obj.findall(str)
print(data)
# 贪婪模式,一直匹配到最后一个下划线_
3.2 懒惰模式:(.*?)
import re
str = "hello_python3_world"
re_obj1 = re.compile(".?_") #['o_', '3_']
re_obj2 = re.compile(".*?_") #['hello_', 'python3_']
data1 = re_obj1.findall(str)
data2 = re_obj2.findall(str)
print(data1)
print(data2)
# 懒惰模式,匹配到第一个下划线_时即停止继续匹配
4 相关软件
RegexTester.exe
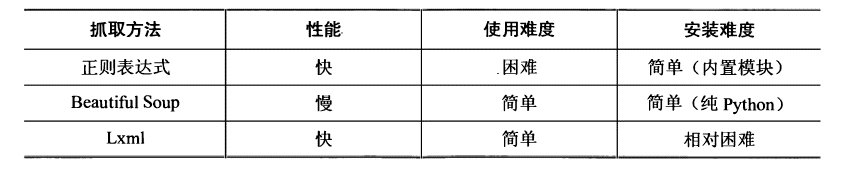
5 正则 BS lxml的比较
6 示例
5.1 示例一
用正则表达式实现下面的效果:
把 i=d%0A&from=AUTO&to=AUTO&smartresult=dict
转换成下面的形式:
i:d%0A
from:AUTO
to:AUTO
smartresult:dict
import re
str = "i=d%0A&from=AUTO&to=AUTO&smartresult=dict"
re_obj = re.compile("&")
data = re_obj.split(str) #data数据存储['i=d%0A', 'from=AUTO', 'to=AUTO', 'smartresult=dict']
m = len(data)
for i in range(m):
print(data[i])
python学习笔记——提取网页中的信息正则表达式re的更多相关文章
- python学习笔记——提取网页信息BeautifulSoup4
1 BeautifulSoup概述 beautifulSoup是勇python语言编写的一个HTML/XML的解析器,它可以很好地处理不规范标记并将其生成剖析树(parse tree): 它提供简单而 ...
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
- 1. svg学习笔记-在网页中使用svg
在网页中使用svg有以下三种方式 1. svg归根结底来说是一种图像格式,虽然有别于jpeg,gif,png等位图图像格式,所以在网页中能嵌入图像的地方都可以嵌入svg,例如将svg文件设置为< ...
- 吴裕雄--天生自然python学习笔记:网页解析
抓取万水书苑网页中所有<a>标签中的超链接井显示. import requests from bs4 import BeautifulSoup url = 'http://www.wsbo ...
- python学习笔记——urllib库中的parse
1 urllib.parse urllib 库中包含有如下内容 Package contents error parse request response robotparser 其中urllib.p ...
- python学习笔记013——模块中的私有属性
1 私有属性的使用方式 在python中,没有类似private之类的关键字来声明私有方法或属性.若要声明其私有属性,语法规则为: 属性前加双下划线,属性后不加(双)下划线,如将属性name私有化,则 ...
- Python学习笔记020——数据库中的数据类型
1 数值类型 数值类型分为有符号signed和无符号unsigned两种. 1.1 整型 int (1)bigint 极大整型(8个字节) 范围 :-2**64 ~ 2**64 - 1 -922337 ...
- python学习笔记(excel中处理日期格式)
涉及到处理excel文件中日期格式数据 这里自己整理下 两种方法 代码如下: @classmethod def get_time(cls, table, nrows): testtime = [] f ...
- python学习笔记 改变字符串中的某一位
a = ' a = list(a) a[2] = ' news = ''.join(a) print news,a 注意不能使用 news = '' news.join(a) 因为news.join只 ...
随机推荐
- XE6入门(一)Hello World
XE6的IDE已经设计的非常棒了,是该放弃D7了,投入XE6的怀抱.. 本人用的XE6版本是 Embarcadero.Delphi.XE6.RTM.Inc.Update1.v20.0.16277.12 ...
- .NET 开发套装
Dapper,轻量级ORM GitHub - StackExchange/dapper-dot-net: DapperSharpZipLib,ZIP压缩库 SharpZipLib by icsharp ...
- NSMutableURLRequest Http 请求 同步 异步
#pragma mark get country code//同步 -(void)getFKjsonCountryCode { dispatch_async(dispatch_get_global_q ...
- FIS前端集成解决方案
FIS前端集成解决方案-文档结构 什么是FIS 部署FIS FIS基本使用 模块定义 加载方式 调用Tangram 2.0 FIS开发实例 --附件下载-- 什么是FIS FIS提供了一套贯穿开发流程 ...
- 推荐五星级C语言学习网站
www.cprogrammingexpert.com (此网站,配合了大量动画,每一行代码,配合一副图片) 下面截取了部分的gif动画,大家可以认真看看, 相信作者花了很多心血,去制作这些动画. sc ...
- Mina.Net实现的断线重连
using Mina.Filter.Codec; using Mina.Filter.Codec.TextLine; using System; using System.Collections.Ge ...
- Java 代码行统计(转)
package codecounter; import java.io.BufferedReader; import java.io.File; import java.io.FileNotFound ...
- gson 忽略掉某些字段不进行转换
增加 transient 修饰进行解决,例如: private transient final DecimalFormat df = new DecimalFormat("#0.00&qu ...
- SpringBoot使用Mybatis注解进行一对多和多对多查询(2)
SpringBoot使用Mybatis注解进行一对多和多对多查询 GitHub的完整示例项目地址kingboy-springboot-data 一.模拟的业务查询 系统中的用户user都有唯一对应的地 ...
- python解析命令行参数
常常需要解析命令行参数,经常忘记,好烦,总结下来吧. 1.Python 中也可以所用 sys 的 sys.argv 来获取命令行参数: sys.argv 是命令行参数列表 参数个数:len(sys.a ...