9.13Django ORM那些事
2018-9-13 14:23:22
ORM那些事 参考 : https://www.cnblogs.com/liwenzhou/p/8660826.html
今天的都是ORM的查询 更详细进阶了!
越努力,与幸运!永远不要高估自己!
day69 2018-05-11 1. ORM增删改查操作
http://www.cnblogs.com/liwenzhou/p/8660826.html 1. 单表增删改查 2. 单表的双下划线操作 3. 外键的跨表查询
1. 正向查询 2. 反向查询
4. 多对多的跨表查询
1. 正向查询 2. 反向查询
5. 分组和聚合 6. F和Q 7. 事务 8. 执行原生SQL语句 饲养员 还让 老母猪 笑话着了。 作业:
把ORM查询操作多写几个例子!!! 后面的项目:
1. BBS 仿博客园 练手的
2. CRM --> 权限系统、Django admin、 Startk组件
3. 路飞学城 --> Django REST Framework(API) --> Vue(MVVM框架)
4. Flask --> 发布系统
5. 爬虫
6. 算法+金融那些
7. Linux
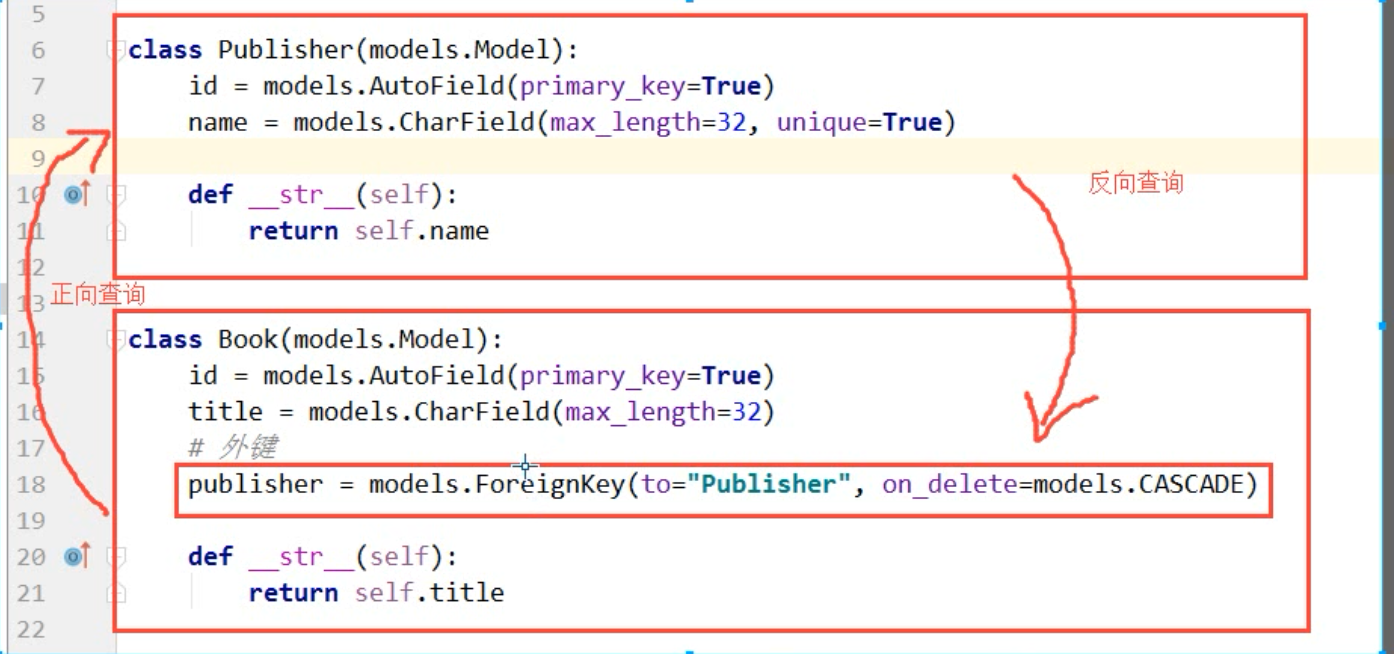
正向与反向查 根据外键
# /usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/9/13 14:19
# @Author : TrueNewBee
"""
如何在一个python脚本或文件中 加载Django项目的配置和变量的信息 ORM 查询的方法
2018-9-13 21:49:26 """
import django
import os
from app001 import models if __name__ == '__main__':
# 加载Django项目的配置信息
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "mysite67.settings")
django.setup()
# 查询所有的人
person = models.Person.objects.all()
print(person)
# get查询 如果查询条件不存在,则会报错
ret = models.Person.objects.get(name='小黑')
print(ret)
# filter 不存在 返回一个空的QuerySet,不会报错
ret = models.Person.objects.filter(name='小黑')
print(ret)
# 就算查询的结果只有一个,返回的也是QuerySet,我们要用索引的方式取出第一个元素
ret = models.Person.objects.filter(id=1)[0]
print(ret)
# exclude
ret = models.Person.objects.exclude(id=1)
print(ret)
print('values'.center(80, "*"))
# values 返回一个QuerySet对象 里面都是字典,不写字段名,默认查询所有字段
ret = models.Person.objects.values("name", "birthday")
print(ret)
print('values_list'.center(80, "*"))
# values 返回一个QuerySet对象 里面都是元组,不写字段名,默认查询所有字段
ret = models.Person.objects.values_list()
print(ret)
print('order_by'.center(80, "*"))
# order_by 按照指定的字段排序
ret = models.Person.objects.all().order_by("birthday")
print(ret)
print('reverse'.center(80, "*"))
# reverse 将一个有序的QuerySet,反转顺序
# 对有序的QuerySet才能调用
ret = models.Person.objects.all().order_by("birthday").reverse()
print(ret)
print('count'.center(80, "*"))
# count 返回QuerySet中对象的数量
ret = models.Person.objects.all().count()
print(ret)
print('first'.center(80, "*"))
# first 返回QuerySet中第一个对象
ret = models.Person.objects.all().first()
print(ret)
print('last'.center(80, "*"))
# last 返回QuerySet中最后一个对象
ret = models.Person.objects.all().last()
print(ret)
print('exists'.center(80, "*"))
# exists 判断表里面有没有数据
ret = models.Person.objects.exists()
print(ret)
# ----------------------------------------------------------------------------------------------------------
# 单标查询之神奇的双下划线
# 查询id值大于1小于4的结果
ret = models.Person.objects.filter(id__gt=1, id__It=4)
print(ret)
# in
# 查询 id在 [1,3,5]中的结果
ret = models.Person.objects.filter(id__in=[1, 3, 5])
print(ret)
# 查询 id不在在 [1,3,5]中的结果
ret = models.Person.objects.exclude(id__in=[1, 3, 5])
print(ret)
# contains 字段包含指定值
# icontains 忽略大小写字段包含指定值
ret = models.Person.objects.exclude(name_contains="小")
print(ret)
# range
# 判断id值在 哪个区间的SQL语句中的between and 1<= <=3
ret = models.Person.objects.filter(id__range=[1, 3])
print(ret)
# 日期和时间字段还可以有以下写法
ret = models.Person.objects.filter(birthday__year=2018)
print(ret)
ret = models.Person.objects.filter(birthday__month=5)
print(ret) # -----------------------------------------------------------------------------------------------
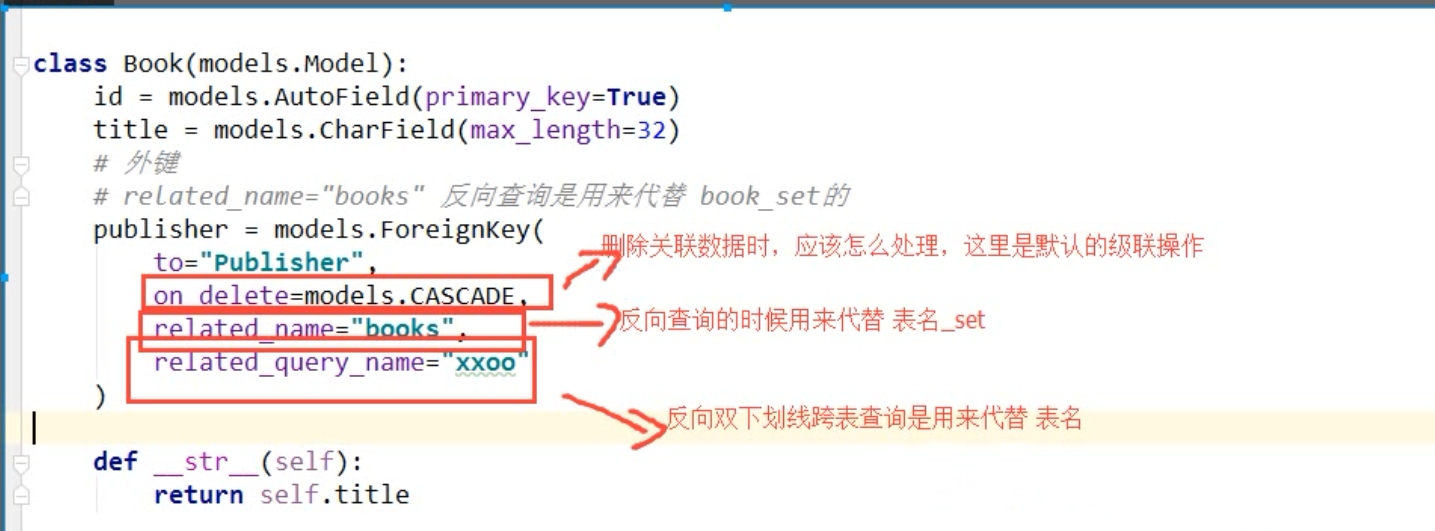
# 外键的查询操作
# 正向查询
# 基于对象, 跨表查询
book_obj = models.Book.objects.all().first()
ret = book_obj.pubilsher # 和我这本书关联的出版社对象
print(ret, type(ret))
ret = book_obj.publisher.name # 和我这本书关联的出版社对象
print(ret, type(ret)) # 查询id是1的书的出版社的名称
# 利用双下划线 跨表查询
# 双下划线就表示垮了一张表
ret = models.Book.objects.filter(id=1).values_list("publisher_name")
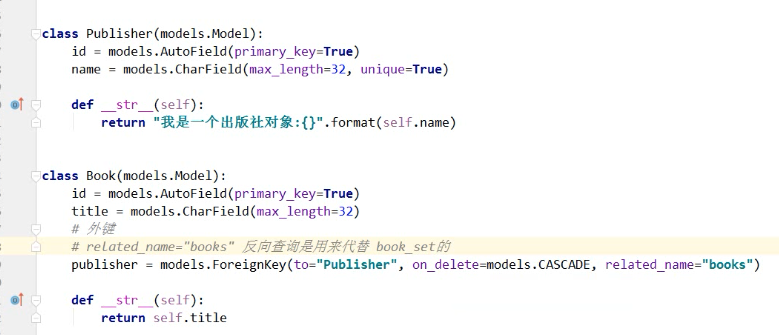
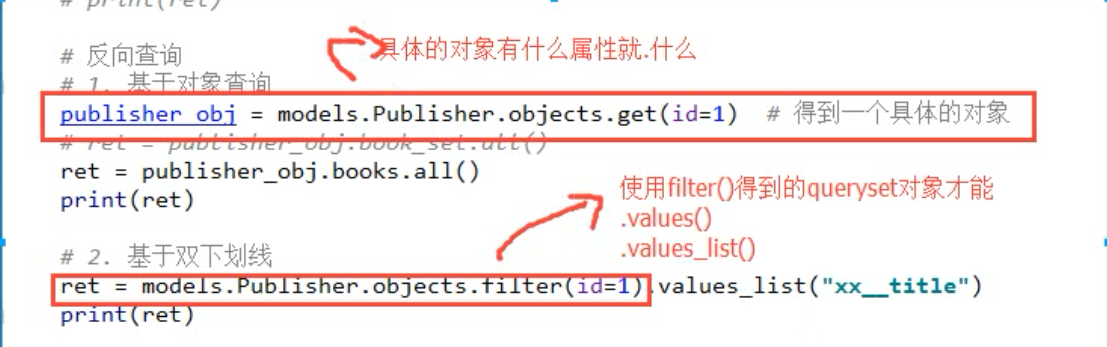
print(ret) # 反向查询
# 1.基于对象查询
publisher_obj = models.Publisher.objects.get(id="") # 得到的是一个具体的对象
ret = publisher_obj.book_set.all()
print(ret)
# 2.基于双下划线
ret = models.Publisher.objects.filter(id=1).values_list("books__title")
print(ret) # -----------------------------------------------------------------------------------------------
# 多对多
# 查询
author_obj = models.Author.objects.first()
print(author_obj)
# 查询金老板写过的书
ret = author_obj.books.all()
# print(author_obj.books, type(author_obj.books))
print(ret)
# 1.create
# 通过作者创建一本书,会自动保存
# 做了两件事
# 1. 在book表中创建了一本新书, 2, 在作者和书得关系列把你中添加关联记录
author_obj.books.create(tittle="金老板自传", publisher_id=2)
# 2.add
# 在金老板关联的书里面,再加一个id是4的书
# book_obj = models.Book.objects.get(id=4)
# author_obj.books.add(book_obj)
# 添加多个
# book_objs = models.Book.objects.filter(id__gt=5)
# author_obj.books.add(*book_objs) # 要把列表打散再传进去
author_obj.books.add(9) # remove
# 从金老板关联的书里面把 开飞船 删掉
book_obj = models.Book.objects.get(title="跟金老板学开飞机")
author_obj.books.remove(book_obj)
# 从金老板关联的书里面把id是8的记录 删掉
# author_obj.books.remove(8) # clear
# 清空
# 把景女神 关联的所有书都删掉
# jing_obj = models.Author.objects.get(id=2)
# jing_obj.books.clear() # 额外补充的, 反键的反向操作
# 找到id是1的出版社
publisher_obj = models.Publisher.objects.get(id=1)
publisher_obj.books.clear() # ----------------------------------------------------------------------------------------------
# 聚合
from django.db.models import Avg, Sum, Max, Min, Count
ret = models.Book.objects.all().aggregate(price_avg=Avg("price"))
print(ret) ret = models.Book.objects.all().aggregate(price_avg=Avg("price"), price_max=Max("price"), price_Min=Min("price")) # ---------------------------------------------------------------------------
# 分组查询
# 查询每一本书的的作者个数
ret = models.Book.objects.all().annotate(author_num=Count("author"))
print(ret)
for book in ret:
print("书名: {}, 作者数量: {}".format(book.title, book.authorr_num)) # -----------------------------------------------------------------------------------------
# 查询各个作者出的书的总价格
# 这是一个对象列表
# ret = models.Author.objects.all().annotate(price_sum=Sum("books_price")).values_list("id", "name", "price_sum")
ret = models.Author.objects.all().annotate(price_sum=Sum("books_price"))
for i in ret:
print(i, i.name, i.price_sum)
print(ret.values_list("id", "name", "price_sum")) # -----------------------------------------------------------------------------
# F和Q
ret = models.Book.objects.filter(price_gt=99.9)
print(ret) # 查询出 库存数 大于 卖出书的 所有书(两个字段作比较)
from django.db.models import F
ret = models.Book.objects.filter(kucun_gt=F("maichu"))
print(ret)
# 刷单 把一本书的卖出数都乘以3
obj = models.Book.objects.first()
obj.maichu = 1000*3
obj.save()
# 具体的对象没有update(), QuerySet对象才有update()
models.Book.objects.update(maichu=F("maichu")*3) # 给每一本书的书名后面加上第一版
from django.db.models.functions import Concat
from django.db.models import Value # models.Book.objects.update(title=Concat(F("title")), Value("第一版")) # ------------------------------------------------------------------------------
# Q查询
from django.db.models import Q
# 查询 卖出数大于1000, 并且, 价格小于100的所有书
ret = models.Book.objects.filter(maichu_gt=1000, price_lt=100)
print(ret) # 查询卖出书大于1000, 或者加个小于100的所有的书
ret = models.Book.objects.filter(Q(maichu_gt=1000)| Q(price_lt=100))
print(ret)
# Q查询和字段查询同时存在时, 字段查询要放在Q查询的后面
ret = models.Book.objects.filter(Q(maichu_gt=1000)| Q(price_lt=100), title_contains="金老板")
print(ret)
9.13Django ORM那些事的更多相关文章
- Python SQLAlchemy --1
本文為 Python SQLAlchemy ORM 一系列教學文: SQLAlchemy 大概是目前 Python 最完整的資料庫操作的套件了,不過最令人垢病的是它的文件真的很難閱讀,如果不搭配個實例 ...
- ORM关于表那些事
一.. ORM表和表之间的关系 1. 一对多 --> 外键(ForeignKey) 2. 多对多 --> 另外一张关系表(ManyToManyField) 1. 三种方式 1. 自己建立第 ...
- 关于django操作orm的一些事--反向生成orm、连接多个数据库
1. django反向生成orm的类代码 使用命令python manage.py inspectdb > app01/models.py,注意,我这里的app01是app的名字. 2.djan ...
- 【Mysql的那些事】数据库之ORM操作
1:ORM的基础操作(必会) <1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> get(* ...
- .NET 开源SqlServer ORM框架 SqlSugar 3.0 API
3.1.x ,将作为3.X系统的最后一个版本,下面将会开发 全新的功能 更新列表:https://github.com/sunkaixuan/SqlSugar/releases 优点: SqlSuga ...
- ORM数据层框架的设计热点:更新指定的列的几种设计方案
ORM框架的定义:对象-关系映射(Object/Relation Mapping,简称ORM) 常见的是:数据库结构=>映射Object(实体属性)=>基于实体类的操作. 还有一种:数据库 ...
- [开源ORM] SqliteSugar 3.x .net Core版本成功上线
SqliteSqlSugar 3.X API 作为支持.NET CORE 为数不多的ORM之一,除了具有优越的性能外,还拥有强大的功能,不只是满足你的增,删,查和改.实质上拥有更多你想像不到的功能,当 ...
- N[开源].NET CORE与MySql更配, MySqlSugar ORM框架 3.x
MySqlSugar 3.X API 作为支持.NET CORE 为数不多的ORM之一,除了具有优越的性能外,还拥有强大的功能,不只是满足你的增,删,查和改.实质上拥有更多你想像不到的功能,当你需要实 ...
- 一个简单得不能再简单的“ORM”了
本文适合初学者,老鸟请点赞即走,谢谢. 文字功底有限,表述不恰当的地方,请各位多多包涵. 一,核心 现在ORM已经很多了,功能也齐全了,大家说我这是干无聊的事,造的连车轮子都还不算,反正我就当学习. ...
随机推荐
- 详解CorelDRAW中如何合并与拆分对象
合并两个或多个对象可以创建带有共同填充和轮廓属性的单个对象,以便将这些对象转换为单个曲线对象.可以合并的对象包括矩形.椭圆形.多边形.星形.螺纹.图形或文本等,本教程将详解CorelDRAW中关于合并 ...
- 关于UIGestureRecognizerState
UIGestureRecognizerState的定义如下 typedef enum { UIGestureRecognizerStatePossible, UIGestureRecognizerSt ...
- Splash 对象属性
args js_enabled resource_timeout images_enabled plugins_enabled scroll_position
- osgearth缓存数据命令
新建一个.bat文件 中国地区 osgearth_package.exe ReadyMap.earth --tms ReadyMap.earth --out D:\APICenter\EarthDat ...
- Unity透明Shader
Shader "Custom/Blocks" { Properties { _Color (,,,) _MainTex ("Albedo (RGB)", 2D) ...
- thinkjs+swagger Editor
一直很好奇专门写接口同事的工作,于是趁着手边工作中的闲暇时间,特地看看神奇的接口文档怎么摆弄. 总览: 这是基于thinkjs(3.0),使用swagger editor编写,实现功能性测试的接口文档 ...
- 【LeetCode OJ】Add Two Numbers
题目:You are given two linked lists representing two non-negative numbers. The digits are stored in re ...
- 一些有用的java 框架
jwt 用于生成web toke的类库 http://jwt.io/ jasypt java加密类库 http://www.jasypt.org/
- SharpGL学习笔记(三) 投影变换和视点变换
从本节开始,我们使用SharpGL带的VS2010扩展,来直接生成SharpGL工程. 如果你新建项目时,没有看到下面的SharpGL项目,那么请事先在SharpGL源代码中找到一个叫 ”SharpG ...
- Android studio 插件安装
安装插件步骤 一 CodeGlance 最大的用途:可用于快速定位代码.显示在右侧 二 Android Studio Prettify 可以将代码中的字符串写在string.xml文件中 选中字符串鼠 ...