Spark Storage(二) 集群下的broadcast
Broadcast 简单来说就是将数据从一个节点复制到其他各个节点,常见用于数据复制到节点本地用于计算,在前面一章中讨论过Storage模块中BlockManager,Block既可以保存在内存中,也可以保存在磁盘中,当Executor节点本地没有数据,通过Driver去获取数据
Spark的官方描述:
A broadcast variable. Broadcast variables allow the programmer to keep a read-only variable
* cached on each machine rather than shipping a copy of it with tasks. They can be used, for
* example, to give every node a copy of a large input dataset in an efficient manner. Spark also
* attempts to distribute broadcast variables using efficient broadcast algorithms to reduce
* communication cost.
在Broadcast中,Spark只是传递只读变量的内容,通常如果一个变量更新会涉及到多个节点的该变量的数据同步更新,为了保证数据一致性,Spark在broadcast 中只传递不可修改的数据。
Broadcast 只是细粒度化到executor? 在storage前面的文章中讨论过BlockID 是以executor和实际的block块组合的,executor 是执行submit的任务的子worker进程,随着任务的结束而结束,对executor里执行的子任务是同一进程运行,数据可以进程内直接共享(内存),所以BroadCast只需要细粒度化到executor就足够了
TorrentBroadCast
Spark在老的版本1.2中有HttpBroadCast,但在2.1版本中就移除了,HttpBroadCast 中实现的原理是每个executor都是通过Driver来获取Data数据,这样很明显的加大了Driver的网络负载和压力,无法解决Driver的单点性能问题。
为了解决Driver的单点问题,Spark使用了Block Torrent的方式。
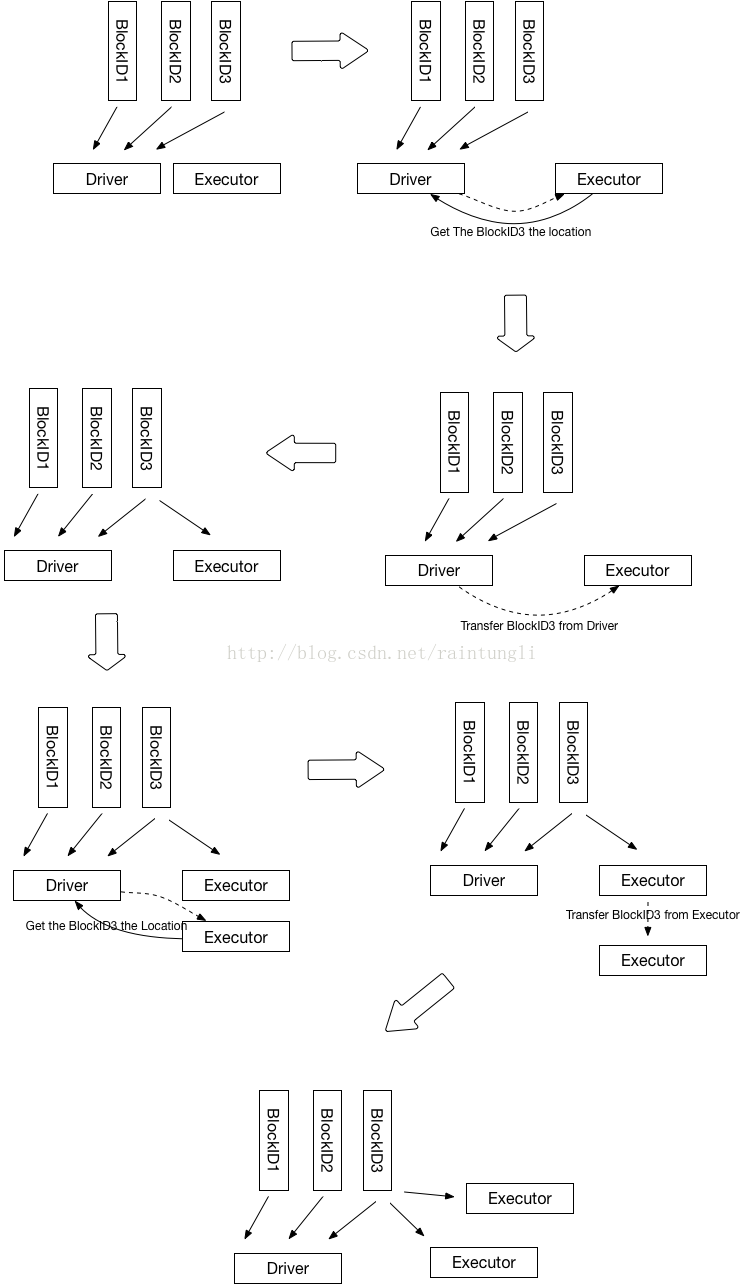
1. Driver 初始化的时候,会知道有几个executor,以及多少个Block, 最后在Driver端会生成block所对应的节点位置,初始化的时候因为executor没有数据,所有块的location都是Driver
2. Executor 进行运算的时候,从BlockManager里的获取本地数据,如果本地数据不存在,然后从driver获取数据的位置
bm.getLocalBytes(pieceId) match {
case Some(block) =>
blocks(pid) = block
releaseLock(pieceId)
case None =>
bm.getRemoteBytes(pieceId) match {
case Some(b) =>
if (checksumEnabled) {
val sum = calcChecksum(b.chunks())
if (sum != checksums(pid)) {
throw new SparkException(s"corrupt remote block $pieceId of $broadcastId:" +
s" $sum != ${checksums(pid)}")
}
}
// We found the block from remote executors/driver's BlockManager, so put the block
// in this executor's BlockManager.
if (!bm.putBytes(pieceId, b, StorageLevel.MEMORY_AND_DISK_SER, tellMaster = true)) {
throw new SparkException(
s"Failed to store $pieceId of $broadcastId in local BlockManager")
}
blocks(pid) = b
case None =>
throw new SparkException(s"Failed to get $pieceId of $broadcastId")
}
3. Driver里保存的块的位置只有Driver自己有,所以返回executer的位置列表只有driver
private def getLocations(blockId: BlockId): Seq[BlockManagerId] = {
if (blockLocations.containsKey(blockId)) blockLocations.get(blockId).toSeq else Seq.empty
}
4. 通过块的传输通道从Driver里获取到数据
blockTransferService.fetchBlockSync(
loc.host, loc.port, loc.executorId, blockId.toString).nioByteBuffer()
5. 获取数据后,使用BlockManager.putBytes ->最后使用doPutBytes保存数据
private def doPutBytes[T](
blockId: BlockId,
bytes: ChunkedByteBuffer,
level: StorageLevel,
classTag: ClassTag[T],
tellMaster: Boolean = true,
keepReadLock: Boolean = false): Boolean = {
.....
val putBlockStatus = getCurrentBlockStatus(blockId, info)
val blockWasSuccessfullyStored = putBlockStatus.storageLevel.isValid
if (blockWasSuccessfullyStored) {
// Now that the block is in either the memory or disk store,
// tell the master about it.
info.size = size
if (tellMaster && info.tellMaster) {
reportBlockStatus(blockId, putBlockStatus)
}
addUpdatedBlockStatusToTaskMetrics(blockId, putBlockStatus)
}
logDebug("Put block %s locally took %s".format(blockId, Utils.getUsedTimeMs(startTimeMs)))
if (level.replication > ) {
// Wait for asynchronous replication to finish
try {
Await.ready(replicationFuture, Duration.Inf)
} catch {
case NonFatal(t) =>
throw new Exception("Error occurred while waiting for replication to finish", t)
}
}
if (blockWasSuccessfullyStored) {
None
} else {
Some(bytes)
}
}.isEmpty
}
6. 在保存数据后同时汇报该Block的状态到Driver
7. Driver更新executor 的BlockManager的状态,并且把Executor的地址加入到该BlockID的地址集合中
private def updateBlockInfo(
blockManagerId: BlockManagerId,
blockId: BlockId,
storageLevel: StorageLevel,
memSize: Long,
diskSize: Long): Boolean = { if (!blockManagerInfo.contains(blockManagerId)) {
if (blockManagerId.isDriver && !isLocal) {
// We intentionally do not register the master (except in local mode),
// so we should not indicate failure.
return true
} else {
return false
}
} if (blockId == null) {
blockManagerInfo(blockManagerId).updateLastSeenMs()
return true
} blockManagerInfo(blockManagerId).updateBlockInfo(blockId, storageLevel, memSize, diskSize) var locations: mutable.HashSet[BlockManagerId] = null
if (blockLocations.containsKey(blockId)) {
locations = blockLocations.get(blockId)
} else {
locations = new mutable.HashSet[BlockManagerId]
blockLocations.put(blockId, locations)
} if (storageLevel.isValid) {
locations.add(blockManagerId)
} else {
locations.remove(blockManagerId)
} // Remove the block from master tracking if it has been removed on all slaves.
if (locations.size == ) {
blockLocations.remove(blockId)
}
true
}
如何实现Torrent?
1. 为了避免Driver的单点问题,在上面的分析中每个executor如果本地不存在数据的时候,通过Driver获取了该BlockId的位置的集合,executor获取到BlockId的地址集合随机化后,优先找同主机的地址(这样可以走回环),然后从随机的地址集合按顺序取地址一个一个尝试去获取数据,因为随机化了地址,那么executor不只会从Driver去获取数据
/**
* Return a list of locations for the given block, prioritizing the local machine since
* multiple block managers can share the same host.
*/
private def getLocations(blockId: BlockId): Seq[BlockManagerId] = {
val locs = Random.shuffle(master.getLocations(blockId))
val (preferredLocs, otherLocs) = locs.partition { loc => blockManagerId.host == loc.host }
preferredLocs ++ otherLocs
}
2. BlockID 的随机化
通常数据会被分为多个BlockID,取决于你设置的每个Block的大小
spark.broadcast.blockSize=10M
在获取完整的BlockID块的时候,在Torrent的算法中,随机化了BlockID
for (pid <- Random.shuffle(Seq.range(, numBlocks))) {
......
}
在任务启动的时候,新启的executor都会同时从driver去获取数据,大家如果都是以相同的Block的顺序,基本上的每个Block数据对executor还是会从Driver去获取, 而BlockID的简单随机化就可以保证每个executor从driver获取到不同的块,当不同的executor在取获取其他块的时候就有机会从其他的executor上获取到,从而分散了对Driver的负载压力。
Spark Storage(二) 集群下的broadcast的更多相关文章
- Spark Storage(一) 集群下的区块管理
Storage模块 在Spark中提及最多的是RDD,而RDD所交互的数据是通过Storage来实现和管理 Storage模块整体架构 1. 存储层 在Spark里,单节点的Storage的管理是通过 ...
- spark高可用集群搭建及运行测试
文中的所有操作都是在之前的文章spark集群的搭建基础上建立的,重复操作已经简写: 之前的配置中使用了master01.slave01.slave02.slave03: 本篇文章还要添加master0 ...
- 用redis实现TOMCAT集群下的session共享
上篇实现了 LINUX中NGINX反向代理下的TOMCAT集群(http://www.cnblogs.com/yuanjava/p/6850764.html) 这次我们在上篇的基础上实现session ...
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- was集群下基于接口分布式架构和开发经验谈
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/luozhonghua2014/article/details/34084935 某b项目是我首 ...
- 如何解决quartz在集群下出现的资源抢夺现象
Quartz是一个开源的作业调度框架,它完全由Java写成,并设计用于J2SE和J2EE应用中.它提供了巨大的灵活性而不牺牲简单性.你能够用它来为执行一个作业而创建简单的或复杂的调度,简单的说就是可以 ...
- Spark on Yarn 集群运行要点
实验版本:spark-1.6.0-bin-hadoop2.6 本次实验主要是想在已有的Hadoop集群上使用Spark,无需过多配置 1.下载&解压到一台使用spark的机器上即可 2.修改配 ...
- 搭建Spark高可用集群
Spark简介 官网地址:http://spark.apache.org/ Apache Spark™是用于大规模数据处理的统一分析引擎. 从右侧最后一条新闻看,Spark也用于AI人工智能 sp ...
- Jenkins集群下的pipeline实战
关于Jenkins集群 在<快速搭建Jenkins集群>一文中,我们借助docker快速搭建了Jenkins集群,今天就在这个集群环境中创建pipeline任务,体验Jenkins集群下的 ...
随机推荐
- Bootstrap学习总结笔记(24)-- 基于BootstrapValidator的Form表单验证
Form表单进行数据验证是十分必要的,我们可以自己写JS脚本或者使用JQuery Validate 插件来实现.对于Bootstrap而言,利用BootstrapValidator来做Form表单验证 ...
- thinkphp3.2 实现点击图片或文字进入内容页
首先要先把页面渲染出来,http://www.mmkb.com/weixiang/index/index.html <div class="main3 mt"> < ...
- jTemplates
jTemplates是一个基于JQuery的模板引擎插件,功能强大,有了他你就再不用为使用JS绑定数据集时发愁了. 首先送上jTtemplates的官网地址:http://jtemplates.tpy ...
- 【WEB前端开发最佳实践系列】高可读的HTML
一.HTML语义化 HTML5中增加了很多标签都是基于此类原则设计的(article nav header footer).页面标签语义化的优点是使得搜索引擎以及第三方抓包工具等更容易读懂页面 ...
- iOS开发中id、NSObject *、id、instancetype四者有什么区别?
在使用Objective-C语言进行iOS应用开发的时候,常常会涉及到id.NSObject *.id.instancetype这四个概念的使用,但这四者也是iOS初学者最易混淆的内容,下面小编看 ...
- 数字模型制作规范(转自Unity3D群)
本文提到的所有数字模型制作,全部是用3D MAX建立模型,即使是不同的驱动引擎,对模型的要求基本是相同的.当一个VR模型制作完成时,它所包含的基本内容包括场景尺寸.单位,模型归类塌陷.命名.节点编辑, ...
- 思科SVI接口和路由接口区别
Cisco多层交换中提到了一个SVI接口,路由接口.在多层交换机上可以将端口配置成不同类型的接口. 其中SVI接口 类似于 interface Vlan10ip address 192.168.20 ...
- Docker 利用registry创建私有仓库
一.Docker-registry镜像 下载地址 官方镜像下载比较慢,因为人品问题一直下载不成功,所以选择了国内的镜像. daocloud: https://hub.daocloud.io/ 还有 ...
- 模拟线程安全的售票案例(java)
package try51.thread.safe; import java.util.ArrayList; import java.util.Random; import java.util.con ...
- iptables、防火墙配置、NAT端口映射
一,配置一个filter表放火墙 (1)查看本机关于IPTABLES的设置情况 [root@tp ~]# iptables -L -n Chain INPUT (policy ACCEPT) targ ...