Spark——共享变量
Spark执行不少操作时都依赖于闭包函数的调用,此时如果闭包函数使用到了外部变量驱动程序在使用行动操作时传递到集群中各worker节点任务时就会进行一系列操作:
1、驱动程序使将闭包中使用变量封装成对象,驱动程序序列化对象,传给worker节点任务;
2、worker节点任务接收到对象,执行闭包函数;
由于使用外部变量势必会通过网络、序列化、反序列化,如外部变量过大或过多使用外部变量将会影响Spark程序的性能;
Spark提供了两种类型的共享变量(Shared Variables):广播变量(Broadcast Variables)、累加器(Accumulators );
广播变量(Broadcast Variables)
Spark提供的广播变量可以解决闭包函数引用外部大变量引起的性能问题;广播变量将只读变量缓存在每个worker节点中,Spark使用了高效广播算法分发变量从而提高通信性能;如直接在闭包函数中使用外部 变量该变量会缓存在每个任务(jobTask)中如果多个任务同时使用了一个大变量势必会影响到程序性能;
广播变量:每个worker节点中缓存一个副本,通过高效广播算法提高传输效率,广播变量是只读的;
Spark Scala Api与Java Api默认使用了Jdk自带序列化库,通过使用第三方或使用自定义的序列化库还可以进一步提高广播变量的性能;
广播变量使用示例:
val sc = SparkContext("");
val eigenValue = sc.bradcast(loadEigenValue())
val eigen = computer.map{x =>
val temp = eigenValue.value
...
...
}
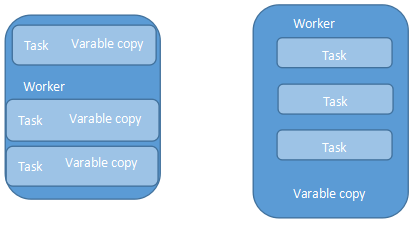
左节点不使用广播变量,右使用广播变量
累加器(Accumulators)
累加器可以使得worker节点中指定的值聚合到驱动程序中,如统计Spark程序执行过程中的事件总数等;
val sc = new SparkContext(...)
val file = sc.textFile("xxx.txt")
val eventCount = sc.accumulator(0,"EventAccumulator") //累加器初始值为0
val formatEvent = file.flatMap(line => {
if(line.contains("error")){
eventCount +=1
}
})
formatEvent.saveAsTextFile("eventData.txt")
println("error event count : " + eventCount);
在使用累加器(Accumulators)时需要注意,只有在行动操作中才会触发累加器,也就是说上述代码中由于flatMap()为转换操作因为Spark惰性特征所以只用当saveAsTextFile() 执行时累加器才会被触发;累加器只有在驱动程序中才可访问,worker节点中的任务不可访问累加器中的值;
Spark原生支持了数字类型的的累加器如:Int、Double、Long、Float等;此外Spark还支持自定义累加器用户可以通过继承AccumulableParam特征来实现自定义的累加器此外Spark还提供了accumulableCollection()累加集合用于;创建累加器时可以使用名字也可以不是用名字,当使用了名字时在Spark UI中可看到当中程序中定义的累加器, 广播变量存储级别为MEMORY_AND_DISK;
文章首发地址:Solinx
http://www.solinx.co/archives/570
Spark——共享变量的更多相关文章
- spark共享变量
boradcast例子代码: scala版本 spark共享变量之Accumulator 例子代码: scala版本
- 7.spark共享变量
spark共享变量 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- Spark共享变量(广播变量、累加器)
转载自:https://blog.csdn.net/Android_xue/article/details/79780463 Spark两种共享变量:广播变量(broadcast variable)与 ...
- SPARK共享变量:广播变量和累加器
Shared Variables Spark does provide two limited types of shared variables for two common usage patte ...
- Spark分布式编程之全局变量专题【共享变量】
转载自:http://www.aboutyun.com/thread-19652-1-1.html 问题导读 1.spark共享变量的作用是什么?2.什么情况下使用共享变量?3.如何在程序中使用共享变 ...
- 9.Spark Streaming
Spark Streaming 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性 ...
- 8.Spark SQL
Spark SQL 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- 5.spark弹性分布式数据集
弹性分布式数据集 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性分布式数据集 ...
- 4.Apache Spark的工作原理
Apache Spark的工作原理 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark ...
随机推荐
- 页面width与height使用百分比来划分不起作用解决办法--记录六
有时候你写 <div style="width:80%;height:100%;border:1px solid red"></div> <div s ...
- git revert和reset区别
1.在github上建立测试项目并克隆到本地 2.本地中新建两个文本文件 3.将a.txt commit并push到远程仓库 执行 git add a.txt, git commit -m " ...
- .NET MVC Razor模板预编译(二)
在前面一片文章:<.NET MVC4 Razor视图预编译(一)> 里面我采用的是PrecompiledMvcViewEngineContrib组件进行预编译视图的虚拟地址注册,但是这个组 ...
- Notepad2替代系统自带的记事本
事情是这样的,平时我经常把一些文字复制到记事本中编辑好了再复制到目标位置,可以在系统自带的记事本中替换删除一些内容,记事本小巧,占用很少的资源,我很喜欢:但今天复制的内容中有很多数字和一些我不想要的内 ...
- Oracle数据库验证IMP导入元数据是否会覆盖历史表数据
场景:imp导入数据时,最终触发器报错退出,并未导入存储过程.触发器.函数. 现在exp单独导出元数据,然后imp导入元数据,验证是否会影响已导入的表数据. 测试环境:CentOS 6.7 + Ora ...
- Peter Hessler和他的中国三部曲(上)
大约一年前,我从<英语铺子>栏目知道了Peter Hessler这位作家.主播分享了她的一些读后感和印象深刻的片段,当然主要是主播的声音太甜了,让我对这位美国作家留下了深刻的印象. Pet ...
- 我为什么要自己编译openjdk8以及那些坑
我为什么要自己编译openjdk8以及那些坑 这是笔者第二次编译openjdk, 第一次编译的是openjdk7,那么好多人会好奇,为什么要自己编译openjdk呢,官方不是已经发布了安装包了么? 要 ...
- 前端开发css实战:使用css制作网页中的多级菜单
前端开发css实战:使用css制作网页中的多级菜单 在日常工作中,大家都会遇到一些显示隐藏类菜单,比如页头导航.二维码显示隐藏.文本提示等等......而这些效果都是可以使用纯css实现的(而且非常简 ...
- 翻译:使用 ASP.NET MVC 4, EF, Knockoutjs and Bootstrap 设计和开发站点 - 3
原文地址:http://ddmvc4.codeplex.com/ 原文名称:Design and Develop a website using ASP.NET MVC 4, EF, Knockout ...
- 学习Redis你必须了解的数据结构——HashMap实现
本文版权归博客园和作者吴双本人共同所有,转载和爬虫请注明原文链接博客园蜗牛 cnblogs.com\tdws . 首先提供一种获取hashCode的方法,是一种比较受欢迎的方式,该方法参照了一位园友的 ...