告别乱码,针对GBK、UTF-8两种编码的智能URL解码器的java实现(转)
效果图
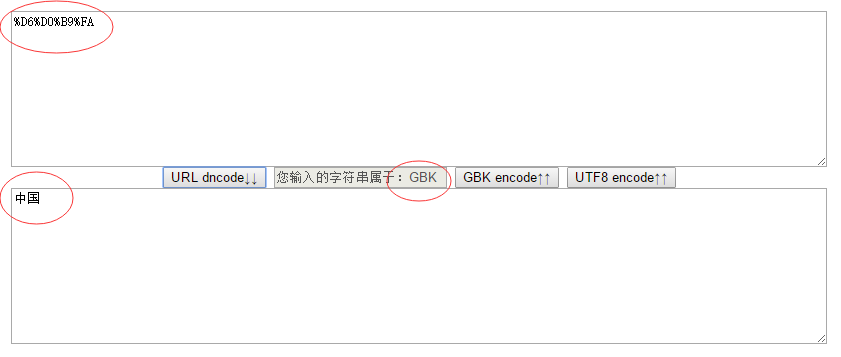
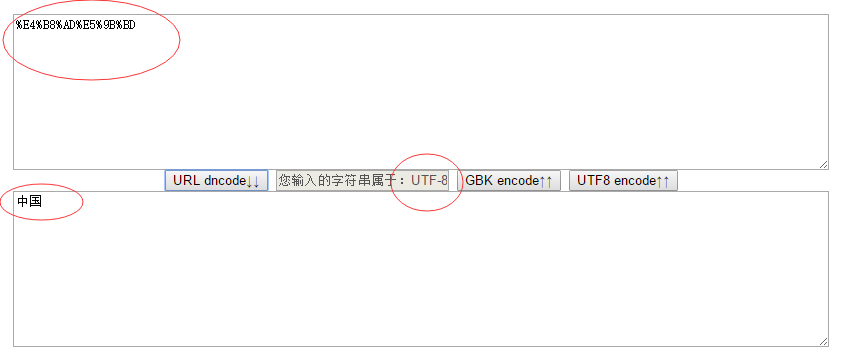
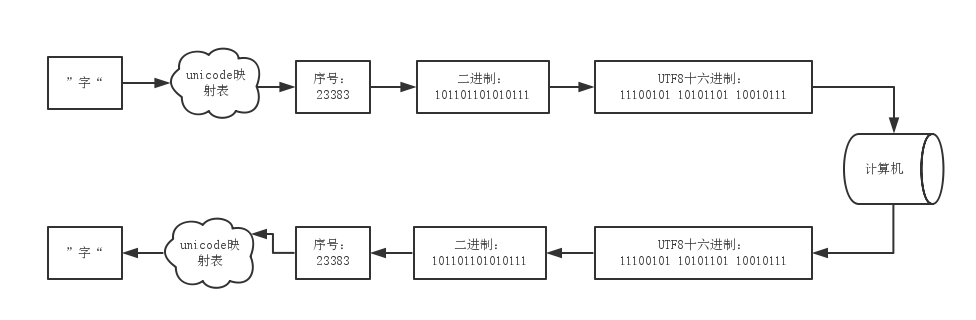
字符
字符是早于计算机而存在,从人类有文明那时起,人们就用一个个符号代表世间万象。如ABC,如“一、二、三”。
字符集
字符集是所有字符的集合。

XXX字符集
给字符集中的每一个字符套上一个序号后的字符集。常见的XXX字符集有ASCLL字符集、Unicode字符集等等,不同种字符集为每个字符编的序号不同,包含的字符数量也不同。
GBK、UTF-8
GBK、UTF-8是一种编码编码格式。当然,你也可以说unicode是一种编码格式,因为它的的确确为每个字符编了一个码,没错,可是unicode的编码完全没有规律,最多只能把其当映射表用。
我们知道,计算机只能识别1和0,假如计算机存储中文字符“字”在硬盘,肯定是存储一串二进制串。
那么问题来了,中文字符【字】在unicode字符集中的序号是23383,那么直接把23383转化成2进制为101101101010111,然后存储在计算机里面,等需要的时候把101101101010111串拿出来,转成23383,再根据unicode映射表,找到中文字符【字】不就好吗?
答案是否定的,如果是这样的话,那计算机怎么知道多少个1、0才代表一个字符呢?所以我们需要一种编码格式,把23383编码成有规律的1、0串,以便计算机读取。
而GBK和UTF-8便是两种不同的有规则的编码格式。
例如:以UTF-8为例子,假如我们所在的环境使用的是unicode字符集,那么“字”在unicode字符集中的序号是23383,转成二进制是101101101010111,使用UTF-8为其编码,以一种特定的算法(下面会具体讲这种算法),把101101101010111转化成11100101 10101101 10010111三个字节的二进制串,再存储到硬盘中,计算机在读取的时候,假如我们指定了让计算机以UTF-8编码格式读取并解码,计算机就会把这三个字节拿出来,倒着转回去,就能得到【字】这个中文字符了。
乱码的根源:
假如我们存储的时候,使用GBK编码格式编码,存储到硬盘,而从硬盘读取出来后,在“倒着转回去”这个步骤却使用UTF-8编码格式转回去,算法不同,那么就可能出现乱码。
如何避免乱码:
以什么编码格式存储,就用什么编码格式解。
但是,假如用户A使用GBK编码对“字”进行编码,而用户B并不知情,也没A的联系方式,跟A约定不了,无法得知硬盘中的数据是以什么编码格式编码的,怎么办呢?
解决乱码的思路:
1、随意使用一种编码格式解码,看解码后的字符串是否乱码,如果是乱码,就用另一种编码格式解码。但该方法可能误判。
2、UTF-8编码格式有一定的规律,我们可以通过正则表达式来验证是否是经过UTF-8编码后的。
JAVA自带检测乱码
1 boolean b = java.nio.charset.Charset.forName("GBK").newEncoder().canEncode(str);
当开始接触这种方法时,原以为java能帮我们判断乱码,就可以高枕无忧了,后来发现,该方法的成功率并不高。
但我们可以先用此方法做第一步检测,如果判断不出来,再使用第2种方法。
UTF-8的编码规律
UTF-8形式的二进制,当一个字节时,两个字节时,三、四、五、六个字节时,都有一定的格式:
| 1字节 | 0xxxxxxx |
| 2字节 | 110xxxxx 10xxxxxx |
| 3字节 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4字节 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 5字节 | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 6字节 | 111111x0 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
很明显,字节数不一样的话,第一个字节是不同的,所以第一个字节可用用来表示该字符究竟占用了多少个字节。
当计算机读取到以0xxxxxxx开头的字节,那么就代表这个字节独自就已经表示某个字符了,计算机将把这个字节单独拿出来解码。
当计算机读取到以110xxxxx开头的字节,那么就代表两个字节才能表示某个字符,计算机就把这个字节以及它后面的一个字节拿出来,代表一个字符进行解码。
……
而除了第一个字节外,后面的字节都是统一的10xxxxxx格式。
有了上面的有规则的格式,按到理我们就可以使用正则表达式来检测一个二进制串是否是UTF-8编码后的串,但代码中操作二进制并不方便,结合URL为16进制的特点,我们可以用正则表达式判断16进制的串。
如何构造正则表达式
我们先看看这种编码格式前一个字节的范围:
| 二进制 | 十六进制 | |
| 1字节 | 00000000~01111111 | 00~7f |
| 2字节 | 11000000~11011111 | c0~df |
| 3字节 | 11100000~11101111 | e0~df |
| 4字节 | 11110000~11110111 | f0~f7 |
| 5字节 | 11111000~11111011 | f8~fb |
| 6字节 | 11111100~11111101 | fc~fd |
以上的范围可用计算机自行验证:
后面格式相同的字节10xxxxxx的范围:
| 10000000~10111111 | 80~bf |
按照这种格式,UTF-8编码格式最多可用用来表示一个1+5*6=31位的二进制串,共使用6个字节。
按照这种规律,我们先练一下手,尝试把“字”转化为UTF-8的十六进制:
java使用的字符集是unicode的,所以我们以unicode为例子。
1、找出“字”在unicdoe字符集中的序号:
|
1
2
3
|
public static void main(String[] args) { System.out.println((int)'字');} |
结果为:23383
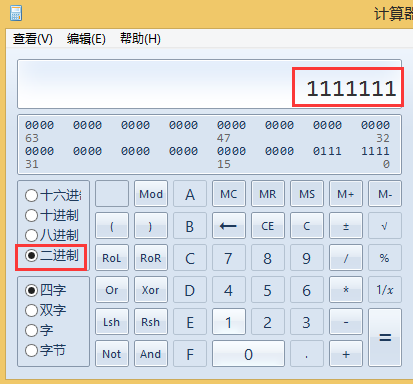
2、把23383转化二进制:
| 23383 | 101101101010111 |
可用看出,二进制共15位,按照UTF-8的编码格式,得用3个字节来表示。
我们把101101101010111从后往前分成三组:101,101101,010111
填充到3字节的UTF-8编码格式中为:
1110xxxx 10xxxxxx 10xxxxxx
11100101 10101101 10010111
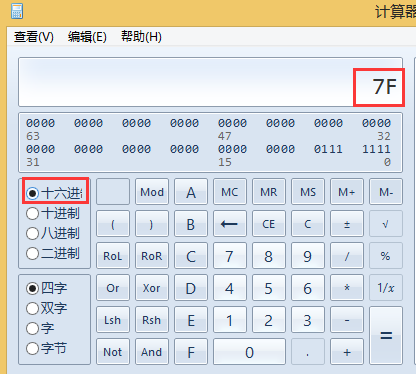
3、使用计算器把二进制转化为16进制为:
OxE5 OxAD Ox97
4、使用网上的工具验证一下,结果吻合,说明这种规律是正确的。
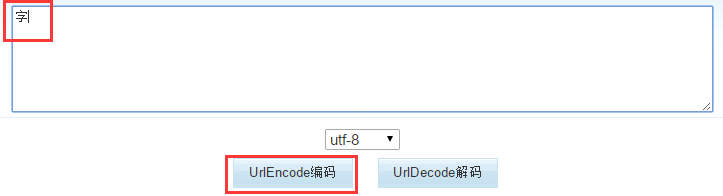
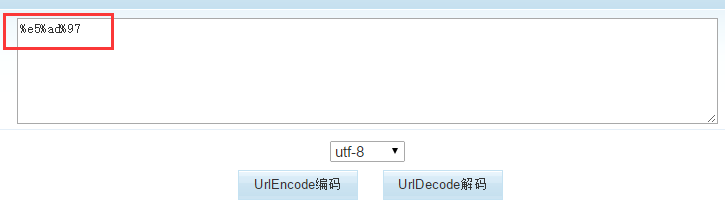
上面已经介绍了UTF-8的规律,那么我们借助强大的正则表达式,就可以判断一个URL串是经过什么编码格式编码的了。
先把上面的表复制下来容易观察:
| 二进制 | 十六进制 | |
| 1字节 | 00000000~01111111 | 00~7f |
| 2字节 | 11000000~11011111 | c0~df |
| 3字节 | 11100000~11101111 | e0~df |
| 4字节 | 11110000~11110111 | f0~f7 |
| 5字节 | 11111000~11111011 | f8~fb |
| 6字节 | 11111100~11111101 | fc~fd |
1字节时:[\\x00-\\x7f]---------------------------------1
2字节时:[\\xc0-\\xdf][\\x80-\\xbf]-------------------2
3字节时:[\\xe0-\\xef][\\x80-\\xbf]{2}--------------3
4字节时:[\\xf0-\\xf7][\\x80-\\xbf]{3}--------------4
5字节时:[\\xf8-\\xfb][\\x80-\\xbf]{4}--------------5
6字节时:[\\xfc-\\xfd][\\x80-\\xbf]{5}--------------6
使用或组合在一起就是:^([\\x00-\\x7f]|[\\xc0-\\xdf][\\x80-\\xbf]|[\\xe0-\\xef][\\x80-\\xbf]{2}|[\\xf0-\\xf7][\\x80-\\xbf]{3}|[\\xf8-\\xfb][\\x80-\\xbf]{4}|[\\xfc-\\xfd][\\x80-\\xbf]{5})+$
判断过程是这样子的:例如【字】经过UTF-8编码后,为:%e5 %ad %97,共3个字节,符合第3字节的情况,第一个字节e5在[\\xe0-\\xef]范围内,后两个字节ad和97都在[\\x80-\\xbf]范围内。
所以我们可以说这个字符是经过UTF-8编码的。我们就可以使用UTF-8编码格式对其进行解码了。
java代码如下:

1 protected static final Pattern utf8Pattern = Pattern.compile("^([\\x00-\\x7f]|[\\xc0-\\xdf][\\x80-\\xbf]|[\\xe0-\\xef][\\x80-\\xbf]{2}|[\\xf0-\\xf7][\\x80-\\xbf]{3}|[\\xf8-\\xfb][\\x80-\\xbf]{4}|[\\xfc-\\xfd][\\x80-\\xbf]{5})+$");
2 Matcher matcher = utf8Pattern.matcher(pureValue);
3 if (matcher.matches()) {
4 return "UTF-8";
5 } else {
6 return "GBK";
7 }
缺陷
使用上面的方法,貌似没什么问题,不过GBK编码后是以两个两个字节呈现的,而UTF-8也有两个字节的情况,所以当一个字符经GBK编码后,转化为16进制,而刚好这个16进制的范围落入UTF-8的两个字节的范围,那么就会被误判成UTF-8,从而导致解码错误。那真的有可能会出现这种情况吗?
答案是会的,我们查看下GBK简体中文编码表。
发现有一部分范围落入了UTF-8的二进制范围了。
从:

一直到:

即UTF-8十六进制中两个字节的范围[\\xc0-\\xdf][\\x80-\\xbf],GBK都有。
例如上面表的第二个中文【愧】,愧的GBK十六进制是C0 A0,那么完全符合UTF-8正则表达式中二字节的[\\xc0-\\xdf][\\x80-\\xbf]这个判断,所以会被误认为是UTF-8编码。
注:该缺陷第一次看,是在下方“参考"的第一篇博客里,尝试了一下,的确有缺陷。
尝试修复缺陷
根据下面"参考"的第一篇博客,修复的思路是把重复的区域都认为是GBK编码。
我们截取正则表达式的前两种情况(一字节、二字节的情况)来排除:^([\\x01-\\x7f]|[\\xc0-\\xdf][\\x80-\\xbf])+$
假如某个16进制串match该正则表达式,就认为是GBK编码的。
修改后的代码为:
1 protected static final Pattern utf8Pattern = Pattern.compile("^([\\x01-\\x7f]|[\\xc0-\\xdf][\\x80-\\xbf]|[\\xe0-\\xef][\\x80-\\xbf]{2}|[\\xf0-\\xf7][\\x80-\\xbf]{3}|[\\xf8-\\xfb][\\x80-\\xbf]{4}|[\\xfc-\\xfd][\\x80-\\xbf]{5})+$");
2 protected static final Pattern publicPattern = Pattern.compile("^([\\x01-\\x7f]|[\\xc0-\\xdf][\\x80-\\xbf])+$");
3 Matcher publicMatcher = publicPattern.matcher(str);
4 if(publicMatcher.matches()) {
5 return "GBK";
6 }
7
8 Matcher matcher = utf8Pattern.matcher(str);
9 if (matcher.matches()) {
10 return "UTF-8";
11 } else {
12 return "GBK";
13 }
又一缺陷
但这样一来,原本是一个字节或两字节,且是UTF-8编码的,就会被误判为GBK。。。
但是,这总比被误判成UTF-8好,因为我们查看Unicode编码表:
可以发现,第一个中文是“一”,转化为UTF-8的话已经排到3个字节去了,所以2个字节内不会出现中文。
但是GBK中,中文是两个字节的。
所以,采用上面的修复缺陷的方法,可以保证中文不会乱码。对于某些网站,只需保证中文不会乱码即可,比如说国内的各种中文购物网站。这些网站中商品的标题一般都是中文的,用户一般以中文搜索,我们尽可能保证中文不乱码即可。
所以,该技术还是有一定用处的。
参考
1、http://www.cnblogs.com/chengmo/archive/2011/02/19/1958657.html
2、http://www.cnblogs.com/chengmo/archive/2010/10/30/1864004.html
4、GBK简体中文表
http://www.cnblogs.com/xiaoMzjm/p/4648175.html
告别乱码,针对GBK、UTF-8两种编码的智能URL解码器的java实现(转)的更多相关文章
- GB2312、GBK和UTF-8三种编码以及QT中文显示乱码问题
1.GB2312.GBK和UTF-8三种编码的简要说明 GB2312.GBK和UTF-8都是一种字符编码,除此之外,还有好多字符编码.只是对于我们中国人的应用来说,用这三种编码 比较多.简单的说一下, ...
- jmeter随笔(9)--有两种编码风格,导致数据乱码
问题:在一个网站,有两种编码风格,导致数据乱码 解决办法: 1.首先设置jmeter的配置文件 2.针对要求是utf-8格式的这样的请求,做单独的编码处理(beanshell处理) 3.运行,在htm ...
- 两种“新型”的javaweb后门(jspx和Java Logger)
利用这个可以突破st2下 强制jsp跳转login.jsp 利用jspx解决jsp后缀被限制拿shell - Hack Blog | 黑客博客http://www.hackblog.cn/post ...
- ajax乱码问题 服务端 客户端 两种的解决方案--转载
今天弄了一天的Ajax中文乱码问题,Ajax的乱码问题分为两种: 1. JavaScript输出的中文乱码, 比如:alert("中文乱码测试"); 2. 这第二种就是Ajax从服 ...
- 【转】GB2312、GBK和UTF-8三种编码的简要说明
原文地址:http://www.cnblogs.com/hust-yingjie/p/5481966.htmlGB2312.GBK和UTF-8都是一种字符编码,除此之外,还有好多字符编码.只是对于我们 ...
- 两种语言实现设计模式(C++和Java)(一:工厂模式)
本篇开始记录实现设计模式在工作中的两种常见语言上的实现. 本篇介绍最简单的工厂模式. 工厂模式有一种非常形象的描述,建立对象的类就如一个工厂,而需要被建立的对象就是一个个产品:在工厂中加工产品,使用产 ...
- 两种语言实现设计模式(C++和Java)(三:策略模式)
策略模式是指定义一系列的算法,把它们一个个封装起来,并且使它们可相互替换.本模式使得算法可独立于使用它的客户而变化.也就是说这些算法所完成的功能一样,对外的接口一样,只是各自实现上存在差异.用策略模式 ...
- LR 两种录制:html与url
一直在使用LR,对于Html_based script和Url-based script 两种录制方式之间,要如何选择,仍是一知半解.最近测试时遇到同样的业务功能,两种录制方式的脚本,单次执行时间差别 ...
- TreeSet的两种实现方法:Comparable和Comparator(Java比较器)
Comparable与Comparator实际上是TreeSet集合的两种实现方式,用来实现对象的排序.下边介绍一下两种比较器的使用方法和区别. Comparable称为元素的自然顺序,或者叫做默认顺 ...
随机推荐
- http://www.shengshiyouxi.com
android从Linux系统启动有4个步骤: (1) init进程启动 (2) Native服务启动 (3) System Server,Android服务启动 (4) Home启动 ...
- 基于FP-Tree的关联规则FP-Growth推荐算法Java实现
基于FP-Tree的关联规则FP-Growth推荐算法Java实现 package edu.test.ch8; import java.util.ArrayList; import java.util ...
- 【剑指offer】面试题24:二叉搜索树的兴许前序遍历序列
分析: 前序: 根 左 右 后序: 左 由 根 二叉搜索树: 左 < 根 < 右 那么这就非常明显了. def ifpost(postArray, start, end): #one or ...
- HTML5之画布的拖拽/拖放
<!DOCTYPE HTML> <html> <head> <script type="text/javascript"> func ...
- TCP、UDP和HTTP
先来一个讲TCP.UDP和HTTP关系的 1.TCP/IP是个协议组,可分为三个层次:网络层.传输层和应用层. 在网络层有IP协议.ICMP协议.ARP协议.RARP协议和BOOTP协议. 在传输层中 ...
- 图画(txt等一下)实施开放的默认下载的默认浏览器,而不是(Java文本)
在网络上,假设我们超链接地址对应于jpg档,txt档,点击链接,默认浏览器打开这些文件,而不是下载,那么,你如何实现竞争力的默认下载. 1.可通过自己写一个download.jsp来实现 <%@ ...
- PHP Html 弹窗,本页面弹窗子页面
echo '<script type=text/javascript>window.open("","name1","width=100, ...
- Android该HTTP下载
今天学习了Android开发中比較难的一个环节,就是断点续传下载,非常多人看到这个标题就感觉头大.的确,假设没有良好的逻辑思维,这块的确非常难搞明确.以下我就将自己学到的知识和一些见解写下供那些在这个 ...
- Xamarin for android:为button设置click事件的几种方法
原文:Xamarin for android:为button设置click事件的几种方法 在Xamarin中一个最基础的事情,就是为一个button指定click事件处理方法,可是即使是这么一件事也有 ...
- Intent有可能的使用(两)
Intent作为联系各Activity之间的纽带,其作用并不只只限于简单的数据传递. 通过其自带的属性.事实上能够方便的完毕非常多较为复杂的操作. 比如直接调用拨号功能.直接自己主动调用合适的程序打开 ...