利用caffe的solverstate断点训练
你可以从系统 /tmp 文件夹获取,名字是什么 caffe.ubuntu.username.log.INFO.....之类
===============================================================================================================
caffe在训练的时候不仅会保存当前模型的参数(也就是caffemodel)文件,也会把训练到当前状态信息全部保存下来,这个文件就是solverstate文件。只要在训练的时候加上snapshot参数就可以了。例子:
1 |
./build/tools/caffe train --solver=models/bvlc_reference_caffenet/solver.prototxt --snapshot=models/bvlc_reference_caffenet/caffenet_train_iter_10000.solverstate |
Training Curve
The following curve is ResNet-v2 trainined on imagenet-1k, all the training detail you can found here, which include gpu information, lr schedular, batch-size etc, and you can also see the training speed with the corresponding logs.

you can get the curve by run:cd log && python plot_curve.py --logs=resnet-18.log,resnet-34.log,resnet-50.log,resnet-101.log,resnet-152.log,resnet-200.log
在caffe的训练过程中,大家难免想图形化自己的训练数据,以便更好的展示结果。如 果自己写代码记录训练过程的数据,那就太麻烦了,caffe中其实已经自带了这样的小工具 caffe-master/tools/extra/parse_log.sh caffe-master/tools/extra/extract_seconds.py和 caffe-master/tools/extra/plot_training_log.py.example ,使用方法如下:
1.记录训练日志
在训练过程中的命令中加入一行参数 ,实现Log日志的记录
已测:
sudo GLOG_logtostderr=0 GLOG_log_dir=/home/jz/caffe-master/JZ/bvlc_googlenet/log/ ./build/tools/caffe train -solver JZ/bvlc_googlenet/solver.prototxt -weights JZ/bvlc_googlenet/googlenet_dog_iter5000.caffemodel -gpu 0
GLOG_logtostderr=0 GLOG_log_dir=/home/liuyun/caffe/models/AAA/A12/Log/ \
/home/liuyun/caffe/build/tools/caffe train -solver examples/AAA/solver.prototxt -weights ./models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel
其中目录改成自己系统的目录,这样训练结束之后,会在Log文件夹中生成每次训练的Log日志。
2.解析训练日志
将最上面说的3个脚本文件拷贝到Log 文件夹下,执行:
|
1
|
./parse_log.sh caffe.liuyun-860-088cn.root.log.INFO.20160830-090533.5367 |
这样就会在当前文件夹下生成一个.train文件和一个.test文件
3.生成图片
执行:
|
1
|
./plot_training_log.py.example 6 train_loss.png caffe.liuyun-860-088cn.root.log |
注意:一定将caffe.liuyun-860-088cn.root.log.INFO.20160830-090533.5367改为caffe.liuyun-860-088cn.root.log,.log为后缀。
就可以生成训练过程中的Train loss vs. Iters 曲线,其中6代表曲线类型, train_loss.png 代表保存的图片名称
caffe中支持很多种曲线绘制,通过指定不同的类型参数即可,具体参数如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
Notes: 1. Supporting multiple logs. 2. Log file name must end with the lower-cased ".log". Supported chart types: 0: Test accuracy vs. Iters 1: Test accuracy vs. Seconds 2: Test loss vs. Iters 3: Test loss vs. Seconds 4: Train learning rate vs. Iters 5: Train learning rate vs. Seconds 6: Train loss vs. Iters 7: Train loss vs. Seconds |
最后,看一下效果:

以下内容转自:http://www.sohu.com/a/136192329_470008
感谢冯超!!!
本文为大数据杂谈4月20日微信社群分享内容整理。
今天的目标是使用Caffe完成深度学习训练的全过程。Caffe是一款十分知名的深度学习框架,由加州大学伯克利分校的贾扬清博士于2013年在Github上发布。自那时起,Caffe在研究界和工业界都受到了极大的关注。Caffe的使用比较简单,代码易于扩展,运行速度得到了工业界的认可,同时还有十分成熟的社区。
对于刚开始学习深度学习的同学来说,Caffe是一款十分十分适合的开源框架。可其他同类型的框架,它又一个最大的特点,就是代码和框架比较简单,适合深入了解分析。今天将要介绍的内容都是Caffe中成型很久的内容,如今绝大多数版本的Caffe都包含这些功能。关于Caffe下载和安装的内容请各位根据官方网站指导进行下载和安装,这里就不再赘述了。
一个常规的监督学习任务主要包含训练与预测两个大的步骤,这里还是以Caffe中自带的例子——MNIST数据集手写数字识别为例,来介绍一下它具体的使用方法。
如果把上面提到的深度学习训练步骤分解得更细致一些,那么这个常规流程将分成这几个子步骤:
数据预处理(建立数据库)
网络结构与模型训练的配置
训练与在训练
训练日志分析
预测检验与分析
性能测试
下面就来一一介绍。
1 数据预处理
首先是训练数据和预测数据的预处理。这里的工作一般是把待分析识别的图像进行简单的预处理,然后保存到数据库中。为什么要完成这一步而不是直接从图像文件中读取数据呢?因为实际任务中训练数据的数量可能非常大,从图像文件中读取数据并进行初始化的效率是非常低的,所以很有必要把数据预先保存在数据库中,来加快训练的节奏。
以下的操作将全部在终端完成。第一步是将数据下载到本地,好在MNIST的数据量不算大,如果大家的网络环境好,这一步的速度会非常快。首先来到caffe的安装根目录——CAFFE_HOME,然后执行下面的命令:
cd data/mnist./get_mnist.sh
程序执行完成后,文件夹下应该会多出来四个文件,这四个文件就是我们下载的数据文件。第二步我们需要调用example中的数据库创建程序:
cd $CAFFE_HOME./examples/mnist/create_mnist.sh
程序执行完成后,examples/mnist文件夹下面就会多出两个文件夹,分别保存了MNIST的训练和测试数据。值得一提的是,数据库的格式可以通过修改脚本的BACKEND变量来更换。目前数据库有两种主流选择:
LevelDB
LmDB
这两种数据库在存储数据和操纵上有一些不同,首先是它们的数据组织方式不同,这是LevelDB的内容:
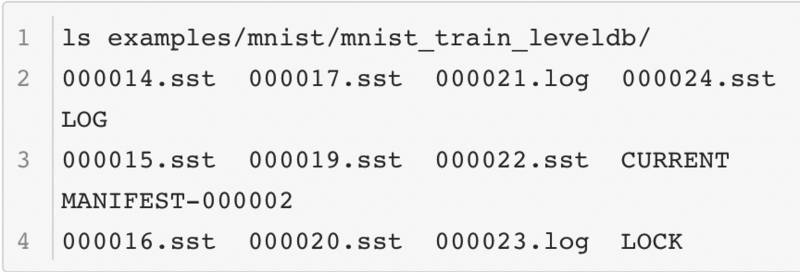
这是LMDB的内容:

从结构可以看出LevelDB的文件比较多,LMDB的文件更为紧凑。
其次是它们的读取数据的接口,某些场景需要遍历数据库完成一些原始图像的分析处理,因此了解它们的数据读取方法也十分有必要。首先是LMDB读取数据的代码:

其次是LevelDB读取的代码:
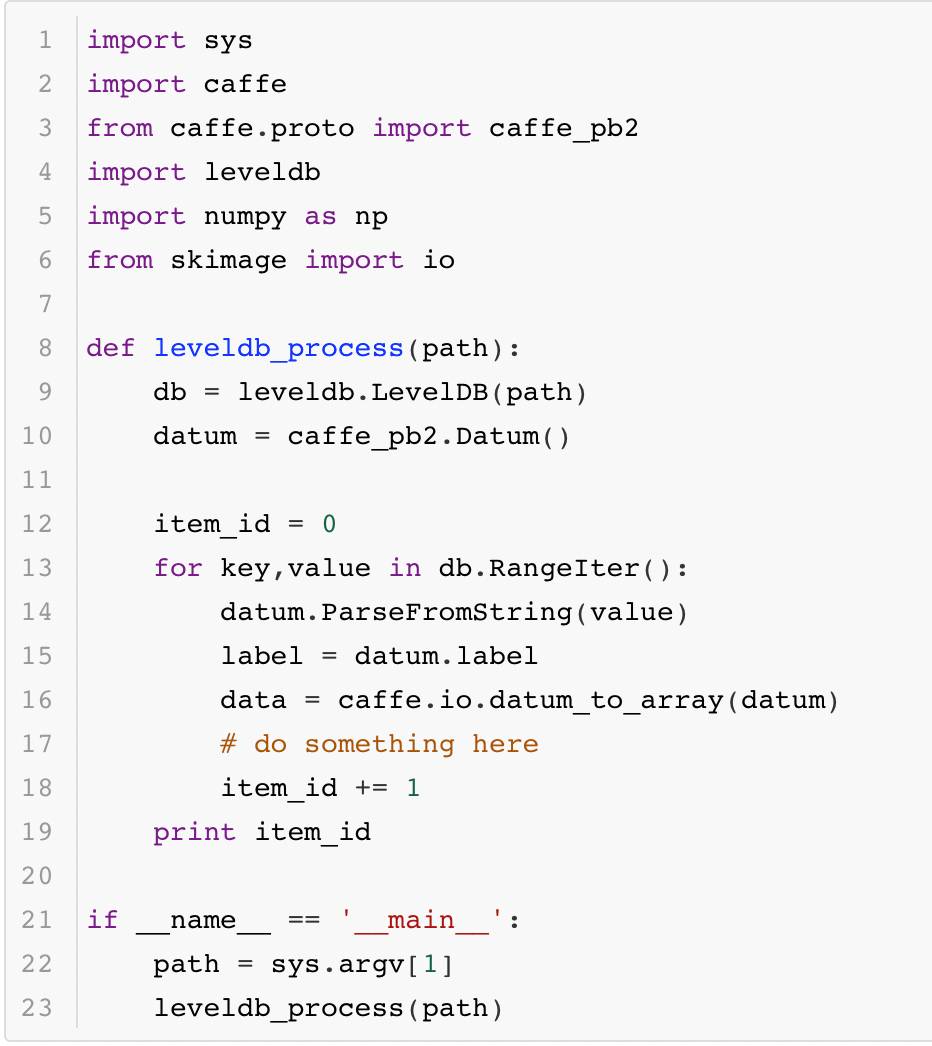
最后回到本小节的问题:为什么要采用数据库的方式存储数据而不是直接读取图像?这里可以简单测试一下用MNIST数据构建的这两个数据库按序读取的速度,这里用系统函数time进行计时,结果如下:
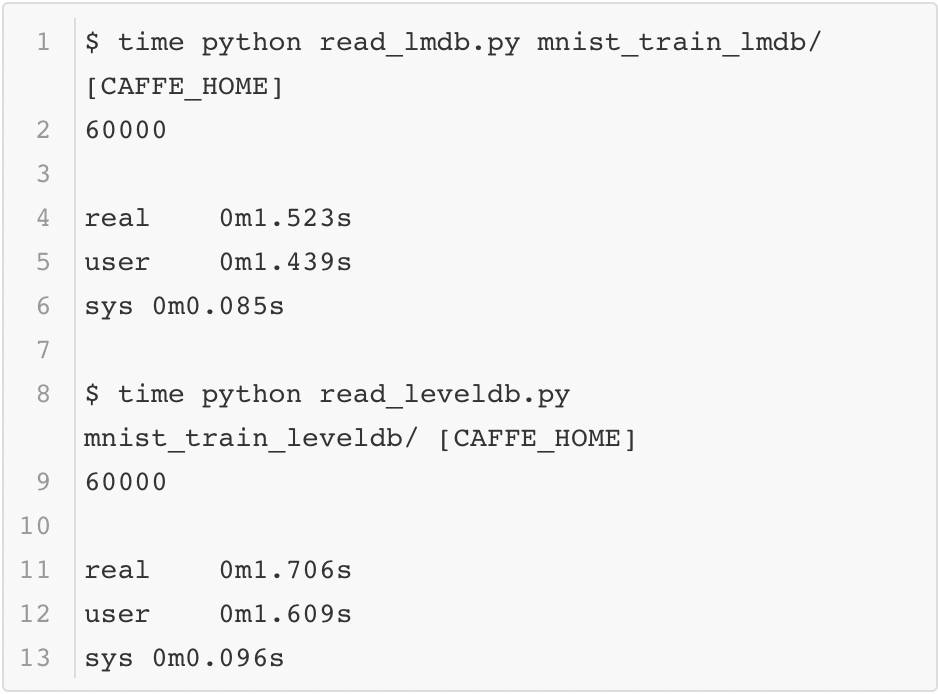
为了比较原始图像读入的速度,这里将MNIST的数据以jpeg的格式保存成图像,并测试它的读取效率(以Caffe python使用的scikit image为例),代码如下所示:

最终的时间如下所示:

由此可以看出,原始图像和数据库相比,读取数据的效率差距还是蛮大的。虽然在Caffe训练中数据读入是异步完成的,但是它还是不能够太慢,所以这也是在训练时选择数据库的原因。
至于这两个数据库之间的比较,这里就不再多做了。感兴趣的各位可以在一些大型的数据集上做一些实验,那样更容易看出两个数据集之间的区别。
2 网络结构与模型训练的配置
上一节完成了数据库的创建,下面就要为训练模型做准备了。一般来说Caffe采用读入配置文件的方式进行训练。Caffe的配置文件一般由两部分组成:solver.prototxt和net.prototxt(有时会有多个net.prototxt)。它们实际上对应了Caffe系统架构中两个十分关键的实体——网络结构Net和求解器Solver。先来看看一般来说相对简短的solver.prototxt的内容,为了方便大家理解,所有配置信息都已经加入了注释:

为了方便大家理解,这里将examples/mnist/lenet_solver.prototxt中的内容进行重新排序,整个配置文件相当于回答了下面几个问题:
网络结构的文件在哪?
用什么计算资源训练?CPU还是GPU?
训练多久?训练和测试的比例是如何安排的,什么时候输出些给我们瞧瞧?
优化的学习率怎么设定?还有其他的优化参数——如动量和正则呢?
要时刻记得存档啊,不然大侠得从头来过了……
接下来就是net.prototxt了,这里忽略了每个网络层的参数配置,只把表示网络的基本结构和类型配置展示出来:
name: "LeNet"layer { name: "mnist" type: "Data" top: "data" top: "label"}layer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1"}layer { name: "pool1" type: "Pooling" bottom: "conv1" top: "pool1"}layer { name: "conv2" type: "Convolution" bottom: "pool1" top: "conv2"}layer { name: "pool2" type: "Pooling" bottom: "conv2" top: "pool2"}layer { name: "ip1" type: "InnerProduct" bottom: "pool2" top: "ip1"}layer { name: "relu1" type: "ReLU" bottom: "ip1" top: "ip1"}layer { name: "ip2" type: "InnerProduct" bottom: "ip1" top: "ip2"}layer { name: "loss" type: "SoftmaxWithLoss" bottom: "ip2" bottom: "label" top: "loss"}
这里只展示了网络结构的基础配置,也占用了大量的篇幅。一般来说,这个文件中的内容超过100行都是再常见不过的事。而像大名鼎鼎的ResNet网络,它的文件长度通常在千行以上,更是让人难以阅读。那么问题来了,那么大的网络文件都是靠人直接编辑出来的么?不一定。有的人会比较有耐心地一点点写完,而有的人则不会愿意做这样的苦力活。实际上Caffe提供了一套接口,大家可以通过写代码的形式生成这个文件。这样一来,编写模型配置的工作也变得简单不少。下面展示了一段生成LeNet网络结构的代码:

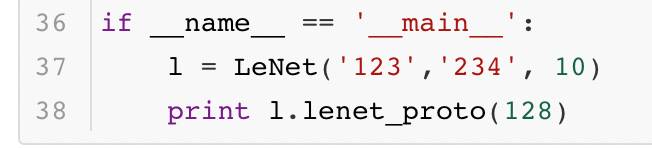
最终生成的结果大家都熟知,这里就不给出了。
layer { name: "data" type: "Data" top: "data" top: "label" transform_param { scale: 0.00390625 mirror: false } data_param { source: "123" batch_size: 128 backend: LMDB }}layer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1" convolution_param { num_output: 20 kernel_size: 5 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" } }}layer { name: "pool1" type: "Pooling" bottom: "conv1" top: "pool1" pooling_param { pool: MAX kernel_size: 2 stride: 2 }}layer { name: "conv2" type: "Convolution" bottom: "pool1" top: "conv2" convolution_param { num_output: 50 kernel_size: 5 stride: 1 weight_filler { type: "xavier" } bias_filler { type: "constant" } }}layer { name: "pool2" type: "Pooling" bottom: "conv2" top: "pool2" pooling_param { pool: MAX kernel_size: 2 stride: 2 }}layer { name: "ip1" type: "InnerProduct" bottom: "pool2" top: "ip1" inner_product_param { num_output: 500 weight_filler { type: "xavier" } bias_filler { type: "constant" } }}layer { name: "relu1" type: "ReLU" bottom: "ip1" top: "ip1"}layer { name: "ip2" type: "InnerProduct" bottom: "ip1" top: "ip2" inner_product_param { num_output: 10 weight_filler { type: "xavier" } bias_filler { type: "constant" } }}layer { name: "loss" type: "SoftmaxWithLoss" bottom: "ip2" bottom: "label" top: "loss"}
大家可能觉得上面的代码并没有节省太多篇幅,实际上如果将上面的代码模块化做得更好些,它就会变得非常简洁。这里就不做演示了,欢迎大家自行尝试。
3 训练与再训练
准备好了数据,也确定了训练相关的配置,下面正式开始训练。训练需要启动这个脚本:

然后经过一段时间的训练,命令行产生了大量日志,训练过程也宣告完成。这时训练好的模型目录多出了这几个文件:

很显然,这几个文件保存了训练过程中的一些内容,那么它们都是做什么的呢?*caffemodel*文件保存了caffe模型中的参数,*solverstate*文件保存了训练过程中的一些中间结果。保存参数这件事情很容易想象,但是保存训练中的中间结果就有些抽象了。solverstate里面究竟保存了什么?回答这个问题就需要找到solverstate的内容定义,这个定义来自src/caffe/proto/caffe.proto文件:

从定义中可以很清楚的看出其内容的含义。其中history是一个比较有意思的信息,他存储了历史的参数优化信息。这个信息有什么作用呢?由于很多算法都依赖历史更新信息,如果有一个模型训练了一半停止了下来,现在想基于之前训练的成果继续训练,那么需要历史的优化信息帮助继续训练。如果模型训练突然中断训练而历史信息又丢失了,那么模型只能从头训练。这样的深度学习框架就不具备“断点训练”的功能了,只有"重头再来"的功能。现在的大型深度学习模型都需要很长的时间训练,有的需要训练好几天,如果框架不提供断点训练的功能,一旦机器出现问题导致程序崩溃,模型就不得不重头开始训练,这会对工程师的身心造成巨大打击……所以这个存档机制极大地提高了模型训练的可靠性。
从另一个方面考虑,如果模型训练彻底结束,这些历史信息就变得无用了。caffemodel文件需要保存下来,而solverstate这个文件可以被直接丢弃。因此这种分离存储的方式特别方便操作。
从刚才提到的“断点训练”可以看出,深度学习其实包含了“再训练”这个概念。一般来说“再训练”包含两种模式,其中一种就是上面提到的“断点训练”。从前面的配置文件中可以看出,训练的总迭代轮数是10000轮,每训练5000轮,模型就会被保存一次。如果模型在训练的过程中被一些不可抗力打断了(比方说机器断电了),那么大家可以从5000轮迭代时保存的模型和历史更新参数恢复出来,命令如下所示:

这里不妨再深入一点分析。虽然模型的历史更新信息被保存了下来,但当时的训练场景真的被完全恢复了么?似乎没有,还有一个影响训练的关键因素没有恢复——数据,这个是不容易被训练过程精确控制的。也就是说,首次训练时第5001轮迭代训练的数据和现在“断点训练”的数据是不一样的。但是一般来说,只要保证每个训练批次(batch)内数据的分布相近,不会有太大的差异,两种训练都可以朝着正确的方向前进,其中存在的微小差距可以忽略不计。
第二种“再训练”的方式则是有理论基础支撑的训练模式。这个模式会在之前训练的基础上,对模型结构做一定的修改,然后应用到其他的模型中。这种学习方式被称作迁移学习(Transfer Learning)。这里举一个简单的例子,在当前模型训练完成之后,模型参数将被直接赋值到一个新的模型上,然后让这个新模型重头开始训练。这个操作可以通过下面这个命令完成:

执行命令后Caffe会像往常一样开始训练并输出大量日志,但是在完成初始化之后,它会输出这样一条日志:

这条日志就是在告诉我们,当前的训练是在这个路径下的模型上进行"Finetune"。
4 训练日志分析
训练过程中Caffe产生了大量的日志,这些日志包含很多训练过程的信息,非常很值得分析。分析的内容有很多,其中之一就是分析训练过程中目标函数loss的变化曲线。在这个例子中,可以分析随着迭代轮数不断增加,Softmax Loss的变化情况。首先将训练过程的日志信息保存下来,比方说日志信息被保存到mnist.log文件中,然后用下面的命令可以将Iteration和Loss的信息提取并保存下来:

提取后的信息可以用另一个脚本完成Loss曲线的绘图工作:
import matplotlib.pyplot as pltx = []y = []with open('loss_data') as f: for line in f: sps = line[:-1].split() x.append(int(sps[0])) y.append(float(sps[1]))plt.plot(x,y)plt.show()
结果如图1所示,可见Loss很快就降到了很低的地方,模型的训练速度很快。这个优异的表现可以说明很多问题,但这里就不做过多地分析了。

除此之外,日志中输出的其他信息也可以被观察分析,比方说测试环节的精确度等,它们也可以通过上面的方法解析出来。由于采用的方法基本相同,这里有不去赘述了,各位可以自行尝试。
正常训练过程中,日志里只会显示每一组迭代后模型训练的整体信息,如果想要了解更多详细的信息,就要将solver.prototxt中的调试信息打开,这样就可以获得更多有用的信息供大家分析:
debug_info:true
调试信息打开后,每一组迭代后每一层网络的前向后向计算过程中的详细信息都可以被观测到。这里截取其中一组迭代后的日志信息展示出来:
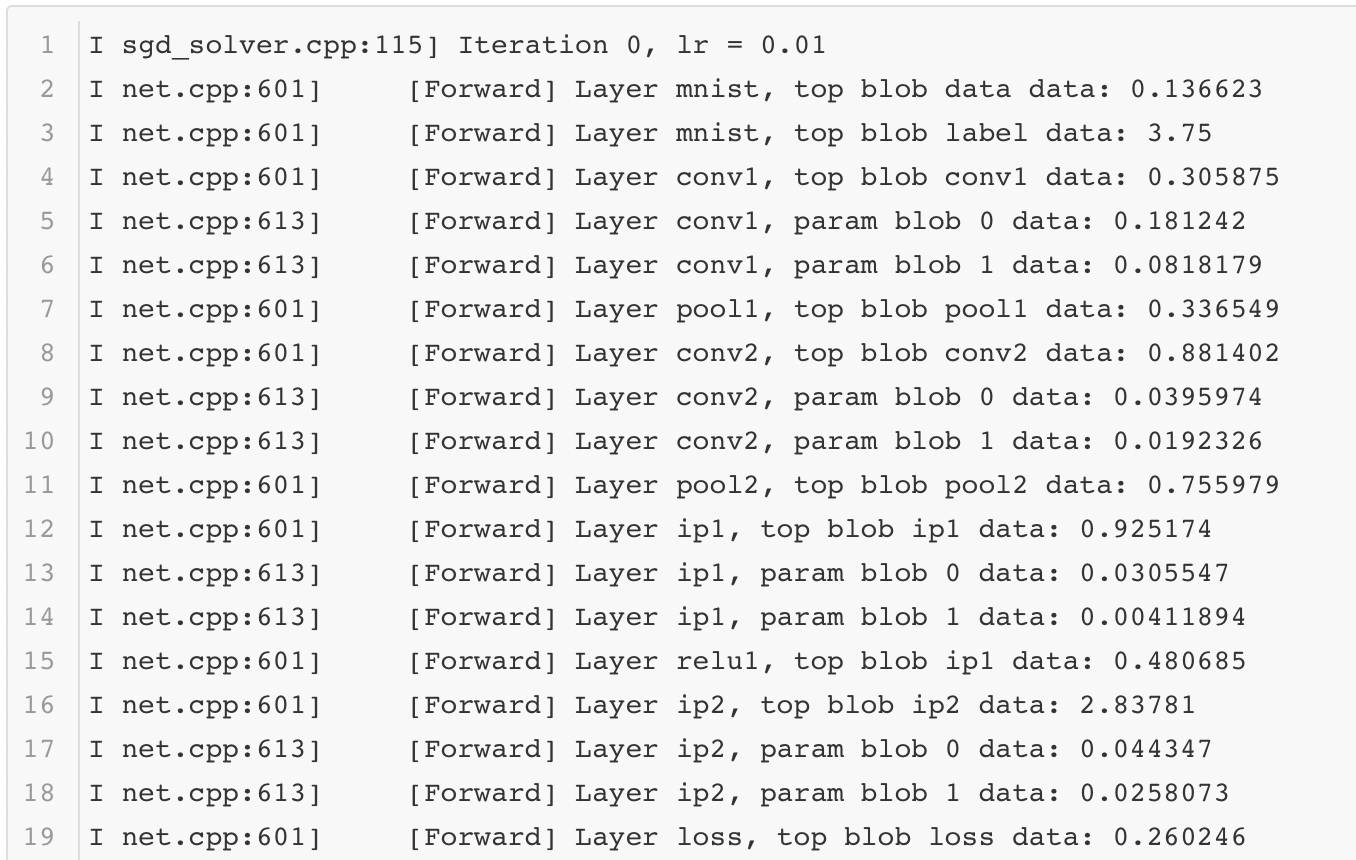

如果想要对网络的表现做更多地了解,那么分析这些内容必不可少。
5 预测检验与分析
模型完成训练后,就要对它的训练表现做验证,看看它在其他测试数据集上的正确性。Caffe提供了另外一个功能用于输出测试的结果。以下就是它的脚本:

脚本的输出结果如下所示:

除了完成测试的验证,有时大家还需要知道模型更多的运算细节,这就需要深入模型内部去观察模型产生的中间结果。使用Caffe提供的借口,每一层网络输出的中间结果都可以用可视化的方法显示出来,供大家观测、分析模型每一层的作用。其中的代码如下所示:
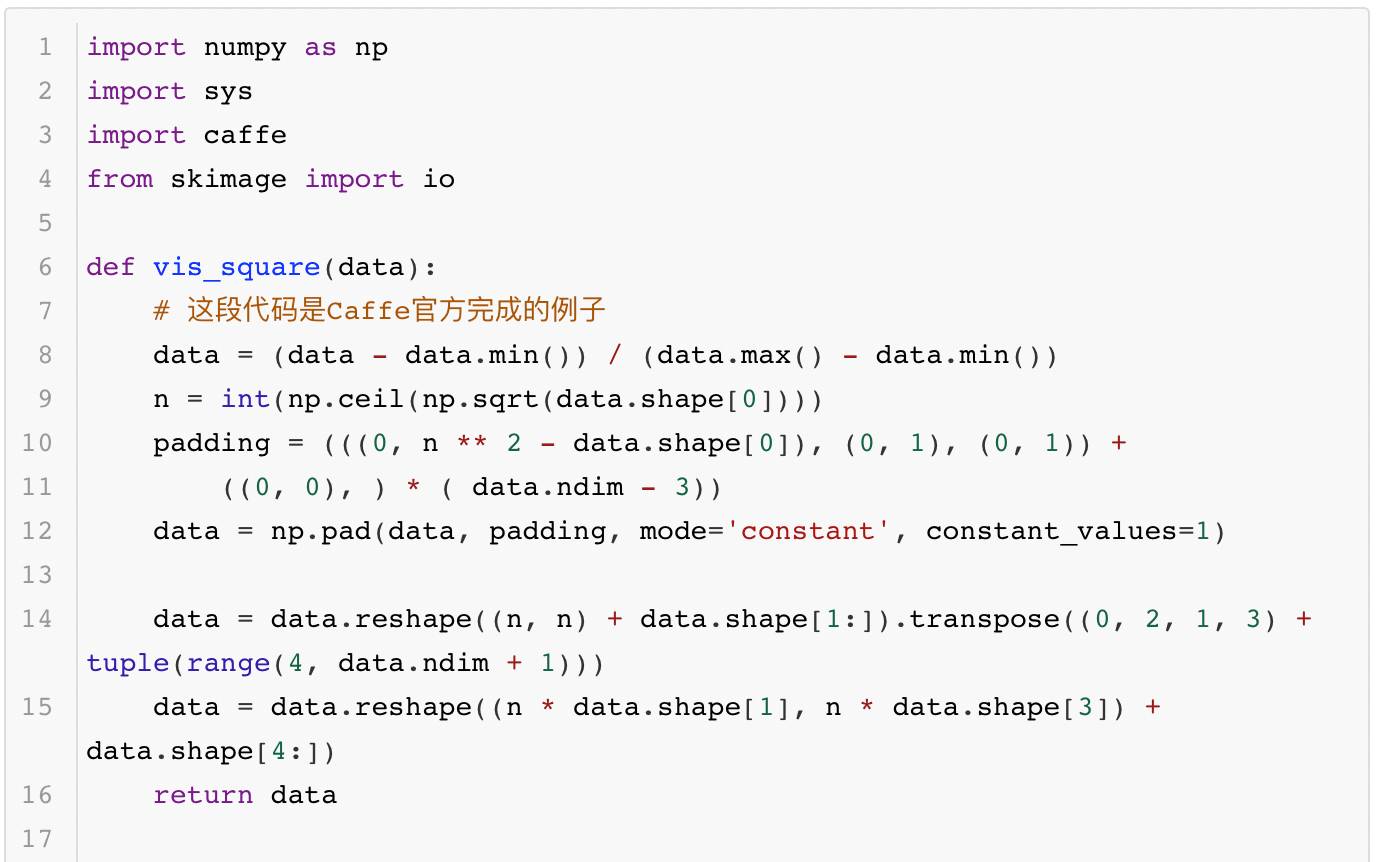

执行上面的代码就可以生成如图2到图5这几张图像,它们各代表一个模型层的输出图像:




这一组图展示了卷积神经网络是如何把一个数字转变成特征编码的。这样的方法虽然可以很好地看到模型内部的表现,比方说conv1的结果图中有的提取了数字的边界,有的明确了前景像素所在的位置,这个现象和第3章中举例的卷积效果有几分相似。但是到了conv2的结果图中,模型的输出就变得让人有些看不懂了。实际上想要真正看懂这些图像想表达的内容确实有些困难的。
6 性能测试
除了在测试数据上的准确率,模型的运行时间也非常值得关心。如果模型的运行时间太长,甚至到了不可用的程度,那么即使它精度很高也没有实际意义。测试时间的脚本如下所示:

Caffe会正常的完成前向后向的计算,并记录其中的时间。以下是使一次测试结果的时间记录:
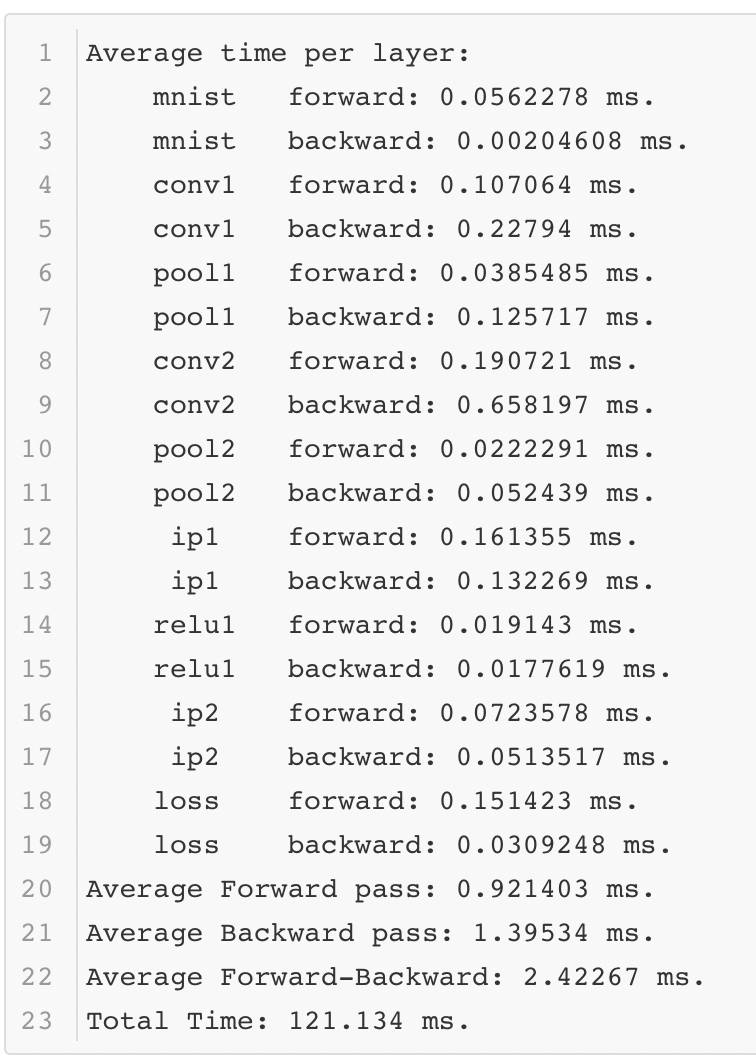
可以看出在性能测试的过程中,Lenet模型只需要不到1毫秒的时间就可以完成前向计算,这个速度还是很快的。当然这是在一个相对不错的GPU上运行的,那么如果在一个条件差的GPU上运行,结果如何呢?
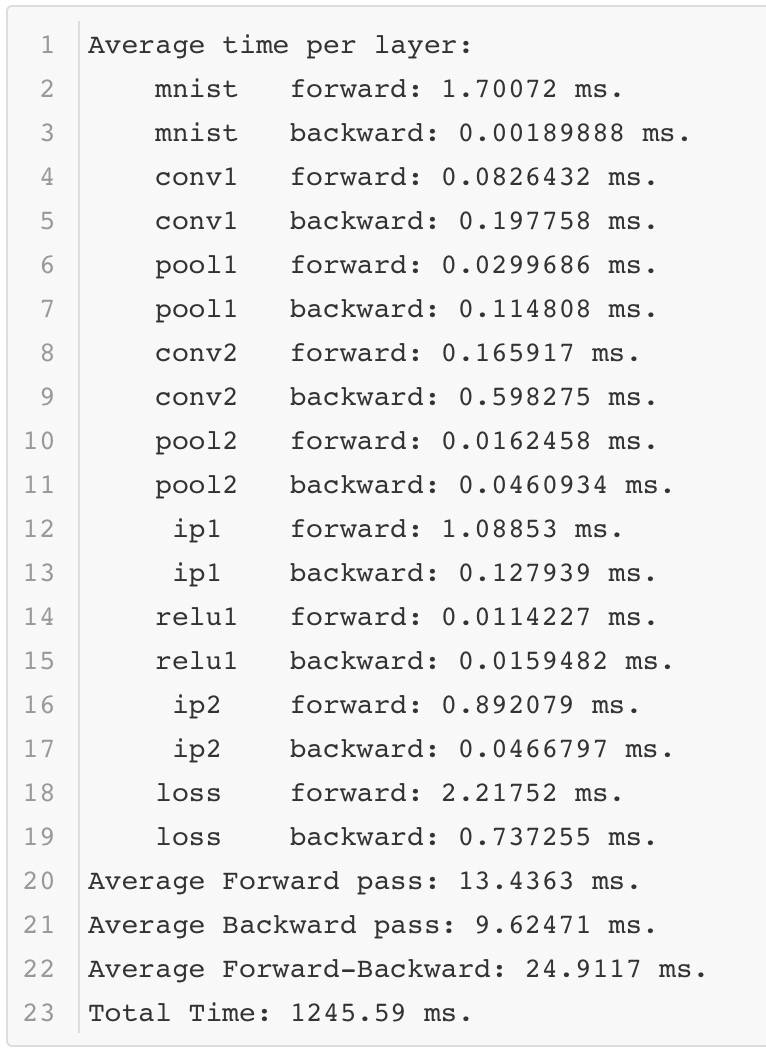
可以看到不同的环境对于模型运行的时间影响很大。
以上就是模型训练的一个完整过程。现在相信大家对深度学习模型的训练和使用有了基本的了解。实际上看到这里大家甚至可以扔下书去亲自实践不同模型的效果,开始深度学习的实战之旅。
最后放一张Caffe源代码的架构图,以方便大家研究Caffe源码。

答疑环节
Q1. Caffe和其他深度学习框度(如MxNet, Tensorflow等)比有什么优缺点?
冯超:Caffe作为“老一代”的深度学习框架,从架构上来说有一个很大的不同之处,那就是它不是采用符号运算的方式进行设计的,这样带来了一些优点和缺点。
优点是Caffe在计算过程中,在内存使用和运算速度方面都有一定的优势,内存使用较小,速度也比较有保证,相对而言,基于符号计算的框架在这两方面会稍弱一些。
缺点是Caffe模型灵活性较弱。对于一些新出现的网络模型结构,Caffe适配起来需要一些技巧,需要一定的经验,而MXNet,TensorFlow这样的模型就简单很多。
所以一般来说,MXNet、Tensorflow更适合实验环境,Caffe比较适合工业界线上使用。其他方面,现在Caffe的社区相比Tensorflow可能要弱些,但依然是非常主流的开源框架。
Q2. 如何看待facebook新发布的caffe2深度学习框架?它比现有的caffe有什么样的改进?跟现在的TensorFlow相比如何?
冯超:caffe2最近比较热,之前我没有多看过,这两天集中看了看,大概有以下一些感受:
有了Caffe2和Caffe相比变化大么?prototxt和caffemodel海斗可以用,基本上算向下兼容,Caffe的一些知识技能还可以用。
Caffe2的操作方式?从官方文档中看,Caffe2的python接口有了很大的进步。给出的示例主要是用python代码描述网络结构(和tf很像,也有checkpoint等概念)->生成内存版的网络模型->构建net和相关环境->执行代码,所以除了前面的python接口,后面的流程和caffe1很像。
内部架构上的变化?Caffe2借鉴了Tensorflow的一些概念,将过去的Net拆成两部分:数据和网络图。数据部分是Workspace,和tf的session很像,另外一部分是网络图net。另外,Caffe2内部也将Layer改成了Op。
现在就上手Caffe2?几乎有点早,目前官方给出的内容还比较少,大家也不必太心急。
最后说说Caffe2官方给出的一些亮点功能:跨平台。这一次的Caffe2可以在各种不同的平台上部署运行,这算是一个亮点。
Q3. caffee和pytorch都是facebook在推,那这两个框架有什么不同呢?
冯超:基本上实验环境下主要用pytorch,线上环境用Caffe。
Q4. caffe有没有提供一些preTraining的一些模型 方便更快地调用网络呢?
冯超:Caffe有自己的Model zoo: https://github.com/BVLC/caffe/wiki/Model-Zoo,详情可以上去看一看。
Q5. caffe在移动端实践的实际案例吗?
冯超:就我身边有限的了解,一些公司做移动端尝试还是使用了Tensorflow,并没有用Caffe。
作者介绍
冯超,毕业于中国科学院大学,现就职于猿辅导公司,从事视觉与深度学习的应用研究工作。自2016年起在知乎开设了自己的专栏——《无痛的机器学习》(https://zhuanlan.zhihu.com/hsmyy),发表一些机器学习和深度学习的文章,收到了不错的反响。
利用caffe的solverstate断点训练的更多相关文章
- train loss与test loss结果分析(接利用caffe的solverstate断点训练)
train loss 不断下降,test loss不断下降,说明网络仍在学习; train loss 不断下降,test loss趋于不变,说明网络过拟合; train loss 趋于不变,test ...
- 利用caffe生成 lmdb 格式的文件,并对网络进行FineTuning
利用caffe生成 lmdb 格式的文件,并对网络进行FineTuning 数据的组织格式为: 首先,所需要的脚本指令路径为: /home/wangxiao/Downloads/caffe-maste ...
- Caffe系列4——基于Caffe的MNIST数据集训练与测试(手把手教你使用Lenet识别手写字体)
基于Caffe的MNIST数据集训练与测试 原创:转载请注明https://www.cnblogs.com/xiaoboge/p/10688926.html 摘要 在前面的博文中,我详细介绍了Caf ...
- 利用Caffe训练模型(solver、deploy、train_val)+python使用已训练模型
本文部分内容来源于CDA深度学习实战课堂,由唐宇迪老师授课 如果你企图用CPU来训练模型,那么你就疯了- 训练模型中,最耗时的因素是图像大小size,一般227*227用CPU来训练的话,训练1万次可 ...
- 利用Caffe训练模型(solver、deploy、train_val) + python如何使用已训练模型
版权声明:博主原创文章,微信公众号:素质云笔记,转载请注明来源“素质云博客”,谢谢合作!! https://blog.csdn.net/sinat_26917383/article/details/5 ...
- Caffe上用SSD训练和测试自己的数据
学习caffe第一天,用SSD上上手. 我的根目录$caffe_root为/home/gpu/ljy/caffe 一.运行SSD示例代码 1.到https://github.com ...
- caffe在solverstate的基础上继续训练模型
以mnist数据集为例: bat训练脚本: Build\x64\Release\caffe.exe train --solver=examples/mnist/lenet_solver.prototx ...
- 利用Caffe做回归(regression)
Caffe应该是目前深度学习领域应用最广泛的几大框架之一了,尤其是视觉领域.绝大多数用Caffe的人,应该用的都是基于分类的网络,但有的时候也许会有基于回归的视觉应用的需要,查了一下Caffe官网,还 ...
- Caffe初试(三)使用caffe的cifar10网络模型训练自己的图片数据
由于我涉及一个车牌识别系统的项目,计划使用深度学习库caffe对车牌字符进行识别.刚开始接触caffe,打算先将示例中的每个网络模型都拿出来用用,当然这样暴力的使用是不会有好结果的- -||| ,所以 ...
随机推荐
- TPO-11 C2 Work for the biology committee
committee 委员会 representative 代表 department secretary 系里的秘书 applicant 申请人 TPO-11 C2 Work for the biol ...
- 拓扑排序 (Ordering Tasks UVA - 10305)
题目描述: 原题:https://vjudge.net/problem/UVA-10305 题目思路: 1.依旧是DFS 2.用邻接矩阵实现图 3.需要判断是否有环 AC代码 #include < ...
- KVM嵌套虚拟化
1. 检查环境 $ grep -E 'svm|vmx' /proc/cpuinfo ~]# lsmod | grep kvm kvm_intel 170181 0 kvm ...
- C指针函数中的局部变量返回
所谓指针函数其实就是 :一个函数的返回值为指针. 指针函数定义:返回类型标识符* 函数名(形参列表){函数体} eg: int* fun1(int n){} 指针函数和局部变量返回解析: 简 ...
- 【Linux】Face Recognition的封装
使用虹软的人脸识别 写了一个linux下的Face Recognition的封装,当作是练习. C++的封装,结合opencv,使用方便.https://github.com/zacario-li/F ...
- leetcode个人题解——#24 Swap Nodes in Pairs
因为不太熟悉链表操作,所以解决方法烦了点,空间时间多有冗余. 代码中l,r分别是每一组的需要交换的左右指针,temp是下一组的头指针,用于交换后链接:res是交换后的l指针,用于本组交换后尾指针在下一 ...
- appcan打包后产生的问题总结
以appcan为基础的项目,最终需要打包后进行调试.在调试过程中,主要的样式问题在苹果手机上,下面将这些问题总结起来,以防下次再犯. 1:ios 7 以上的手机中,状态栏与内容重叠: 问题描述:在io ...
- 《剑指Offer》题四十一~题五十
四十一.数据流中的中位数 题目:如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值.如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中 ...
- 自测之Lesson4:gdb
题目:列出gdb过程中常用的命令. 常用命令: 命令 作用 使用示例1 使用示例2 list 列出代码 list 行号 list 函数名 break 设置断点 break 行号 b 行号 run 运行 ...
- 直接管理内存——new和delete
一.运算符new 1. 使用new动态分配对象 在自由空间分配的内存是无名的,故new无法为其分配的对象命名,而是返回一个指向该对象的指针 int *pi = new int; //pi指向一个动态分 ...