scrapy框架解读--深入理解爬虫原理

scrapy框架结构图:
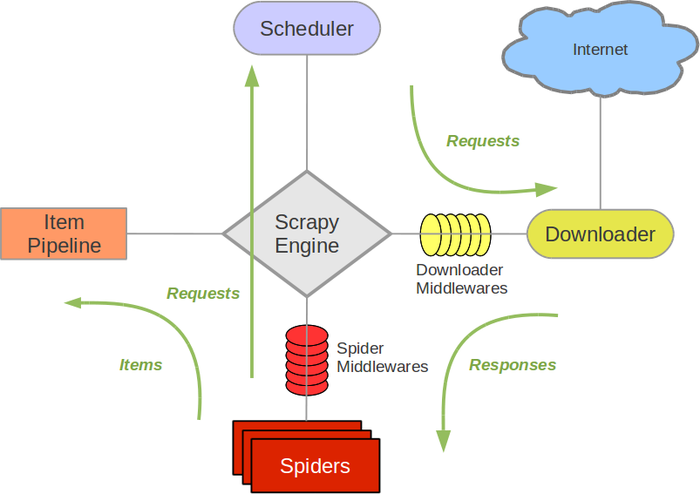
组成部分介绍:
Scrapy Engine:
负责组件之间数据的流转,当某个动作发生时触发事件Scheduler:
接收requests,并把他们入队,以便后续的调度Downloader:
负责抓取网页,并传送给引擎,之后抓取结果将传给spiderSpiders:
用户编写的可定制化的部分,负责解析response,产生items和URLItem Pipeline:
负责处理item,典型的用途:清洗、验证、持久化Downloader middlewares:
位于引擎和下载器之间的一个钩子,处理传送到下载器的requests和传送到引擎的response(若需要在Requests到达Downloader之前或者是responses到达spiders之前做一些预处理,可以使用该中间件来完成)Spider middlewares:
位于引擎和抓取器之间的一个钩子,处理抓取器的输入和输出
(在spiders产生的Items到达Item Pipeline之前做一些预处理或response到达spider之前做一些处理)
Scrapy中的数据流:
- Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的spider,并向该spider请求第一个要爬取的url(s);
- 引擎从spider中获取到第一个要爬取的url并在调度器(scheduler)以requests调度;
- 引擎向调度器请求下一个要爬取的url;
- 调度器返回下一个要爬取的url给引擎,引擎将url通过下载器中间件(请求requests方向)转发给下载器(Downloader);
- 一旦页面下载完毕,下载器生成一个该页面的responses,并将其通过下载器中间件(返回responses方向)发送给引擎;
- 引擎从下载器中接收到responses并通过spider中间件(输入方向)发送给spider处理;
- spider处理responses并返回爬取到的Item及(跟进的)新的resquests给引擎
- 引擎将(spider返回的)爬取到的Item给Item Pipeline,将(spider返回的)requests给调度器;
- (从第二部)重复直到(调度器中没有更多的request)引擎关闭该网站
中间件的编写:
down loader middle ware – 查看文档151页
spider middle wares – 查看文档162页
scrapy框架解读--深入理解爬虫原理的更多相关文章
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
- 使用scrapy框架做赶集网爬虫
使用scrapy框架做赶集网爬虫 一.安装 首先scrapy的安装之前需要安装这个模块:wheel.lxml.Twisted.pywin32,最后在安装scrapy pip install wheel ...
- Scrapy框架实战-妹子图爬虫
Scrapy这个成熟的爬虫框架,用起来之后发现并没有想象中的那么难.即便是在一些小型的项目上,用scrapy甚至比用requests.urllib.urllib2更方便,简单,效率也更高.废话不多说, ...
- Scrapy框架解读
1. Scrapy组件a. 主体部分i. 引擎(Scrapy):处理整个系统的数据流处理,触发事务(框架核心)ii. 调度器(Scheduler):1) 用来接受引擎发过来的请求, 压入队列中, 并在 ...
- 基于Scrapy框架的增量式爬虫
概述 概念:监测 核心技术:去重 基于 redis 的一个去重 适合使用增量式的网站: 基于深度爬取的 对爬取过的页面url进行一个记录(记录表) 基于非深度爬取的 记录表:爬取过的数据对应的数据指纹 ...
- 网络爬虫第五章之Scrapy框架
第一节:Scrapy框架架构 Scrapy框架介绍 写一个爬虫,需要做很多的事情.比如:发送网络请求.数据解析.数据存储.反反爬虫机制(更换ip代理.设置请求头等).异步请求等.这些工作如果每次都要自 ...
- Scrapy框架学习笔记
1.Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网 ...
- python高级之scrapy框架
目录: 爬虫性能原理 scrapy框架解析 一.爬虫性能原理 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下请求URL时必然会引起等待,从而使得请求整体变慢. 1.同步执行 impor ...
- 都是干货---真正的了解scrapy框架
去重规则 在爬虫应用中,我们可以在request对象中设置参数dont_filter = True 来阻止去重.而scrapy框架中是默认去重的,那内部是如何去重的. from scrapy.dupe ...
随机推荐
- 关于websocket
一句话总结: websocket可以说是基于HTTP但有有所进化的一个介于应用层和传输层的接口抽象,不是协议. 1 需要基于HTTP进行3次握手,4次挥手(在握手期间建立websocket连接,不再通 ...
- Java 运行环境介绍
Java 语言特点: 跨平台性: 一次编译,到处运行.即不受操作系统限制,编译一次,可以在多个平台运行.而这个优势得益于 JVM(Java Virtual Machine, 即Java 虚拟机). 两 ...
- 用Kotlin开发Android的Hello Kotlin!!
1 创建新项目 android studio 新建一个项目 只有一个空MainActivity 2 安装kotlin file-seeting-plugins-install jetbrains pl ...
- beego——获取参数
1.获取参数 我们经常需要获取用户传递的数据,包括Get.POST等方式的请求,beego里面会自动解析这些数据,你可以通过如下方式获取数据: GetString(key string) string ...
- pycharm修改配置
恢复pycharm的初始设置
- 如何优雅地使用 Stack Overflow
链接:https://www.zhihu.com/question/20824615/answer/69560657 来源:转载 一,提问前一定要搜索,先在 Google 搜索,然后在 StackOv ...
- POJ - 2226 Muddy Fields (最小顶点覆盖)
*.*. .*** ***. ..*. 题意:有一个N*M的像素图,现在问最少能用几块1*k的木条覆盖所有的 * 点,k为>=1的任意值. 分析:和小行星那题很像.小行星那题是将一整行(列)看作 ...
- Entity FrameWork Code First 之Model分离
之前一直用DB First新建类库进行使用,最近开始研究Code First.Code First也可以将Model新建在类库里面,然后通过数据迁移等操作生成数据库. 现在说下主要步骤: 1.新建类库 ...
- Entity FrameWork Code First常用知识
1.Model属性类: [Key] //标识一个属性作为主键,即使它不符合类名+Id的格式. [MaxLength(500)] //限制一个字符串属性最多有多少字,其对应的数据表字段也会是nvarch ...
- function func(){} 与 var func=function(){}的区别
1 var func =function(){} ,即和 var 变量的特性 一样. func 变量名提前,但是不会初始化,直到执行到初始化代码. 2 function func(){} ...