hadoop学习之hdfs文件系统
一、hdfs的概念
Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。
什么是文件系统呢,其实我们最熟悉的windows用的是NTFS文件系统,linux用的是EXT3等等的,那归根结底不管什么存储方式,不同的文件系统里面存储文件是什么形式,它都是用来存储文件的,那么HDFS也是一样的,那我们就可以把它理解为类似于Win的HDFS的一种存储文件的方式。
二、hdfs实现思想和概念
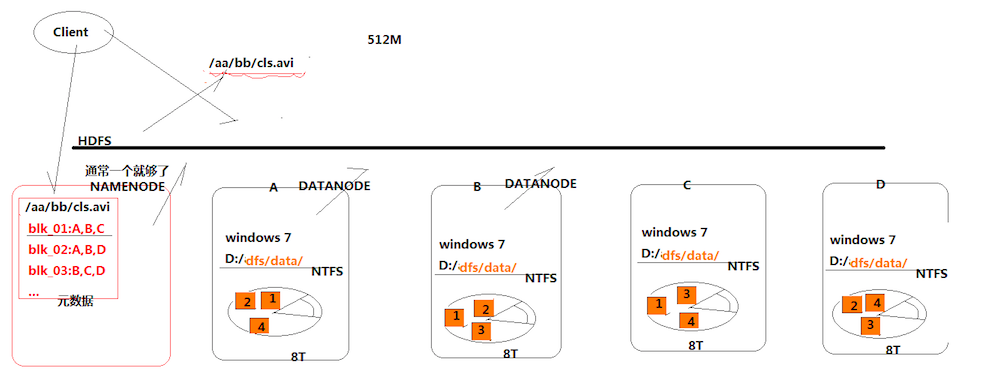
首先有一个概念叫分布式存储,它与普通的存储方式最大的区别在于,它将文件数据切分存放在多台服务器上面,从而减轻了一台服务器的存储压力。那么hdfs也是一种分布式存储的系统,具体怎么存储的如上图所示。
首先,我们又ABCD四个存储的服务器,有一个待存储的文件叫cls.avi,那么既然是分布式存储的,那么我们可以先将带存储文件切分为4块,在图中以1234个小方块表示,那么,我们可以将1234分别先存储到ABCD四个服务器里面,然后ABCD分别用NTFS将其保存起来。
那么这样初步实现了将数据分块存储,然后需要取数据的时候,从四台服务器将数据取出来然后拼接起来,这样就初步实现了数据分布化。但是这样存储面临一种问题,也就是说,如果我其中的一台服务器,比如说A坏掉了,那么最终我取出来的文件便会不全,那么为了解决这种问题,hdfs将文件的块存储在多台服务器里面,如上图中,块1存储在ABC,块2存储在ABD等等,那么如果说,我想取出块1,那么即便A坏了,我也可以从BC里面取,那么最终我取出来的数据还是完整的。
接着,还有一个问题,我是如何知道哪些块存储在哪些服务器上面的呢?那么hdfs提供了一个类似于路由服务器的功能,也就是所谓的namenode,前面所说的存储的服务器叫做datanode。那么namenode主要的功能便是,在数据块被存储的时候,将数据存储信息记录下来,比如说块1:ABC,块2:ABD等等,那么到客户端需要取出数据的时候,可以根据这些存储信息去对应的服务器上面获取数据即可,而且我们不太需要关心namenode的并发压力问题,因为这些存储信息的大小都会很小,不像datanode那样需要存储数据块。
三、总结
1.hdfs是通过分布式集群来存储文件的,文件被存储的时候分块多个block块
2.某一个block块存储在多台数据服务器datanode里面的
3.block块于datanode的存储关系是映射的,信息存储在namenode里面
4.这样存储的好处是其中一台机器发生故障,不会影响到数据的存储与读取
hdfs主要是负责存储,那么如何快速的将这些存储的大量数据读取并且返回给客户端,那么便是MapReduce需要去做的了。博主也是刚刚接触hadoop不久,上面的只是博主个人所学的见解,如果有不对的地方,还请大家多多指教。
hadoop学习之hdfs文件系统的更多相关文章
- hadoop学习(五)----HDFS的java操作
前面我们基本学习了HDFS的原理,hadoop环境的搭建,下面开始正式的实践,语言以java为主.这一节来看一下HDFS的java操作. 1 环境准备 上一篇说了windows下搭建hadoop环境, ...
- Hadoop学习笔记—HDFS
目录 搭建安装 三个核心组件 安装 配置环境变量 配置各上述三组件守护进程的相关属性 启停 监控和性能 Hadoop Rack Awareness yarn的NodeManagers监控 命令 hdf ...
- Hadoop学习笔记-HDFS命令
进入 $HADOOP/bin 一.文件操作 文件操作 类似于正常的linux操作前面加上“hdfs dfs -” 前缀也可以写成hadoop而不用hdfs,但终端中显示 Use of this scr ...
- hadoop学习(二)----HDFS简介及原理
前面简单介绍了hadoop生态圈,大致了解hadoop是什么.能做什么.带着这些目的我们深入的去学习他.今天一起看一下hadoop的基石--文件存储.因为hadoop是运行与集群之上,处于分布式环境之 ...
- 【Hadoop学习】HDFS 短路本地读
Hadoop版本:2.6.0 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4146296.html 背景 ...
- Hadoop学习笔记---HDFS
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.HDFS能提供高吞吐 ...
- Hadoop 学习之——HDFS
HDFS是HADOOP中的核心技术之一——分布式文件存储系统.Hadoop的作者Doug Cutting 和Mike 是根据Google发布关于GFS 的研究报告所设计出的分布式文件存储系统. 一.H ...
- hadoop学习记录--hdfs文件上传过程源码解析
本节并不大算为大家讲接什么是hadoop,或者hadoop的基础知识因为这些知识在网上有很多详细的介绍,在这里想说的是关于hdfs的相关内容.或许大家都知道hdfs是hadoop底层存储模块,专门用于 ...
- hadoop学习之HDFS
1.什么是大数据?什么是云计算?什么是hadoop? 大数据现在很火,到底什么是大数据,多大的数据才算大,一般而言对于TB级以上的数据我们成为大数据,对于这些数据它的价值在哪?大数据的价值就是我们大量 ...
随机推荐
- canvas制作完美适配分享海报
基于mpvue实现的1080*1900小程序海报 html <canvas class="canvas" :style="'width:'+windowWidt ...
- " XSS易容术---bypass之编码混淆篇+辅助脚本编写"
一.前言本文原创作者:vk,本文属i春秋原创奖励计划,未经许可禁止转载!很多人对于XSS的了解不深.一提起来就是:“哦,弹窗的”.”哦,偷cookie的.”骚年,你根本不知道什么是力量.虽然我也不知道 ...
- storm安装以及简单操作
storm的安装比较简单,下面以storm的单节点为例说明storm的安装步骤. 1.storm的下载 进入storm的官方网站http://storm.apache.org/,点击download按 ...
- Swift5 语言参考(五) 语句
在Swift中,有三种语句:简单语句,编译器控制语句和控制流语句.简单语句是最常见的,由表达式或声明组成.编译器控制语句允许程序更改编译器行为的各个方面,并包括条件编译块和行控制语句. 控制流语句用于 ...
- Redis---事务和Wtach
1. 概述 Redis通过 MULTI, EXEC / WATCH 等命令来实现事务. 事务提供一种将多个命令请求打包, 然后一次性.按顺序的执行多个命令的机制. 并且在事务执行期间, 服务器不会中断 ...
- [Umbraco] document type里的父节点与子节点的设置
虽然我们不能像做数据库设计那样建立主外键关系.但我们建立xml里父子关系,父子关系其实是指是否允许在一个页面(如频道,分类,栏目等)下创建子页面,这就相当于建立站点的树状结构,对于筛选数据会有很大的作 ...
- C# 多线程八之并行Linq(ParallelEnumerable)
1.简介 关于并行Linq,Ms官方叫做并行语言集成(PLINQ)查询,其实本质就是Linq的多线程版本,常规的Linq是单线程的,也就是同步的过程处理完所有的查询.如果你的Linq查询足够简单,而且 ...
- Attr类中进行类型推断
涉及到重要的类的继承关系如下图所示. 关于抛出的异常继承体系:
- 垃圾回收(GC)相关算法笔记
GC需要完成的3件事情: 哪些内存需要回收? 什么时候回收? 如何回收? 引用计数算法 给对象中添维护一个计数器,每当引用这个对象时,计数器加1:当引用失效时,计数器值减1:当计数器值为0时,表示这个 ...
- MySQL的视图view,视图创建后,会随着表的改变而自动改变数据
首先是创建视图 CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `new_view` A ...