数据结构(三)串---KMP模式匹配算法实现及优化
KMP算法实现
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h> #define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0 #define MAXSIZE 40 typedef int ElemType;
typedef int Status; //设置串的存储结构
typedef char String[MAXSIZE+]; //生成串相关
Status StrAssign(String S,char *chars); //生成一个其值等于字符串常量的chars的串T
Status StrCopy(String T, String S); //串S存在,由串S复制得到串T
Status Concat(String T, String S1, String S2); //用T返回由S1和S2连接而成的新串 //基础操作相关
Status ClearString(String S); //串S存在,将串清空
Status StringEmpty(String S); //若串为空,返回true,否则false
int StringLength(String S); //返回串S的元素个数,长度 //比较串,索引串相关
int StrCompare(String S, String T); //若S > T返回 > 0, = 返回0, < 返回 < 0
Status SubString(String Sub, String S,int pos,int len); //串S存在,返回S由pos起,长度为len的子串到Sub
int Index(String S, String T,int pos); //主串S,子串T,返回T在S中位置 //增删改相关
Status Replace(String S, String T, String V); //串S,T和V存在,T非空,用V替换主串S中T串
Status StrInsert(String S, int pos, String T); //在主串S中的pos位置插入串T
Status StrDelete(String S,int pos,int len); //串S存在,从串S中删除第pos个字符串起长度为len的子串 void PrintStr(String S); //生成串相关
//生成一个其值等于字符串常量的chars的串T
Status StrAssign(String S, char *chars)
{
int i;
if (strlen(chars) > MAXSIZE)
return ERROR;
else
{
S[] = strlen(chars);
for (i = ; i <= S[];i++)
S[i] = *(chars+i-);
return OK;
}
} //串S存在,由串S复制得到串T
Status StrCopy(String T, String S)
{
int i;
for (i = ; i <= S[];i++)
T[i] = S[i];
return OK;
} //用T返回由S1和S2连接而成的新串,若是超出,会截断,但是会进行连接,返回FALSE
Status Concat(String T, String S1, String S2)
{
int i,j,interLen; //interLen是截断后S2剩余长度 if (S1[] + S2[] > MAXSIZE)
interLen = MAXSIZE - S1[];
else
interLen = S2[]; T[] = S1[] + S2[];
for (i = ; i <= S1[]; i++)
T[i] = S1[i];
for (j = ; j <= interLen; j++)
T[i+j-] = S2[j];
if (interLen != S2[])
return ERROR;
return OK;
} //基础操作相关
//串S存在,将串清空
Status ClearString(String S)
{
S[] = ;
return OK;
} //若串为空,返回true,否则false
Status StringEmpty(String S)
{
if (S[] != )
return FALSE;
return TRUE;
} //返回串S的元素个数,长度
int StringLength(String S)
{
return S[];
} //比较串,索引串相关
//若S > T返回 > 0, = 返回0, < 返回 < 0
int StrCompare(String S, String T)
{
int i;
for (i = ; i <= S[] && i <= T[]; i++)
if (S[i] != T[i])
return S[i] - T[i];
return S[]-T[]; //若是相同比较长度即可
} //串S存在,返回S由pos起,长度为len的子串到Sub
Status SubString(String Sub, String S, int pos,int len)
{
int i;
if (pos< || len< || pos + len - > S[] || pos>S[])
return ERROR;
for (i = ; i < len;i++)
Sub[i + ] = S[pos + i];
Sub[] = len;
return OK;
} //主串S,子串T,返回T在S中位置,pos代表从pos开始匹配
//或者一次截取一段进行比较为0则找到
int Index(String S, String T, int pos)
{
int i, j;
i = pos;
j = ;
while (i<=S[]-T[]+&&j<=T[])
{
if (S[i]==T[j])
{
j++;
i++;
}
else
{
i = i - j + ; //注意这个索引的加2
j = ;
}
}
if (j > T[])
return i - T[];
return ;
} //增删改相关
//串S,T和V存在,T非空,用V替换主串S中T串
Status Replace(String S, String T, String V)
{
int idx=;
if (StringEmpty(T))
return ERROR; while (idx)
{
idx = Index(S, T, idx);
if (idx)
{
StrDelete(S, idx, StringLength(T));
StrInsert(S, idx, V);
idx += StringLength(V);
}
}
return OK;
} //在主串S中的pos位置插入串T,注意:若是串满,则只插入部分
Status StrInsert(String S, int pos, String T)
{
int i,interLength;
if (S[] + T[] > MAXSIZE) //长度溢出
interLength = MAXSIZE - S[];
else
interLength = T[]; for (i = S[]; i >= pos;i--)
S[interLength + i] = S[i]; //将后面的数据后向后移动 //开始插入数据
for (i = ; i <= interLength; i++)
S[pos + i - ] = T[i]; S[] += interLength; if (interLength != T[])
return ERROR;
return OK;
} //串S存在,从串S中删除第pos个字符串起长度为len的子串
Status StrDelete(String S, int pos,int len)
{
int i;
if (pos < || len< || pos + len - >S[])
return ERROR; //将数据前移
for (i = pos+len; i <= S[];i++)
S[i-len] = S[i]; S[] -= len;
return OK;
} void PrintStr(String S)
{
int i;
for (i = ; i <= StringLength(S);i++)
{
printf("%c", S[i]);
}
printf("\n");
}
串的顺序存储结构
//通过计算返回子串T的next数组
void get_next(String T, int* next)
{
int m, j;
j = ; //j是后缀的末尾下标
m = ; //m代表的是前缀结束时的下标
next[] = ;
while (j < T[])
{
if (m == || T[m] == T[j]) //T[m]表示前缀的最末尾字符,T[j]是后缀的最末尾字符
{
++m;
++j;
next[j] = m;
}
else
m = next[m]; //若是字符不相同,则m回溯
}
}
int Index_KMP(String S, String T, int pos)
{
int i = pos;
int j = ;
int next[MAXSIZE];
get_next(T, next);
while (i<=S[]&&j<=T[]) //其实现与BF算法相似,不过不同的是i不进行回溯,而是将j进行了修改
{
if (j==||S[i]==T[j])
{
++i;
++j; //若完全匹配后,j就会比模式串T的长度大一
}
else //不匹配时,就使用next数组获取下一次匹配位置
{
j = next[j];
}
}
if (j > T[])
return i - T[];
else
return ;
}
int main()
{
int i, j;
String s1,s2,t; char *str = (char*)malloc(sizeof(char) * );
memset(str, , );
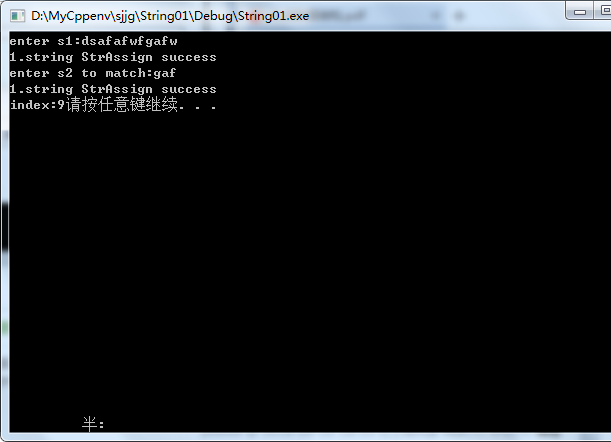
printf("enter s1:");
scanf("%s", str);
if (!StrAssign(s1, str))
printf("1.string length is gt %d\n", MAXSIZE);
else
printf("1.string StrAssign success\n"); printf("enter s2 to match:");
scanf("%s", str);
if (!StrAssign(s2, str))
printf("1.string length is gt %d\n", MAXSIZE);
else
printf("1.string StrAssign success\n"); i = Index_KMP(s1, s2, );
printf("index:%d", i); system("pause");
return ;
}
main函数
KMP算法优化---对next数组获取进行优化
原来我们获取的next数组是由缺陷的
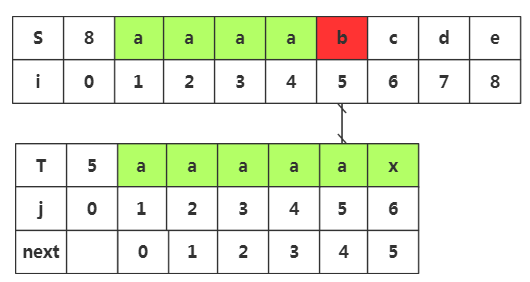
我们可以发现j5与i5失配,所以按照上面的next值,会去匹配j4-j3-j2-j1,但是我们从前面的思路启发知道,当我们知道j1=j2=j3=j4=j5,而j5≠i5,那么我们完全可以知道j1到j4也是不与i5匹配,
所以,我们这里做了太多的重复匹配。这就是我们需要优化的地方
由于T串的第二三四五位的字符都与首位的'a'相等,那么可以用首位next[]的值去取代与他相等的字符后续的next[j]值
改进方法:
我们将新获取的next值命名为nextval,则新的nextval与他同列的next值有关,我们找的一next[j]为列值的新的j列,将字符进行比较,若是相同,则将该列的next值变为现在的nextval
例如:
推导1:
第一步:当j=1时,nextval=
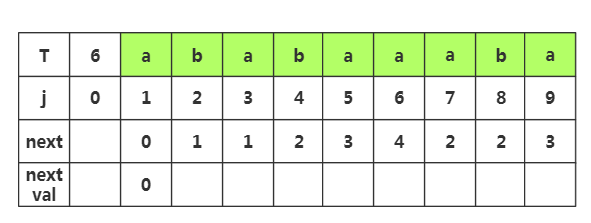
第二步:获取j=2时,nextval[]的值,首先我们需要获取next[]值为1,然后我们将这个值作为新得前缀获取j=1时的T串数据'a',发现他与当前j=2处的字符'b'不同,那么nextval[]不变,与原来的next[]值一样,为1
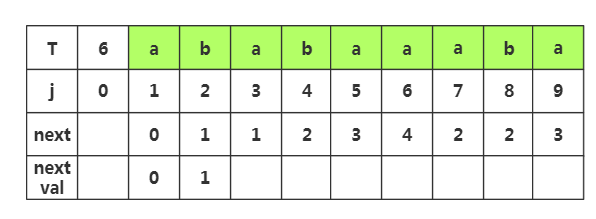
第三步:获取j=3时,nextval[]的值,我们先获取next[]的值为1,然后将这个值作为新的索引获取j=该值处的字符T[]='a',发现T[]=T[],所以当前的nextval值为j=1处的nextval值,即nextval[]=nextval[]=

第四步:获取j=4时,nextval[]的值,相应的next[]为2,获取T[]字符‘b’,与当前所以T[]='b'相同,那么当前nextval[]=nextval[]=
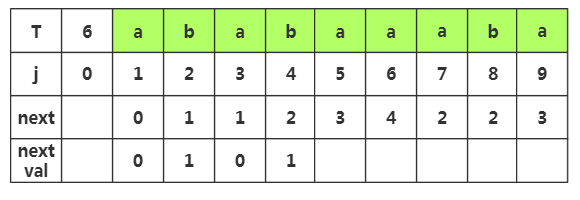
第五步:获取j=5时,nextval[]的值,相应next[]=,查看T[]字符为'a',而当前T[]='a',相同,那么nextval[]=nextval[]=
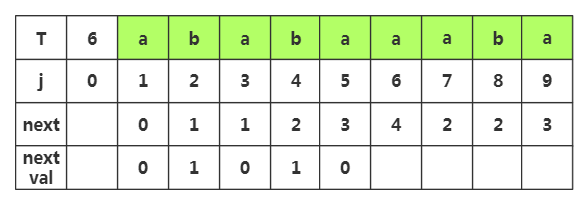
第六步:获取j=6时,nextval[]的值,相应next[]=,查看T[]字符为'b',而当前T[]='a',不相同,那么nextval[]就等于原来的next[]值为4

第七步:获取j=7时,nextval[]的值,相应next[]=,查看T[]字符为'b',而当前T[]='a',不相同,那么nextval[]就等于原来的next[]值为2

第八步:获取j=8时,nextval[]的值,相应next[]=,查看T[]字符为'b',而当前T[8]='b',相同,那么nextval[]=nextval[]=
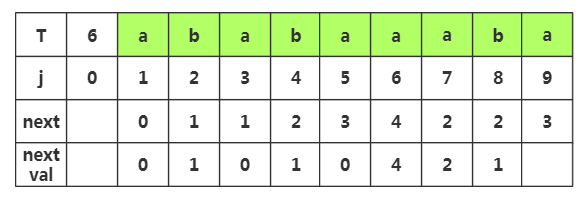
第九步:获取j=9时,nextval[]的值,相应next[]=,查看T[]字符为'a',而当前T[]='a',相同,那么nextval[]=nextval[]=
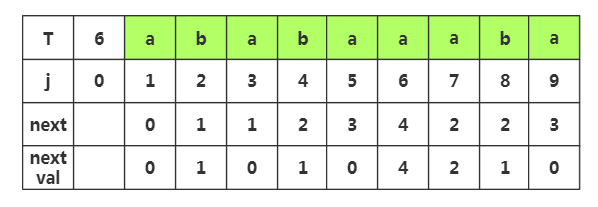
推导2:对上面进行优化的步骤演示
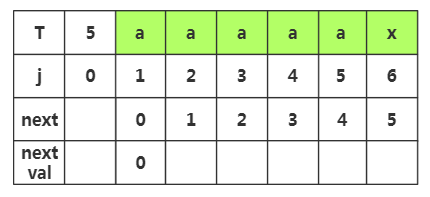
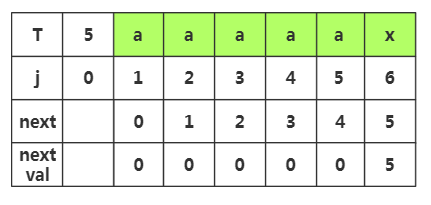
第一步:当j=1时,nextval=0
第二步:当j=2时,next[2]=1,T[2]=T[1]='a',nextval[2]=nextval[1]=0
第三步:当j=3时,next[3]=2,T[3]=T[2]='a',nextval[3]=nextval[2]=0
第四步:当j=4时,next[4]=3,T[4]=T[3]='a',nextval[4]=nextval[3]=0
第五步:当j=5时,next[5]=4,T[5]=T[4]='a',nextval[5]=nextval[4]=0
第六步:当j=6时,next[6]=5,T[6]='x',T[5]='a',T[6]≠T[5],nextval[6]=next[6]=5
nextval数组优化代码
void get_nextval(String T, int* nextval)
{
int m, j;
j = ; //j是后缀的末尾下标
m = ; //m代表的是前缀结束时的下标
nextval[] = ;
while (j < T[])
{
if (m == || T[m] == T[j]) //T[m]表示前缀的最末尾字符,T[j]是后缀的最末尾字符
{
++m;
++j;
if (T[j] != T[m]) //若当前字符与前缀字符不同
nextval[j] = m; //则当前的j为nextval在i位置的值
else
nextval[j] = nextval[m]; //若与前缀字符相同,则将前缀字符的nextval值赋给nextval在i位置的值
}
else
m = nextval[m]; //若是字符不相同,则m回溯
}
}
总结:
若是迷迷糊糊,不如在演草纸上多默写几遍,慢慢就会有思路了...
数据结构(三)串---KMP模式匹配算法实现及优化的更多相关文章
- 【Java】 大话数据结构(8) 串的模式匹配算法(朴素、KMP、改进算法)
本文根据<大话数据结构>一书,实现了Java版的串的朴素模式匹配算法.KMP模式匹配算法.KMP模式匹配算法的改进算法. 1.朴素的模式匹配算法 为主串和子串分别定义指针i,j. (1)当 ...
- 大话数据结构(8) 串的模式匹配算法(朴素、KMP、改进算法)
--喜欢记得关注我哟[shoshana]-- 目录 1.朴素的模式匹配算法2.KMP模式匹配算法 2.1 KMP模式匹配算法的主体思路 2.2 next[]的定义与求解 2.3 KMP完整代码 2.4 ...
- 数据结构(三)串---KMP模式匹配算法
(一)定义 由于BF模式匹配算法的低效(有太多不必要的回溯和匹配),于是某三个前辈发表了一个模式匹配算法,可以大大避免重复遍历的情况,称之为克努特-莫里斯-普拉特算法,简称KMP算法 (二)KMP算法 ...
- 数据结构(三)串---KMP模式匹配算法之获取next数组
(一)获取模式串T的next数组值 1.回顾 我们所知道的KMP算法next数组的作用 next[j]表示当前模式串T的j下标对目标串S的i值失配时,我们应该使用模式串的下标为next[j]接着去和目 ...
- 数据结构学习:KMP模式匹配算法
有关KMP的算法具体的实现网上有很多,不具体阐述.这里附上c的实现. 谈谈我自己的理解.KMP相较于朴素算法,其主要目的是为了使主串中的遍历参数i不回溯,而直接改变目标串中的遍历参数j. 比如说要是目 ...
- 线性表-串:KMP模式匹配算法
一.简单模式匹配算法(略,逐字符比较即可) 二.KMP模式匹配算法 next数组:j为字符序号,从1开始. (1)当j=1时,next=0: (2)当存在前缀=后缀情况,next=相同字符数+1: ( ...
- [从今天开始修炼数据结构]串、KMP模式匹配算法
[从今天开始修炼数据结构]基本概念 [从今天开始修炼数据结构]线性表及其实现以及实现有Itertor的ArrayList和LinkedList [从今天开始修炼数据结构]栈.斐波那契数列.逆波兰四则运 ...
- 数据结构- 串的模式匹配算法:BF和 KMP算法
数据结构- 串的模式匹配算法:BF和 KMP算法 Brute-Force算法的思想 1.BF(Brute-Force)算法 Brute-Force算法的基本思想是: 1) 从目标串s 的第一个字 ...
- 《数据结构》之串的模式匹配算法——KMP算法
//串的模式匹配算法 //KMP算法,时间复杂度为O(n+m) #include <iostream> #include <string> #include <cstri ...
随机推荐
- FSM Code Generator
FSM Code Generator is a script code generator for Finite State Machine, it has a viaual designer bas ...
- 212. Space Replacement【LintCode by java】
Description Write a method to replace all spaces in a string with %20. The string is given in a char ...
- Windos 下python2.7安装 pymssql 解决方案
最近在学python,到安装pymssql这一块遇到了不少问题. 第一:如何安装python 模块,也是最主要的问题. 可以这么理解:在安装python其它模块之前,可以先安装一个负责安装模块的模块. ...
- PHP学习笔记1
1.什么是PHP? Hypertext Preprocessor(超文本预处理语言). 是脚本语言. 是最流行的网站开发语言. 2.PHP能做什么? 可以生成动态页面内容. 可以创建.打开.读取.写入 ...
- NServiceBus官方文档翻译(二)NServiceBus 入门
在这篇教程中我们将学习如何创建一个非常简单的由客户端向服务端发送消息的订单系统.该系统包括三个项目:Client.Server 和 Messages,我们将按照以下步骤来完成这个任务. 创建 Clie ...
- php 中的 “!=”和“!==”
!==是指绝对不等于,比如,$a = 2, $b=”2″ 那么,$a!==$b成立,可是$a!=$b不成立:
- 深入理解ajax系列第八篇——表单提交
前面的话 在以前,网站的用户与后端交互的主要方式是通过HTML表单的使用.表单的引入在1993年,由于其简单性和易用性,直到电子商务出现之前一直保持着重要位置.理解表单提交,对于更深入地理解ajax是 ...
- BZOJ 4242 水壶(BFS建图+最小生成树+树上倍增)
题意 JOI君所居住的IOI市以一年四季都十分炎热著称. IOI市是一个被分成纵H*横W块区域的长方形,每个区域都是建筑物.原野.墙壁之一.建筑物的区域有P个,编号为1...P. JOI君只能进入建筑 ...
- 51nod 1206 && hdu 1828 Picture (扫描线+离散化+线段树 矩阵周长并)
1206 Picture 题目来源: IOI 1998 基准时间限制:2 秒 空间限制:131072 KB 分值: 160 难度:6级算法题 收藏 关注 给出平面上的N个矩形(矩形的边平行于X轴 ...
- 导致 KEIL error #20 的一种情况
> 描述 <+> 环境为 KEIL5.20 & STM32F429工程,平台为 win10 <+> 结构体原形如下 @File <A.h> #incl ...