solr(二) : 整合ik-analyzer
一. 问题:
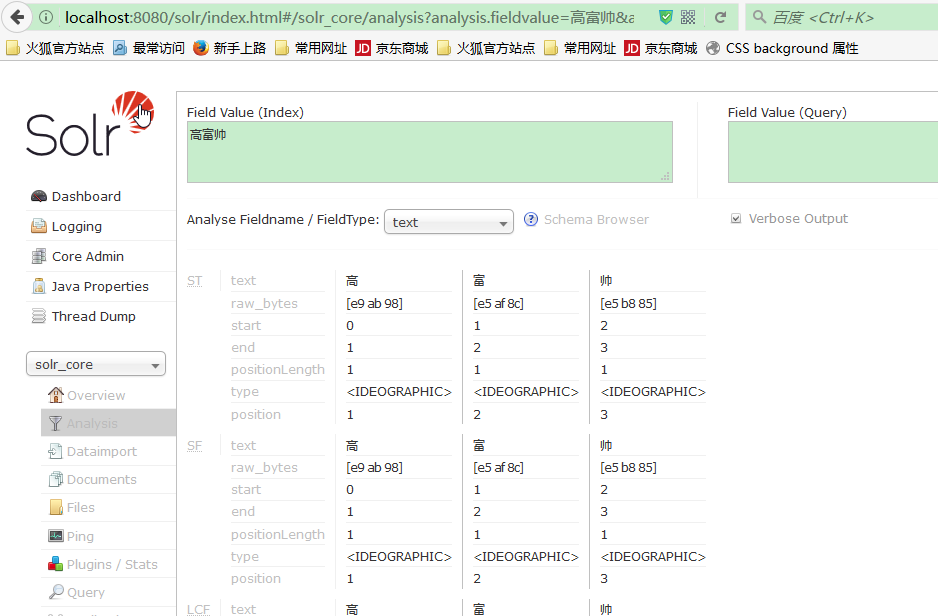
在使用solr时, 分词器解析中文的时候, 是一个一个字解析的. 这并不是我们想要的结果.
而在lucene中, 使用的中文分词器是 IKAnalyzer. 那么在solr里面, 是不是任然可以用这个呢.
二. 整合 ik
1. 修改schema配置文件
打开如下路径中的managed-schema.xml文件.

在文档的最后面, 加入
<!--新建 使用 ik 分词器 解析 的域类型, 分词,过滤都在类里面了-->
<fieldType name="text_ik_type" class="solr.TextField">
<analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType> <!-- <fieldType name="text_ik_type" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf" />
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf" />
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
</analyzer>
</fieldType> -->
<!--支持ik分词器的域-->
<field name="title_ik" type="text_ik_type" indexed="true" stored="true" />
<field name="content_ik" type="text_ik_type" indexed="true" stored="true" multiValued="true"/>
<field name="text_ik" type="text_ik_type" multiValued="true" indexed="true" stored="true"/>
2. 加入jar包
在tomcat solr lib中加入ik分词器的jar包


jar包可以在这里下载: http://download.csdn.net/download/z____l/10176803
3. 加入分词器配置文件
将前面lucene 里面出现过的 配置文件拷贝到 classes 文件夹下. 不拷贝也行, 自己新建也可以.

由于这里我并没有使用文件夹装ext,stopword, 所以 IKAnalyzer.cfg.xml文件要做部分修改.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry> <!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic</entry> </properties>
三. 结果

solr(二) : 整合ik-analyzer的更多相关文章
- 全文检索引擎Solr系列——整合中文分词组件IKAnalyzer
IK Analyzer是一款结合了词典和文法分析算法的中文分词组件,基于字符串匹配,支持用户词典扩展定义,支持细粒度和智能切分,比如: 张三说的确实在理 智能分词的结果是: 张三 | 说的 | 确实 ...
- solr添加中文IK分词器,以及配置自定义词库
Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置,而且附带了一个基于H ...
- Lucene全文搜索之分词器:使用IK Analyzer中文分词器(修改IK Analyzer源码使其支持lucene5.5.x)
注意:基于lucene5.5.x版本 一.简单介绍下IK Analyzer IK Analyzer是linliangyi2007的作品,再此表示感谢,他的博客地址:http://linliangyi2 ...
- Solr学习(2) Solr4.2.0+IK Analyzer 2012
Solr学习(二) Solr4.2.0+IK Analyzer 2012 开场白: 本章简单讲述如何在solr中配置著名的 IK Analyzer 分词器. 本章建立在 Solr学习(一) 基础上进 ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- Win7下Solr4.10.1和IK Analyzer中文分词
1.下载IK中文分词压缩包IK Analyzer 2012FF_hf1,并解压到D:\IK Analyzer 2012FF_hf1: 2.将D:\IK Analyzer 2012FF_hf1\IKAn ...
- 对本地Solr服务器添加IK中文分词器实现全文检索功能
在上一篇随笔中我们提到schema.xml中<field/>元素标签的配置,该标签中有四个属性,分别是name.type.indexed与stored,这篇随笔将讲述通过设置type属性的 ...
- solr+tomcat整合
一.solr安装 http://archive.apache.org/dist/lucene/solr/ 这个地址有各个版本的 这次我使用的是5.5.4版本和tomcat8 版本5.5.4已经内置了j ...
随机推荐
- (区间dp 或 记忆化搜素 )Brackets -- POJ -- 2955
http://poj.org/problem?id=2955 Description We give the following inductive definition of a “regular ...
- 配置SecureCRT密钥连接Linux
SSH公钥加密的方式使得对方即使截取了帐号密码,在没有公钥私钥的情况下,依然无法远程ssh登录系统,这样就大大加强了远程登录的安全性. 1. 编辑配置文件 /etc/ssh/sshd_c ...
- tomcat配置之后,localhost:8080访问不到猫界面解决办法
- 数字签名、数字证书的原理以及证书的获得java版
数字签名原理简介(附数字证书) 首先要了解什么叫对称加密和非对称加密,消息摘要这些知识. 1. 非对称加密 在通信双方,如果使用非对称加密,一般遵从这样的原则:公钥加密,私钥解密.同时,一般一个密钥加 ...
- 安装部署Ceph Calamari
根据http://ovirt-china.org/mediawiki/index.php/%E5%AE%89%E8%A3%85%E9%83%A8%E7%BD%B2Ceph_Calamari 原文如下: ...
- OS基础:动态链接库(一)
动态链接库(一) 1.新建文件夹,命名lpt 2.用vc6.0建立一个空工程(Win 32 Dynamic-Link Library),名称:lptDll1 3.新建C++文件,命名:lptDll1: ...
- 用C#中的键值对遍历数组或字符串元素的次数
代码如下: string strs = "ad6la4ss42d6s3"; Dictionary<char, int> dic = new Dictionary< ...
- XML随笔:语法快速入门及当下流行的RSS简析
今天是本人第一次写博客,之前闭门造车闹出过很多笑话,恰巧这几天刚刚重温了一遍XML的知识,决定把XML的知识再来从头到尾的理一遍,感触颇多,今天分享给大家.希望大家能多多注意其中的要点. 1.定义 首 ...
- 背水一战 Windows 10 (43) - C# 7.0 新特性
[源码下载] 背水一战 Windows 10 (43) - C# 7.0 新特性 作者:webabcd 介绍背水一战 Windows 10 之 C# 7.0 新特性 介绍 C# 7.0 的新特性 示例 ...
- MQ的demo
public class WorkTest { @Test public void send() throws Exception{ //获取连接 Connection conn = ...