Deep learning with Python 学习笔记(2)
本节介绍基于Keras的CNN
卷积神经网络接收形状为 (image_height, image_width, image_channels)的输入张量(不包括批量维度),宽度和高度两个维度的尺寸通常会随着网络加深而变小。通道数量由传入 Conv2D 层的第一个参数所控制
用卷积神经网络对 MNIST 数字进行分类Demo
from keras import layers
from keras import models
from keras.datasets import mnist
from keras.utils import to_categorical
def set_model():
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 需要将 3D 输出展平为 1D,将(3, 3, 64)输出展平为(576, )
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# 查看模型各层状态
model.summary()
return model
(train_images, train_labels), (test_images, test_labels) = mnist.load_data(path='/home/fan/dataset/mnist.npz')
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model = set_model()
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(test_acc)
运行之后,显示正确率为0.9921,而之前使用的密集连接网络的正确率为0.9794,提高了0.0127
密集连接层和卷积层的根本区别在于, Dense 层从输入特征空间中学到的是全局模式,如果模式出现在新的位置,它只能重新学习这个模式,而卷积层学到的是局部模式,可以在任何位置进行匹配
学习局部模式使得CNN具有以下性质:
- 卷积神经网络学到的模式具有平移不变性(translation invariant)
卷积神经网络在图像右下角学到某个模式之后,它可以在任何地方识别这个模式,比如左上角
对于密集连接网络来说,如果模式出现在新的位置,它只能重新学习这个模式
- 卷积神经网络可以学到模式的空间层次结构(spatial hierarchies of patterns)
第一个卷积层将学习较小的局部模式(比如边缘),第二个卷积层将学习由第一层特征组成的更大的模式,以此类推。这使得卷积神经网络可以有效地学习越来越复杂、越来越抽象的视觉概念(因为视觉世界从根本上具有空间层次结构)
对于包含两个空间轴(高度和宽度)和一个深度轴(也叫通道轴)的 3D 张量,其卷积也叫特征图(feature map)。卷积运算从输入特征图中提取图块,并对所有这些图块应用相同的变换,生成输出特征图(output feature map)。该输出特征图仍是一个 3D 张量,具有宽度和高度,其深度可以任意取值,因为输出深度是层的参数,深度轴的不同通道不再像 RGB 输入那样代表特定颜色,而是代表过滤器(filter)。过滤器对输入数据的某一方面进行编码
上例中,模型定义了
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
该卷积层接收一个大小为 28 * 28 * 1 的特征图,输出一个 26 * 26 * 32 的特征图(26 = (28 -3) / 1 + 1),该26 * 26 * 32是过滤器对输入的响应图(response map),表示这个过滤器模式在输入中不同位置的响应。这也是特征图这一术语的含义: 深度轴的每个维度都是一个特征(或过滤器),而 2D 张量 output[:, :, n]是这个过滤器在输入上的响应的二维空间图(map)
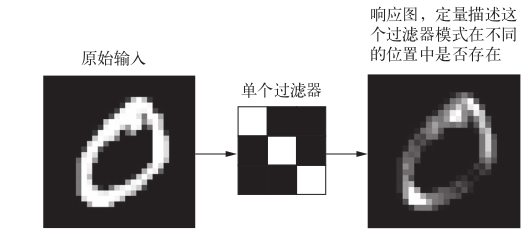
卷积由以下两个关键参数所定义
- 从输入中提取的图块尺寸: 这些图块的大小通常是 3×3 或 5×5
- 输出特征图的深度:卷积所计算的过滤器的数量
对于 Keras 的 Conv2D 层,这些参数都是向层传入的前几个参数:Conv2D(output_depth, (window_height, window_width))
卷积的工作原理
在 3D 输入特征图上滑动(slide)这些 3×3 或 5×5 的窗口,在每个可能的位置停止并提取周围特征的 3D 图块[形状为 (window_height, window_width, input_depth) ]。然后每个 3D 图块与学到的同一个权重矩阵[叫作卷积核(convolution kernel)]做张量积,转换成形状为 (output_depth,) 的 1D 向量。然后对所有这些向量进行空间重组,使其转换为形状为 (height, width, output_depth) 的 3D 输出特征图。输出特征图中的每个空间位置都对应于输入特征图中的相同位置
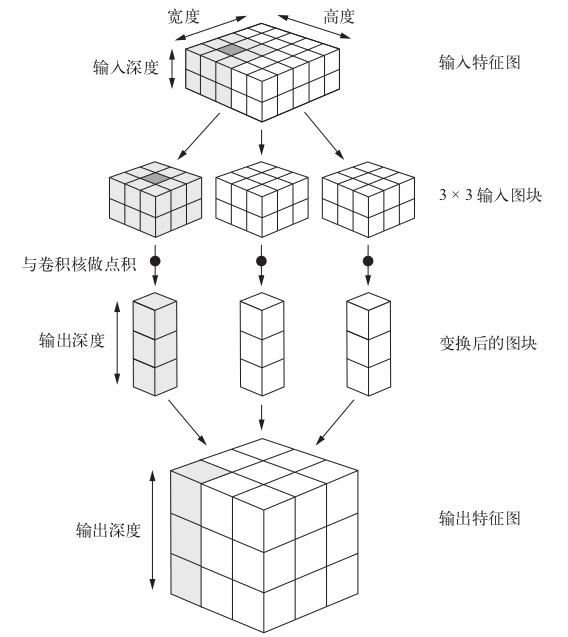
卷积计算

可见,当特征图通过卷积核之后,特征图的尺寸变小,具体变化为
\]
其中,outputSize 为输出尺寸,inputSize 为输入尺寸,ConvSize为卷积核尺寸,padding 为填充,stride 为步幅
对于 Conv2D 层,可以通过 padding 参数来设置填充,这个参数有两个取值: "valid" 表示不使用填充(只使用有效的窗口位置);"same" 表示“填充后输出的宽度和高度与输入相同”。padding 参数的默认值为 "valid"
最大池化通常使用 2×2 的窗口和步幅 2,其目的是将特征图下采样 2 倍。与此相对的是,卷积通常使用 3×3 窗口和步幅 1
通过池化,我们可以减少参数数量,防止过拟合,同时可以使得之后的卷积相对于之前的获得更大的视野,从而更好地学习特征的空间层级结构
卷积神经网络主要由 Conv2D 层(使用 relu 激活)和MaxPooling2D 层交替堆叠构成,当要处理更大的图像和更复杂的问题时,需要相应的增大网络,即可以再增加一个 Conv2D + MaxPooling2D 的组合。这既可以增大网络容量,也可以进一步减小特征图的尺寸,使其在连接 Flatten 层时尺寸不会太大
在向网络中输入数据时,我们首先需要将数据进行预处理,将其格式化为浮点数张量,JPEG数据处理步骤如下
- 读取图像
- 将JPEG文件解码为RGB像素网络
- 将像素网络转换为浮点数张量
- 将像素值缩放到[0, 1]区间
当数据量较大时,我们可以采用生成器的方式将数据依次喂给网络来进行拟合
Keras包含ImageDataGenerator 类,可以快速创建 Python 生成器,能够将硬盘上的图像文件自动转换为预处理好的张量批量
让模型对数据拟合
model.fit_generator(train_generator, steps_per_epoch=100, epochs=30,
validation_data=validation_generator, validation_steps=50)
第一个参数为数据生成器,第二个参数表示从生成器中抽取 steps_per_epoch 个批量后(即运行了steps_per_epoch 次梯度下降),拟合过程将进入下一个轮次,第三个参数为验证数据,如果其为一个数据生成器的话,需要指定validation_steps参数,来说明需要从验证生成器中抽取多少个批次用于评估
Keras保存模型
model.save('\*\*\*.h5')
一个使用CNN的猫狗分类Demo
数据集下载
此处为了快速得到结果,使用猫狗各1000个图像训练,各500个验证,各500个测试
from keras import layers
from keras import models
from keras import optimizers
import os
import matplotlib.pyplot as plt
def get_model():
# 猫狗二分类
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
# 显示模型各层信息
model.summary()
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
return model
from keras.preprocessing.image import ImageDataGenerator
def data_preprocess(train_dir, validation_dir):
# Python生成器会不断循环目标文件夹中的图像,从而会不停地生成批量
# 将图像乘1/255缩放
train_datagen = ImageDataGenerator(rescale=1. / 255)
test_datagen = ImageDataGenerator(rescale=1. / 255)
# 将所有文件调整为150 * 150
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(150, 150), batch_size=20, class_mode='binary')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(150, 150), batch_size=20, class_mode='binary')
return train_generator, validation_generator
base_dir = '/home/fan/dataset/dogVScat/testDogVSCat'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
train_generator, validation_generator = data_preprocess(train_dir, validation_dir)
model = get_model()
history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=30, validation_data=validation_generator, validation_steps=50)
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
实验结果
loss: 0.0304 - acc: 0.9925 - val_loss: 1.2209 - val_acc: 0.7010

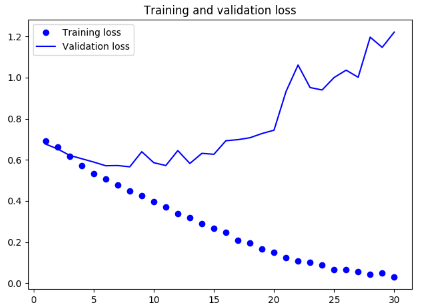
从如上结果可以看出,我们的网络过拟合了,可以使用数据增强的方式来防止过拟合
数据增强是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的随机变换来增加(augment)样本。其目标是,模型在训练时不会两次查看完全相同的图像。这让模型能够观察到数据的更多内容,从而具有更好的泛化能力
在 Keras 中,这可以通过对 ImageDataGenerator 实例读取的图像执行多次随机变换来实现
Demo
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest')
其中
rotation_range 是角度值(在 0~180 范围内),表示图像随机旋转的角度范围
width_shift 和 height_shift 是图像在水平或垂直方向上平移的范围(相对于总宽度或总高度的比例)
shear_range 是随机错切变换的角度
zoom_range 是图像随机缩放的范围
horizontal_flip 是随机将一半图像水平翻转
fill_mode 是用于填充新创建像素的方法,这些新像素可能来自于旋转或宽度 / 高度平移
使用数据增强的方法增加数据
from keras.preprocessing import image
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
img_path = '/home/fan/dataset/dogVScat/testDogVSCat/train/dogs/dog.77.jpg'
# 加载图片并调整尺寸
img = np.asarray(image.load_img(img_path, target_size=(150, 150)))
datagen = ImageDataGenerator(rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest')
plt.imshow(img)
plt.title('original img')
plt.show()
img = img.reshape((1, ) + img.shape)
i = 0
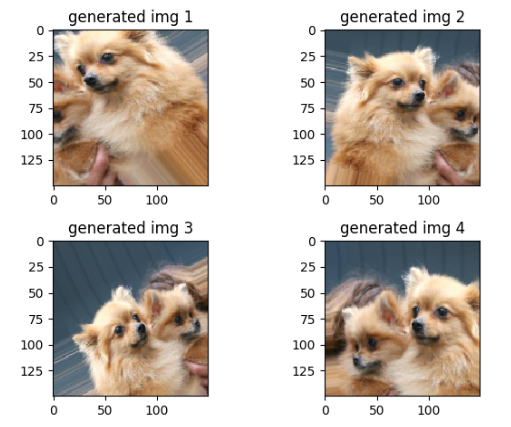
for item in datagen.flow(img, batch_size=1):
item = image.array_to_img(item[0])
plt.subplot(2, 2, i+1)
plt.imshow(item)
i += 1
plt.title('generated img ' + str(i))
if i % 4 == 0:
break
plt.show()
结果如下

为了继续降低过拟合,可以再向网络中添加dropout。Keras向网络中添加dropout
model.add(layers.Dropout(0.5))
通过使用数据增强,正则化以及调节网络参数可以在一定程度上提高精度,但是因为数据较少,想要进一步提高精度就需要使用预训练的模型
Deep learning with Python 学习笔记(3)
Deep learning with Python 学习笔记(1)
Deep learning with Python 学习笔记(2)的更多相关文章
- Deep learning with Python 学习笔记(11)
总结 机器学习(machine learning)是人工智能的一个特殊子领域,其目标是仅靠观察训练数据来自动开发程序[即模型(model)].将数据转换为程序的这个过程叫作学习(learning) 深 ...
- Deep learning with Python 学习笔记(10)
生成式深度学习 机器学习模型能够对图像.音乐和故事的统计潜在空间(latent space)进行学习,然后从这个空间中采样(sample),创造出与模型在训练数据中所见到的艺术作品具有相似特征的新作品 ...
- Deep learning with Python 学习笔记(9)
神经网络模型的优化 使用 Keras 回调函数 使用 model.fit()或 model.fit_generator() 在一个大型数据集上启动数十轮的训练,有点类似于扔一架纸飞机,一开始给它一点推 ...
- Deep learning with Python 学习笔记(8)
Keras 函数式编程 利用 Keras 函数式 API,你可以构建类图(graph-like)模型.在不同的输入之间共享某一层,并且还可以像使用 Python 函数一样使用 Keras 模型.Ker ...
- Deep learning with Python 学习笔记(7)
介绍一维卷积神经网络 卷积神经网络能够进行卷积运算,从局部输入图块中提取特征,并能够将表示模块化,同时可以高效地利用数据.这些性质让卷积神经网络在计算机视觉领域表现优异,同样也让它对序列处理特别有效. ...
- Deep learning with Python 学习笔记(6)
本节介绍循环神经网络及其优化 循环神经网络(RNN,recurrent neural network)处理序列的方式是,遍历所有序列元素,并保存一个状态(state),其中包含与已查看内容相关的信息. ...
- Deep learning with Python 学习笔记(5)
本节讲深度学习用于文本和序列 用于处理序列的两种基本的深度学习算法分别是循环神经网络(recurrent neural network)和一维卷积神经网络(1D convnet) 与其他所有神经网络一 ...
- Deep learning with Python 学习笔记(4)
本节讲卷积神经网络的可视化 三种方法 可视化卷积神经网络的中间输出(中间激活) 有助于理解卷积神经网络连续的层如何对输入进行变换,也有助于初步了解卷积神经网络每个过滤器的含义 可视化卷积神经网络的过滤 ...
- Deep learning with Python 学习笔记(3)
本节介绍基于Keras的使用预训练模型方法 想要将深度学习应用于小型图像数据集,一种常用且非常高效的方法是使用预训练网络.预训练网络(pretrained network)是一个保存好的网络,之前已在 ...
随机推荐
- SPRING框架中ModelAndView、Model、ModelMap区别及详细分析
转载内容:http://www.cnblogs.com/google4y/p/3421017.html 1. Model Model 是一个接口, 其实现类为ExtendedModelMap,继承了M ...
- 论EFMS模拟量部分采集电路的修改
论1:电阻R11的作用 如图1是2014-3-11之前模拟量采集的部分硬件电路,图2是纠正后的正确电路. D5是SA20CA,TVS双向二极管,有效防止外接电源的浪涌冲击情况,保护电路. D6是稳压 ...
- pycharm的基本使用
1.设置注释字体的颜色,如下图 2.常用快捷键 Ctrl + Space 基本的代码完成(类.方法.属性) Ctrl + Alt + Space 类名完成 Ctrl + Shift + Enter 语 ...
- 探索基于.NET下实现一句话木马之asmx篇
0x01 前言 上篇介绍了一般处理程序(ashx)的工作原理以及实现一句话木马的过程,今天接着介绍Web Service程序 (asmx)下的工作原理和如何实现一句话木马,当然介绍之前笔者找到了一款a ...
- c#中快速排序的学习
最近看了一句话,说的是在现实生活中,会写字的人不见得会写出好文章,学习编程语言就像是学会了写字,学会了编程语言并不一定能写出好程序. 我觉得就是很有道理,以前读书的时候,基本学完了C#中的语法知识,算 ...
- 在Winform中菜单动态添加“最近使用文件”
最近在做文件处理系统中,要把最近打开文件显示出来,方便用户使用.网上资料有说,去遍历“C:\Documents and Settings\Administrator\Recent”下的最近文档本.文主 ...
- [ActionScript 3.0] as3处理xml的功能和遍历节点
as3比as2处理xml的功能增强了N倍,获取或遍历节点非常之方便,类似于json对像的处理方式. XML 的一个强大功能是它能够通过文本字符的线性字符串提供复杂的嵌套数据.将数据加载到 XML 对象 ...
- zabbix 监控安装
注意:此篇是在安装好lnmp环境后才能部署的操作,所以,做之前准备好lnmp环境,或者可以参考我做的lnmp环境,之后接着此篇开始安装 监控系统Zabbix-3.2.1的安装 zabbix-serve ...
- JQuery 限制文本输入只能输入数字(可自定义正则表达式)
var JVerify = { role: { number: /[0-9\/]/, decimal: /[0-9\.\/]/, code: /[0-9A-Z]/ }, Verify: functio ...
- GITLAB安装笔记
CentOS 7 最小安装后操作 设置时区timedatectl set-timezone Asia/Shanghai 添加 Gitlab 清华源 vi /etc/yum.repos.d/gitlab ...