SQLServer中利用NTILE函数对数据进行分组的一点使用
本文出处:http://www.cnblogs.com/wy123/p/6908377.html
NTILE函数可以按照指定的排序规则,对数据按照指定的组数(M个对象,按照某种排序分N个组)进行分组,可以展现出某一条数据被分配在哪个组中.
不仅可以单单利用这个特性,还可以借助该特实现更加有意思的功能.
NTILE的基本使用
NTILE的作用是对数据进行整体上的分组,比如有60个学生,按照成绩分成“上中下”三个级别,可以看出那些人位于哪个级别,用NTILE函数就可以实现。
比如这里的简单的示例,有六个学生,按照成绩,分成三组,可以看到,每个人位于哪一组中(或者说哪个人位于哪个层次)
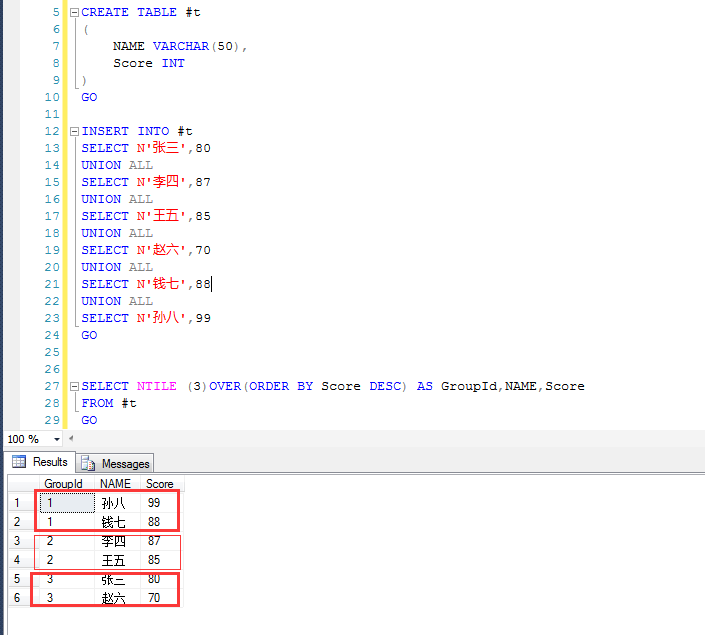
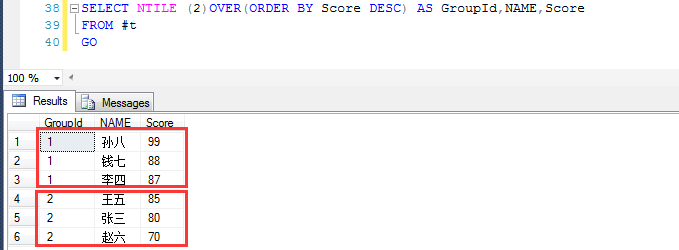
当然也可以分成两组,分组和排序方式由NTILE (N)OVER(ORDER BY *** ASC | DESC) 决定
在NTILE的分组功能上扩展
当然这个应用还可以扩展,借助其扩展功能,可以完成很多个性化的需求。
最近遇到一个需求,要处理一批历史数据,目的是根据其Id,经过一系列的逻辑运算(存储过程实现),计算生成这个Id的某些属性,
正常情况下是循环表中的每一行数据,分别传入存储过程进行处理。
/*
DECLARE @id INT = 0
DECLARE @achived bit = 1
while @achived>0
begin
select top 1 @id = id from business_table order by id
insert into deal_result
exec deal_procrdure @id
delete from t where business_table = @id
if exists (select 1 from t)
set @achived = 1
else
set @achived = 0
end
*/
但是考虑到business_table的数据量太大,单个Session运算起来可能要花费太久的时间,
因此要考虑使用多个Session,每个Session分别计算一部分数据,这样就可以加快数据的生成效率。
比如有1000W行数据,使用10个Session,每个Session计算100W行,这样比一个Session计算1000W行数据,理论上要快10倍
那么这里就涉及到一个分组的问题,鉴于数据的特点,其Id是唯一的但不连续的,
比如要分成10组,如何通过Id的范围,确保每组的数据量基本上相同?
一开始是采用比较笨的方法,利用top,比如前100W行数据,可以这样
select max(id) from
(
select top 100W from t
)t
通过这样,如果最大的id为Id1,那么前100W行的数据范围为0~Id1。
对于第二个100W行的数据,可以计算前200W行的max(id)
select max(id) from
(
select top 200W from t
)t
如果最大的id为Id2,那么第二个100W行的数据范围为Id1~Id2。
然后依次类推,是有点笨……
类似需求可以通过上面提到的NTILE分析函数实现
先上个实例代码,模拟上文提到的Business_table Id唯一但是不连续的情况
DECLARE @i INT = 0
WHILE @i<200000
BEGIN
INSERT INTO TestNtile VALUES (@i,NEWID())
set @i=@i+1
END
GO --随机删除部分数据,模拟Id不是连续的
;WITH del
AS
(
select top 100 * from TestNtile order by NEWID()
)
DELETE FROM del
GO --通过NTILE分成十个组,取每个组的最大值
SELECT GroupId,MAX(Id) AS Id
FROM
(
select NTILE (10)over(order by Id) as GroupId,Id
from TestNtile
)t
GROUP BY GroupId
GO
原理正如备注中的写的,利用NTILE函数,对数据整体上分成10组,取每个组的最大值,就可以确定每个组的Id的区间范围了。
参考下图,将测试数据分成10组,分别取得每个组的最大Id值,就可以确定每个组的Id的范围了。
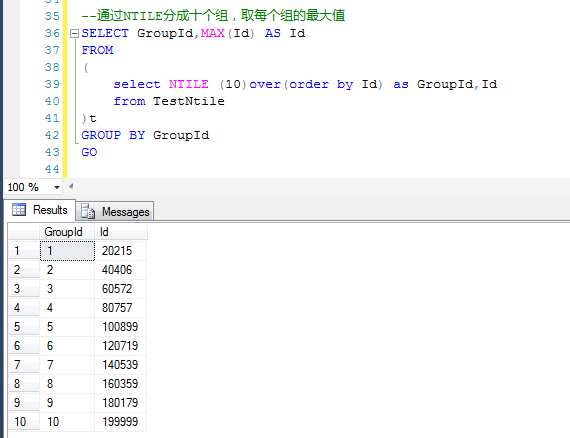
这样就很容易确定,第一组的Id的范围是0~20215,第二组的范围是20216~40406,第三组的范围是40406~60572……
计算出来范围之后,可以通过启动多个Session来循环计算,或者是交给应用程序的多个线程,让每个线程分别处理每一个范围内的Id
很基础的问题,就不总结了。
SQLServer中利用NTILE函数对数据进行分组的一点使用的更多相关文章
- (转)笔记320 SQLSERVER中的加密函数 2013-7-11
1 --SQLSERVER中的加密函数 2013-7-11 2 ENCRYPTBYASYMKEY() --非对称密钥 3 ENCRYPTBYCERT() --证书加密 4 ENCRYPTBYKEY() ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- SQLServer中处理亿万级别的数据
在SQLServer中处理亿万级别的数据(历史数据),可以按以下方面进行: 去掉表的所有索引 用SqlBulkCopy进行插入 分表或者分区,减少每个表的数据总量 在某个表完全写完之后再建立索引 正确 ...
- SQLSERVER中的 CEILING函数和 FLOOR函数
SQLSERVER中的 CEILING函数和 FLOOR函数 --SQLSERVER中的 CEILING函数和 FLOOR函数 --ceiling函数返回大于或等于所给数字表达式的最小整数. --fl ...
- 【转载】Sqlserver中使用Round函数对计算结果四舍五入
在实际应用的计算中,很多时候我们需要对最后计算结果四舍五入,其实在Sqlserver中也有对应的四舍五入函数,就是Round函数,Round函数的格式为Round(column_name,decima ...
- SQLServer中间接实现函数索引或者Hash索引
本文出处:http://www.cnblogs.com/wy123/p/6617700.html SQLServer中没有函数索引,在某些场景下查询的时候要根据字段的某一部分做查询或者经过某种计算之后 ...
- 【转载】 Sqlserver中查看自定义函数被哪些对象引用
Sqlserver数据库中支持自定义函数,包含表值函数和标量值函数,表值函数一般返回多个数据行即数据集,而标量值函数一般返回一个值,在数据库的存储过程中可调用自定义函数,也可在该自定义函数中调用另一个 ...
- sqlserver中的聚合函数
聚合函数:就是按照一定的规则将多行(Row)数据汇总成一行的函数,对数据进行汇总前,还可以按特定的列(coloumn)将数据进行分组(group by)再汇总,然后按照再次给定的条件进行筛选 一:Co ...
- SQLserver中常用的函数及实例
聚合函数 as是可以起别名的,在select和from之间的是表示列名,可以不加单引号)(聚合函数中的count不仅能对数字进行操作还能对字符型进行操作,其余的只能对数字操作) 最小值 select ...
随机推荐
- SAS FORMAT 逻辑库存储 【输出格式 没有找到或无法加载】解决方法
SAS FORMAT 逻辑库存储 [输出格式 没有找到或无法加载]解决方法:需要指定FORMAT 搜索的路径:OPTIONS FMTSEARCH=(F WORK); 以下为完整示例代码: 00@DA ...
- TensorFlow安装教程(ubuntu 18.04)
此教程的硬件条件: 1.Nvidia GPU Geforce390及以上 2.Ubuntu 18.04操作系统 3.Anaconda工具包 如果python版本为3.7及以上,使用如下命令降级到3.6 ...
- Javascript-string-Array
1.得到数组里重复的值 function getRepeat(ar){ //数组排序 var ary = ar.sort(); //创建装重复值的新数组 var newArr = new Array( ...
- hadoop分布式集群的搭建
电脑如果是8G内存或者以下建议搭建3节点集群,如果是搭建5节点集群就要增加内存条了.当然实际开发中不会用虚拟机做,一些小公司刚刚起步的时候会采用云服务,因为开始数据量不大. 但随着数据量的增大才会考虑 ...
- TP微信扫码支付
1.官网下载php扫码支付adk,放在项目引入第三方类库中 2.配置config中相关参数 注意:可能会遇到问题 微信支付错误问题的解决:curl出错,错误码:60 Fatal error: Unca ...
- SQL with(unlock)与with(readpast)
所有Select加 With (NoLock)解决阻塞死锁,在查询语句中使用 NOLOCK 和 READPAST 处理一个数据库死锁的异常时候,其中一个建议就是使用 NOLOCK 或者 READPAS ...
- mysql查询当前时间,一天内,一周,一个月内的sql语句
查询一天:select * from 表名 where to_days(时间字段名) = to_days(now()); 昨天 SELECT * FROM 表名 WHERE TO_DAYS( NOW( ...
- Python之网络编程(Socket)
1.网络通信原理与互联网协议 详见:https://www.cnblogs.com/JackLi07/p/9218039.html 2.socket层 以上是tcp/ip五层协议的结构图,我们没有看到 ...
- TestLink 的使用详解
二.初始配置(设置用户.产品) 1. 用户设置 在TestLink系统中,每个用户都可以维护自己的私有信息.admin可以创建用户,但不能看到其它用户的密码.在用户信息中,需要设置Email地址,如果 ...
- js原生轮播
js原生轮播 今天用js做了轮播图,做的不怎么好,希望大家能够看懂. 效果: 1.鼠标放在轮播图上自动停止 2.鼠标离开轮播图自动播放 3.鼠标点击轮播图上的小圆点跳转到相应的图上. 代码: < ...