43.scrapy爬取链家网站二手房信息-1
首先分析:
目的:采集链家网站二手房数据
1.先分析一下二手房主界面信息,显示情况如下: url = https://gz.lianjia.com/ershoufang/pg1/
显示总数据量为27589套,但是页面只给返回100页的数据,每页30条数据,也就是只给返回3000条数据。
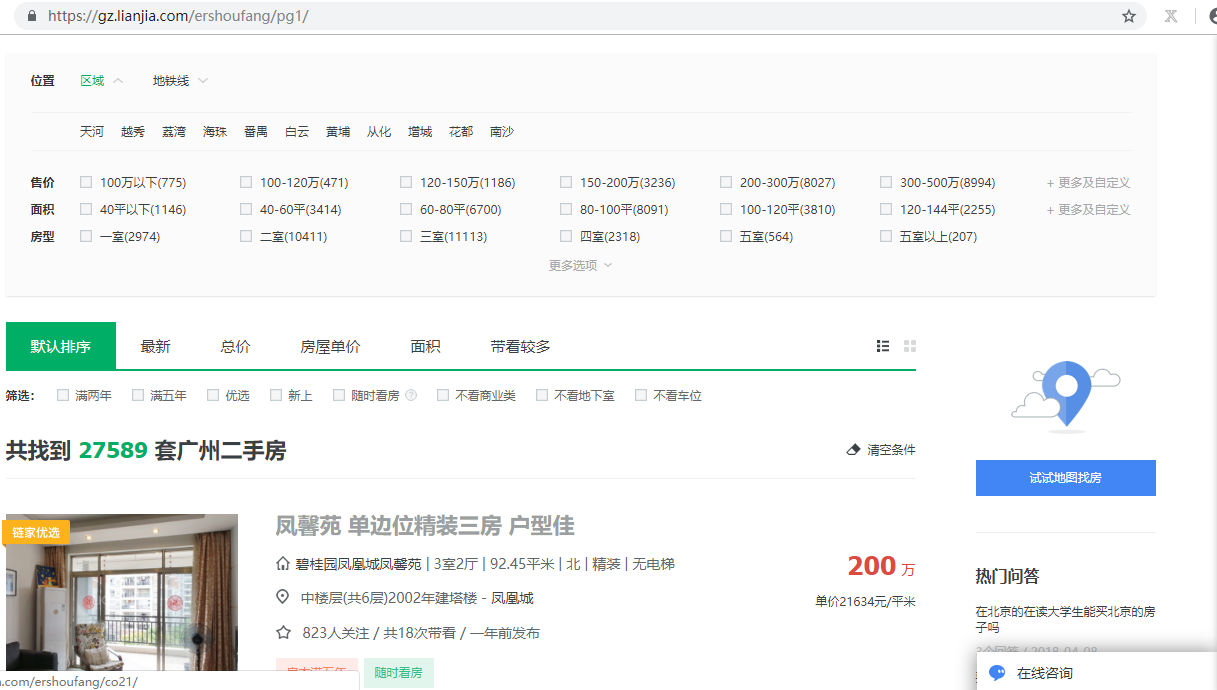
2.再看一下筛选条件的情况: 100万以下(775):https://gz.lianjia.com/ershoufang/pg1p1/(p1是筛选条件参数,pg1是页面参数) 页面返回26页信息
100万-120万(471):https://gz.lianjia.com/ershoufang/pg1p2/ 页面返回16页信息 以此类推也就是网站只给你返回查看最多100页,3000条的数据,登陆的话情况也是一样的情况。
3.采集代码如下:
这个是 linjia.py 文件,这里需要注意的问题就是 setting里要设置
ROBOTSTXT_OBEY = False,不然页面不给返回数据。
# -*- coding: utf-8 -*-
import scrapy class LianjiaSpider(scrapy.Spider):
name = 'lianjia'
allowed_domains = ['gz.lianjia.com']
start_urls = ['https://gz.lianjia.com/ershoufang/pg1/'] def parse(self, response): #获取当前页面url
link_urls = response.xpath("//div[@class='info clear']/div[@class='title']/a/@href").extract()
for link_url in link_urls:
# print(link_url)
yield scrapy.Request(url=link_url,callback=self.parse_detail)
print('*'*100) #翻页
for i in range(1,101):
url = 'https://gz.lianjia.com/ershoufang/pg{}/'.format(i)
# print(url)
yield scrapy.Request(url=url,callback=self.parse) def parse_detail(self,response): title = response.xpath("//div[@class='title']/h1[@class='main']/text()").extract_first()
print('标题: '+ title)
dist = response.xpath("//div[@class='areaName']/span[@class='info']/a/text()").extract_first()
print('所在区域: '+ dist)
contents = response.xpath("//div[@class='introContent']/div[@class='base']")
# print(contents)
house_type = contents.xpath("./div[@class='content']/ul/li[1]/text()").extract_first()
print('房屋户型: '+ house_type)
floor = contents.xpath("./div[@class='content']/ul/li[2]/text()").extract_first()
print('所在楼层: '+ floor)
built_area = contents.xpath("./div[@class='content']/ul/li[3]/text()").extract_first()
print('建筑面积: '+ built_area)
family_structure = contents.xpath("./div[@class='content']/ul/li[4]/text()").extract_first()
print('户型结构: '+ family_structure)
inner_area = contents.xpath("./div[@class='content']/ul/li[5]/text()").extract_first()
print('套内面积: '+ inner_area)
architectural_type = contents.xpath("./div[@class='content']/ul/li[6]/text()").extract_first()
print('建筑类型: '+ architectural_type)
house_orientation = contents.xpath("./div[@class='content']/ul/li[7]/text()").extract_first()
print('房屋朝向: '+ house_orientation)
building_structure = contents.xpath("./div[@class='content']/ul/li[8]/text()").extract_first()
print('建筑结构: '+ building_structure)
decoration_condition = contents.xpath("./div[@class='content']/ul/li[9]/text()").extract_first()
print('装修状况: '+ decoration_condition)
proportion = contents.xpath("./div[@class='content']/ul/li[10]/text()").extract_first()
print('梯户比例: '+ proportion)
elevator = contents.xpath("./div[@class='content']/ul/li[11]/text()").extract_first()
print('配备电梯: '+ elevator)
age_limit =contents.xpath("./div[@class='content']/ul/li[12]/text()").extract_first()
print('产权年限: '+ age_limit)
try:
house_label = response.xpath("//div[@class='content']/a/text()").extract_first()
except:
house_label = ''
print('房源标签: ' + house_label)
# decoration_description = response.xpath("//div[@class='baseattribute clear'][1]/div[@class='content']/text()").extract_first()
# print('装修描述 '+ decoration_description)
# community_introduction = response.xpath("//div[@class='baseattribute clear'][2]/div[@class='content']/text()").extract_first()
# print('小区介绍: '+ community_introduction)
# huxing_introduce = response.xpath("//div[@class='baseattribute clear']3]/div[@class='content']/text()").extract_first()
# print('户型介绍: '+ huxing_introduce)
# selling_point = response.xpath("//div[@class='baseattribute clear'][4]/div[@class='content']/text()").extract_first()
# print('核心卖点: '+ selling_point)
# 以追加的方式及打开一个文件,文件指针放在文件结尾,追加读写!
with open('text', 'a', encoding='utf-8')as f:
f.write('\n'.join(
[title,dist,house_type,floor,built_area,family_structure,inner_area,architectural_type,house_orientation,building_structure,decoration_condition,proportion,elevator,age_limit,house_label]))
f.write('\n' + '=' * 50 + '\n')
print('-'*100)
4.这里采集的是全部,没设置筛选条件,只返回100也数据。
采集数据情况如下:
这里只采集了15个字段信息,其他的数据没采集。
采集100页,算一下拿到了2704条数据。


43.scrapy爬取链家网站二手房信息-1的更多相关文章
- 44.scrapy爬取链家网站二手房信息-2
全面采集二手房数据: 网站二手房总数据量为27650条,但有的参数字段会出现一些问题,因为只给返回100页数据,具体查看就需要去细分请求url参数去请求网站数据.我这里大概的获取了一下筛选条件参数,一 ...
- Python——Scrapy爬取链家网站所有房源信息
用scrapy爬取链家全国以上房源分类的信息: 路径: items.py # -*- coding: utf-8 -*- # Define here the models for your scrap ...
- python - 爬虫入门练习 爬取链家网二手房信息
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db&qu ...
- python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1.问题描述: 爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目标网址:https://sz.lianjia.com ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- Python爬取链家二手房源信息
爬取链家网站二手房房源信息,第一次做,仅供参考,要用scrapy. import scrapy,pypinyin,requests import bs4 from ..items import L ...
- python3 爬虫教学之爬取链家二手房(最下面源码) //以更新源码
前言 作为一只小白,刚进入Python爬虫领域,今天尝试一下爬取链家的二手房,之前已经爬取了房天下的了,看看链家有什么不同,马上开始. 一.分析观察爬取网站结构 这里以广州链家二手房为例:http:/ ...
- Scrapy实战篇(一)之爬取链家网成交房源数据(上)
今天,我们就以链家网南京地区为例,来学习爬取链家网的成交房源数据. 这里推荐使用火狐浏览器,并且安装firebug和firepath两款插件,你会发现,这两款插件会给我们后续的数据提取带来很大的方便. ...
- python爬虫:爬取链家深圳全部二手房的详细信息
1.问题描述: 爬取链家深圳全部二手房的详细信息,并将爬取的数据存储到CSV文件中 2.思路分析: (1)目标网址:https://sz.lianjia.com/ershoufang/ (2)代码结构 ...
随机推荐
- C# 生成时间戳
编写网络程序中难免用到一些时间戳. 早前不知道哪里复制过一个代码,如下: public static string GetTimeStamp() { TimeSpan ts = DateTime.Ut ...
- 【mysql】mysql表分区、索引的性能测试
概述 mysql分区表概述:google搜索一下: RANGE COLUMNS partitioning 主要测试mysql分区表的性能: load 500w 条记录:大约在10min左右: batc ...
- Ubuntu 14.10 下Eclipse安装Hadoop插件
准备环境 1 安装好了Hadoop,之前安装了Hadoop 2.5.0,安装参考http://www.cnblogs.com/liuchangchun/p/4097286.html 2 安装Eclip ...
- appium 启动了2个端口,但是只有一台机器在跑的 问题解决 (还没试,记录在此)
appium启动了2个,端口分别设置为了4723 4725, 在测试类中也分别指定了设备和端口,用device来指定.然而每次都是运行一个设备. 后来添加了udid这个来指定才发现可以.deviceN ...
- Java学习——Applet写字符串(调字体)
import java.awt.*; import java.applet.Applet; public class GUI2 extends Applet{ public void paint(Gr ...
- jquery tr:even,tr:eq(),tr:nth-child()区别
jquery里面是不是搞不清楚,tr的选择器? $("tr:even"),$("tr:eq(2)"),$("tr:eq(3)"),$(&qu ...
- Java-Runoob-高级教程-实例-数组:16. Java 实例 - 数组并集
ylbtech-Java-Runoob-高级教程-实例-数组:16. Java 实例 - 数组并集 1.返回顶部 1. Java 实例 - 数组并集 Java 实例 以下实例演示了如何使用 unio ...
- 学习笔记之TensorFlow
TensorFlow https://www.tensorflow.org/ An open source machine learning framework for everyone Tensor ...
- Charles问题
1.内容显示乱码 1.1.使用Charles抓包,text显示乱码,note提示如下 SSL Proxying not enabled for this host: enable in Proxy S ...
- hierarchical_mutex函数问题(C++ Concurrent in Action)
C++ Concurrent in Action(英文版)书上(No.52-No.53)写的hierarchical_mutex函数,只适合结合std::lock_guard使用,直接使用如果不考虑顺 ...