kmeans理解
最近看到Andrew Ng的一篇论文,文中用到了Kmeans和DL结合的思想,突然发现自己对ML最基本的聚类算法都不清楚,于是着重的看了下Kmeans,并在网上找了程序跑了下。
kmeans是unsupervised learning最基本的一个聚类算法,我们可以用它来学习无标签的特征,其基本思想如下:
首先给出原始数据{x1,x2,...,xn},这些数据没有被标记的。
初始化k个随机数据u1,u2,...,uk,每一个ui都是一个聚类中心,k就是分为k类,这些xn和uk都是向量。
根据下面两个公式迭代就能求出最终所有的聚类中心u。
formula 1:
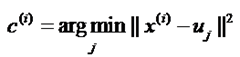
其中xi是第i个data,uj是第j(1~k)的聚类中心,这个公式的意思就是求出每一个data到k个聚类中心的距离,并求出最小距离,那么数据xi就可以归到这一类。
formula 2:
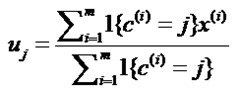
这个公式的目的是求出新的聚类中心,由于之前已经求出来每一个data到每一类的聚类中心uj,那么可以在每一类总求出其新的聚类中心(用这一类每一个data到中心的距离之和除以总的data),分别对k类同样的处理,这样我们就得到了k个新的聚类中心。
反复迭代公式一和公式二,知道聚类中心不怎么改变为止。
我们利用3维数据进行kmeans,代码如下:
run_means.m
1: %%用来kmeans聚类的一个小代码
2:
3: clear all;
4: close all;
5: clc;
6:
7: %第一类数据
8: mu1=[0 0 0]; %均值
9: S1=[0.3 0 0;0 0.35 0;0 0 0.3]; %协方差
10: data1=mvnrnd(mu1,S1,100); %产生高斯分布数据
11:
12: %%第二类数据
13: mu2=[1.25 1.25 1.25];
14: S2=[0.3 0 0;0 0.35 0;0 0 0.3];
15: data2=mvnrnd(mu2,S2,100);
16:
17: %第三个类数据
18: mu3=[-1.25 1.25 -1.25];
19: S3=[0.3 0 0;0 0.35 0;0 0 0.3];
20: data3=mvnrnd(mu3,S3,100);
21:
22: %显示数据
23: plot3(data1(:,1),data1(:,2),data1(:,3),'+');
24: hold on;
25: plot3(data2(:,1),data2(:,2),data2(:,3),'r+');
26: plot3(data3(:,1),data3(:,2),data3(:,3),'g+');
27: grid on;
28:
29: %三类数据合成一个不带标号的数据类
30: data=[data1;data2;data3]; %这里的data是不带标号的
31:
32: %k-means聚类
33: [u re]=KMeans(data,3); %最后产生带标号的数据,标号在所有数据的最后,意思就是数据再加一维度
34: [m n]=size(re);
35:
36: %最后显示聚类后的数据
37: figure;
38: hold on;
39: for i=1:m
40: if re(i,4)==1
41: plot3(re(i,1),re(i,2),re(i,3),'ro');
42: elseif re(i,4)==2
43: plot3(re(i,1),re(i,2),re(i,3),'go');
44: else
45: plot3(re(i,1),re(i,2),re(i,3),'bo');
46: end
47: end
48: grid on;
KMeans.m
1: %N是数据一共分多少类
2: %data是输入的不带分类标号的数据
3: %u是每一类的中心
4: %re是返回的带分类标号的数据
5: function [u re]=KMeans(data,N)
6: [m n]=size(data); %m是数据个数,n是数据维数
7: ma=zeros(n); %每一维最大的数
8: mi=zeros(n); %每一维最小的数
9: u=zeros(N,n); %随机初始化,最终迭代到每一类的中心位置
10: for i=1:n
11: ma(i)=max(data(:,i)); %每一维最大的数
12: mi(i)=min(data(:,i)); %每一维最小的数
13: for j=1:N
14: u(j,i)=ma(i)+(mi(i)-ma(i))*rand(); %随机初始化,不过还是在每一维[min max]中初始化好些
15: end
16: end
17:
18: while 1
19: pre_u=u; %上一次求得的中心位置
20: for i=1:N
21: tmp{i}=[]; % 公式一中的x(i)-uj,为公式一实现做准备
22: for j=1:m
23: tmp{i}=[tmp{i};data(j,:)-u(i,:)];
24: end
25: end
26:
27: quan=zeros(m,N);
28: for i=1:m %公式一的实现
29: c=[]; %c 是到每类的距离
30: for j=1:N
31: c=[c norm(tmp{j}(i,:))];
32: end
33: [junk index]=min(c);
34: quan(i,index)=norm(tmp{index}(i,:));
35: end
36:
37: for i=1:N %公式二的实现
38: for j=1:n
39: u(i,j)=sum(quan(:,i).*data(:,j))/sum(quan(:,i));
40: end
41: end
42:
43: if norm(pre_u-u)<0.1 %不断迭代直到位置不再变化
44: break;
45: end
46: end
47:
48: re=[];
49: for i=1:m
50: tmp=[];
51: for j=1:N
52: tmp=[tmp norm(data(i,:)-u(j,:))];
53: end
54: [junk index]=min(tmp);
55: re=[re;data(i,:) index];
56: end
57:
58: end
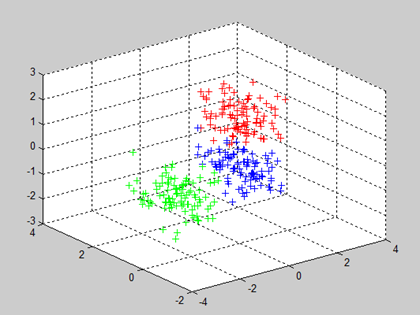
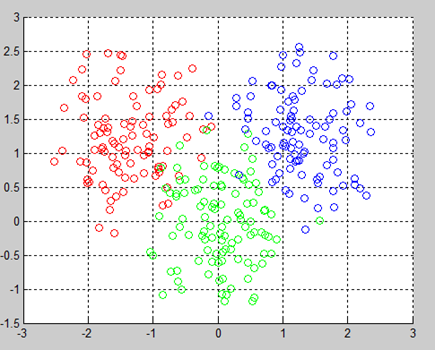
原始数据如下所示,分为三类:
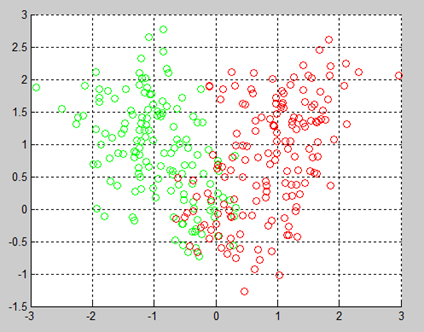
当k取2时,聚成2类:
当k取3时,聚成3类:
kmeans理解的更多相关文章
- weighted Kernel k-means 加权核k均值算法理解及其实现(一)
那就从k-means开始吧 对于机器学习的新手小白来说,k-means算法应该都会接触到吧.传统的k-means算法是一个硬聚类(因为要指定k这个参数啦)算法.这里利用百度的解释 它是数据点到原型的某 ...
- [数据挖掘] - 聚类算法:K-means算法理解及SparkCore实现
聚类算法是机器学习中的一大重要算法,也是我们掌握机器学习的必须算法,下面对聚类算法中的K-means算法做一个简单的描述: 一.概述 K-means算法属于聚类算法中的直接聚类算法.给定一个对象(或记 ...
- kmeans算法理解及代码实现
github:kmeans代码实现1.kmeans代码实现2(包含二分k-means) 本文算法均使用python3实现 1 聚类算法 对于"监督学习"(supervised ...
- 数据挖掘之KMeans算法应用与简单理解
一.背景 煤矿地磅产生了一系列数据: 我想从这些数据中,取出最能反映当前车辆重量的数据(有很多数据是车辆上磅过程中产生的数据).我于是想到了聚类算法KMeans,该算法思想比较简单. 二.算法步骤 1 ...
- 一维数组的 K-Means 聚类算法理解
刚看了这个算法,理解如下,放在这里,备忘,如有错误的地方,请指出,谢谢 需要做聚类的数组我们称之为[源数组]需要一个分组个数K变量来标记需要分多少个组,这个数组我们称之为[聚类中心数组]及一个缓存临时 ...
- 菜鸟之路——机器学习之Kmeans聚类个人理解及Python实现
一些概念 相关系数:衡量两组数据相关性 决定系数:(R2值)大概意思就是这个回归方程能解释百分之多少的真实值. Kmeans聚类大致就是选择K个中心点.不断遍历更新中心点的位置.离哪个中心点近就属于哪 ...
- 当我们在谈论kmeans(1)
本稿为初稿,后续可能还会修改:如果转载,请务必保留源地址,非常感谢! 博客园:http://www.cnblogs.com/data-miner/ 简书:建设中... 知乎:建设中... 当我们在谈论 ...
- 当我们在谈论kmeans(2)
本稿为初稿,后续可能还会修改:如果转载,请务必保留源地址,非常感谢! 博客园:http://www.cnblogs.com/data-miner/ 其他:建设中- 当我们在谈论kmeans(2 ...
- 【原创】数据挖掘案例——ReliefF和K-means算法的医学应用
数据挖掘方法的提出,让人们有能力最终认识数据的真正价值,即蕴藏在数据中的信息和知识.数据挖掘 (DataMiriing),指的是从大型数据库或数据仓库中提取人们感兴趣的知识,这些知识是隐含的.事先未知 ...
随机推荐
- 版权控制之zend guard 6.0使用教程
zend guard6.0使用教程.doc 一.准备工具 1. ZendGuard-6_0_0 下载地址:http://www.zend.com/en/products/guard/downloads ...
- JPG各种输入框样式
输入框景背景透明:<input style="background:transparent;border:1px solid #ffffff"> 鼠标划过输入框,输入框 ...
- mysql-5.5.46源码编译安装
1.安装准备 cat /etc/redhat-release uname -r yum install ncurses-devel cmake automake autoconf make gcc g ...
- pipe/popen/fifo
pipe(管道) 专用于父子进程通信, 函数原型 int pipe(int fd[2]) fd[0]表示输入, fd[1]表示输出 如果父子进程要双向通信, 可以通过类似信号的功能进行控制, 也可以简 ...
- 鼠标驱动之-sys节点-input子系统
首先需要了解sys节点和linux驱动编程的知识,在linux内核<linux/>下有着对应的实现.本例实现创建sys节点,外围程序通过input子系统控制鼠标位置. 第一步编写驱动代码, ...
- constructor(构造器)
当我们创建一个类的时候,如果不自定义构造器,则系统会自动创建一个默认的构造器,也是一个无参构造器用于初始化. 当我们在类的里面创建了自己的构造器,则系统将不会创建默认的构造器,由于需求条件不同,构造器 ...
- Configuring My Site in SharePoint 2010
Configuring the User Profile Service in SharePoint 2010 http://sharepointgeorge.com/2010/configuring ...
- C# Windows - 菜单栏和工具栏
除了MenuStrip控件之外,还有许多控件可用于填充菜单.3个常见的控件是ToolStripMenuItem,ToolStripDropDown,和ToolStripSeparator.这些控件表示 ...
- Configure xterm Fonts and Colors for Your Eyeball
https://wiki.mpich.org/mpich/index.php/Configure_xterm_Fonts_and_Colors_for_Your_Eyeball Screenshot ...
- 20145120 《Java程序设计》第1周学习总结
20145120 <Java程序设计>第1周学习总结 教材学习内容总结 刚刚开始学习java,感觉还十分陌生,在第一周的学习中,我知道了java的历史,JVM.JRE和JDK是什么等各种知 ...