Scrapy爬取Ajax(异步加载)网页实例——简书付费连载
这两天学习了Scrapy爬虫框架的基本使用,练习的例子爬取的都是传统的直接加载完网页的内容,就想试试爬取用Ajax技术加载的网页。
这里以简书里的优选连载网页为例分享一下我的爬取过程。
网址为:
https://www.jianshu.com/mobile/books?category_id=284
一、分析网页
进入之后,鼠标下拉发现内容会不断更新,网址信息也没有发生变化,于是就可以判断这个网页使用了异步加载技术。
 f
f
首先明确爬取的内容,本次我爬取的是作品名称、照片、作者、阅读量。然后将照片下载存储在文件夹中,然后将全部内容生成csv文件夹保存。
查看网页源代码发现代码里只有已加载的作品的内容,编写爬虫代码发现爬取不到收录的信息。
进入Network选项,勾选XHR选项,通过下滑网页发现Network选项卡会加载文件,如下图:
注:这里我用的是火狐浏览器

点击其中一个加载文件,可以在消息头看到请求网址:
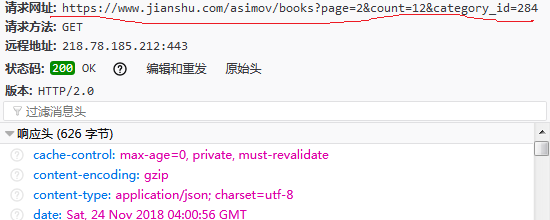
继续下滑,发现Headers部分请求的URL只是page后面的数字在改变,通过改变数字,我们就能在后面调用回调函数爬取多个网页了。
二、Scrapy爬取
1.在命令提示符输入:
cd Desktop #进入桌面
scrapy startproject jian #生成名为jian的Scrapy文件夹 cd jian
scrapy genspider lianzai jianshu.com #爬虫名为lianzai
这里我用的是pycharm,打开文件夹。

2.在items.py定义爬虫字段
class JianItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
book_name=scrapy.Field()
img=scrapy.Field()
author=scrapy.Field()
readers=scrapy.Field()
pass
3.在lianzai.py编写爬虫代码,爬取数据
# -*- coding: utf-8 -*-
import scrapy
from jian.items import JianItem
import json
import requests class LianzaiSpider(scrapy.Spider):
name = 'lianzai'
allowed_domains = ['jianshu.com']
start_urls = ['https://www.jianshu.com/asimov/books?page=1&count=12&category_id=284'] #第一页的url
def parse(self, response):
data=json.loads(response.body) #str转为json对象
try:
for i in range(0, 12):
item = JianItem()
img=data['books'][i]['image_url']
book_name=data['books'][i]['name']
author=data['books'][i]['user']['nickname']
readers=data['books'][i]['views_count'] item['img']=img
item['book_name']=book_name
item['author']=author
item['readers']=readers
yield item #返回数据
except IndexError:
pass
urls=['https://www.jianshu.com/asimov/books?page={}&count=12&category_id=284'.format(str(i))for i in range(2, 11)] #
for url in urls:
yield scrapy.Request(url,callback=self.parse) #回调函数
这里特别要注意的是要爬取内容的所在位置。
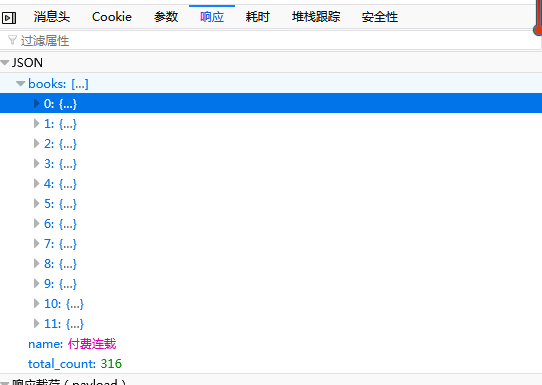
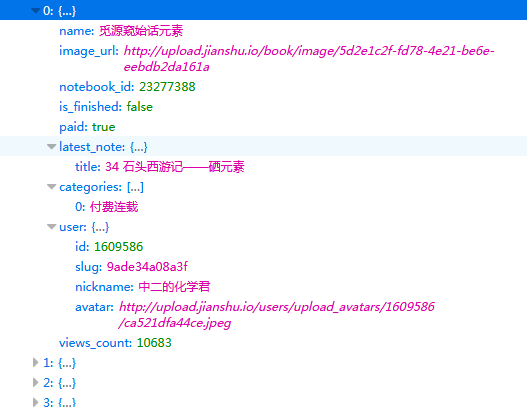
上图中左图可以看出爬取的内容的位置在response里的['books']里面,且一个网页有12个作品,因此上面循环出为(0,12)。
打开后如上右图,可以看到我们要爬取的作品名、图片地址、作者、阅读量都在里面,爬取就相对容易了。
4.在setting.py设置爬虫配置
USER_AGENT='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36' #请求头
DOWNLOAD_DELAY=0.5 #延时0.5
FEED_URI='file:C:/Users/lenovo/Desktop/jianshulianzai.csv' #在桌面生成CSV文件
FEED_FORMAT='csv' #存入
ITEM_PIPELINES={'jian.pipelines.JianPipeline':300}
5.在pipelines.py处理照片数据
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
import urllib.request class JianPipeline(object):
def process_item(self, item, spider):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36'
}
try:
if item['img'] != None:
req=urllib.request.Request(url=item['img'],headers=headers)
res=urllib.request.urlopen(req)
file_name = os.path.join(r'C:\Users\lenovo\Desktop\my_pic', item['book_name'] + '.jpg')
with open(file_name,'wb')as f:
f.write(res.read())
except urllib.request.URLError:
pass
return item
6.全部保存后,在命令行终端输入:
scrapy crawl lianzai
就将结果爬取下来并保存啦。
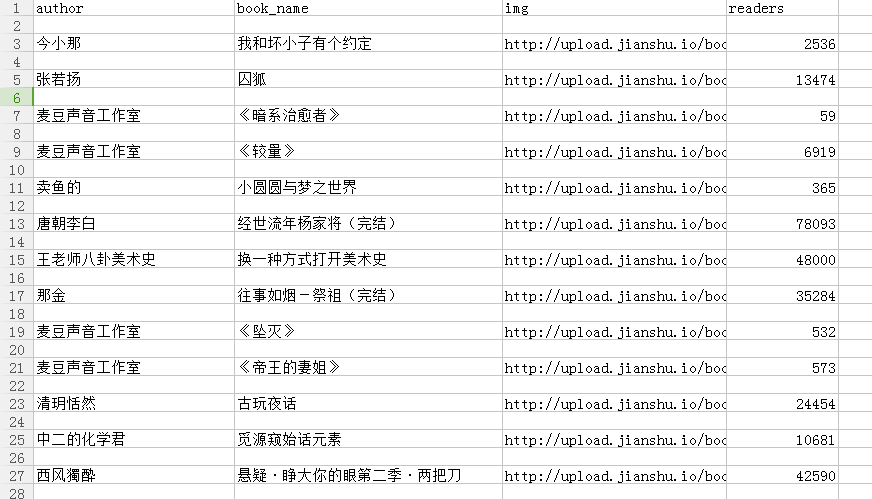
三、结果
.csv文件的内容:
下载的照片:

初入爬虫,还有很多不足需要改正,还有很多知识需要学习,希望有疑问或建议的朋友多多指正或留言。谢谢。
Scrapy爬取Ajax(异步加载)网页实例——简书付费连载的更多相关文章
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- 爬虫——爬取Ajax动态加载网页
常见的反爬机制及处理方式 1.Headers反爬虫 :Cookie.Referer.User-Agent 解决方案: 通过F12获取headers,传给requests.get()方法 2.IP限制 ...
- Python网络爬虫_爬取Ajax动态加载和翻页时url不变的网页
1 . 什么是 AJAX ? AJAX = 异步 JavaScript 和 XML. AJAX 是一种用于创建快速动态网页的技术. 通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新 ...
- scrapy项目5:爬取ajax形式加载的数据,并用ImagePipeline保存图片
1.目标分析: 我们想要获取的数据为如下图: 1).每本书的名称 2).每本书的价格 3).每本书的简介 2.网页分析: 网站url:http://e.dangdang.com/list-WY1-dd ...
- htmlunit爬取js异步加载后的页面
直接上代码: 一. index.html 调用后台请求获取content中的内容. <html> <head> <script type="text/javas ...
- 淘宝购物车页面 智能搜索框Ajax异步加载数据
如果有朋友对本篇文章的一些知识点不了解的话,可以先阅读此篇文章.在这篇文章中,我大概介绍了一下构建淘宝购物车页面需要的基础知识. 这篇文章主要探讨的是智能搜索框Ajax异步加载数据.jQuery的社区 ...
- jQuery的AJax异步加载
主要用到load()方法以及getScript()方法,具体以一个例子说明: 在现有html文件中加载一个拟好的片段,以及在片段加载完成之前阻止用户进一步操作的弹出框. 首先是现有html代码,无任何 ...
- ajax异步加载问题
使用ajax异步加载数据,在之后需要用到这个数据时,应该将之后的js一并写入ajax函数中,否则后面的js不能找到动态拼接的dom节点. 或者将其封装成方法,在ajax动态加载数据的最后调用该方法.
- Ajax 异步加载
AJAX (Asynchronous JavaScript and XML,异步的 JavaScript 和 XML).它不是新的编程语言,而是一种使用现有标准的新方法,是在不重新加载整个页面的情况下 ...
随机推荐
- python笔记:#001#python简介
认识 Python 人生苦短,我用 Python -- Life is short, you need Python 目标 Python 的起源 为什么要用 Python? Python 的特点 Py ...
- Unity5 assetbundle笔记
Assetbundle api试验----打包选项试验--------结论:BuildAssetBundleOptions说明:------------None: 把所有以来资源到到一个包里----- ...
- ArcGis SOE(server object extensions)之REST Template初体验
一.安装vs和arcgis server for .net(本例是vs2010.as 10),然后打开vs新建一个项目
- 用Maven实现一个protobuf的Java例子
注:试验环境在Mac Idea环境下 1. 介绍Protocol Buffers Protocal Buffers(简称protobuf)是谷歌的一项技术,用于结构化的数据序列化.反序列化,常用于RP ...
- GitHub学习笔记:本地操作
安装过程略,假设你已经注册好了Github, 已经有了一个准备好的程序.我们的一切工作都是基于Git Shell,与GUI客户端无关. 在使用前你先要配置好config中的几个内容,主要是你自己的个人 ...
- 浅谈面试中的OOD面向对象设计问题
转载自:http://baozitraining.org/blog/Object-oriented-design-question/ OO设计问题是电面或者onsite中常考的问题,尤其对以Java为 ...
- 判断NaN in JavaScript
[NaN 作用是用来表示一个值不是数字] NaN在JavaScript中行为很怪异,是因为那NaN和任何值都不相等(包括它自己). NaN === NaN; // false因为 ...
- jq slideToggle()坑
jQuery slideToggle() 方法 jQuery slideToggle() 方法可以在 slideDown() 与 slideUp() 方法之间进行切换. 如果元素向下滑动,则 slid ...
- SSM-SpringMVC-10:SpringMVC中PropertiesMethodNameResolver属性方法名称解析器
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 上次的以继承MultiActionController可以实现一个处理器中多个处理方法,但是局限出来了,他们的 ...
- SSM-MyBatis-06:Mybatis中openSession到底做了什么
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 1.找SqlSesionFactory实现类 Ctrl+H:DefaultSqlSessionFactory: ...