Dom4J配合XPath解析schema约束的xml配置文件问题
如果一个xml文件没有引入约束,或者引入的是DTD约束时,那么使用dom4j和xpath是可以正常解析的,不引入约束的情况本文不再展示。
引入DTD约束的情况
- mybook.dtd:
<?xml version="1.0" encoding="UTF-8" ?>
<!ELEMENT books (book+)>
<!ELEMENT book (name|author|price)+>
<!ELEMENT name (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT price (#PCDATA)>
<!ATTLIST book id ID #REQUIRED publish CDATA #IMPLIED>
- book.xml:
<?xml version="1.0" encoding="UTF-8 ?>
<!DOCTYPE books SYSTEM "mybook.dtd">
<books>
<book id="_001">
<name>西游记</name>
</book>
<book id="_002">
<name>三国演义</name>
</book>
<book id="_003">
<name>水浒传</name>
</book>
<book id="_004">
<name>红楼梦</name>
</book>
</books>
测试类:
public class DemoBook {
public static void main(String[] args) throws DocumentException {
SAXReader reader = new SAXReader();
Document document = reader.read(DemoBook.class.getResourceAsStream("book.xml"));
List<Node> nodes = document.selectNodes("//name");
for (Node node : nodes) {
Element element = (Element) node;
System.out.print(element.getText()+" ");
}
}
}
//输出结果:西游记 三国演义 水浒传 红楼梦
可见,引入了DTD约束的xml是可以通过dom4j和xpath表达式正常解析的.而引入Schema约束的时候呢?
引入Schema约束的情况
- mybook.xsd:
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.mytest.com/book"
elementFormDefault="qualified">
<element name="books">
<complexType>
<sequence maxOccurs="unbounded">
<element name="book">
<complexType>
<choice maxOccurs="unbounded">
<element name="name" type="string"></element>
<element name="author" type="string"></element>
</choice>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
- book.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<books
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.mytest.com/book"
xsi:schemaLocation="http://www.mytest.com/book /mybook.xsd"
>
<book>
<name>西游记</name>
</book>
<book>
<name>三国演义</name>
</book>
<book>
<name>水浒传</name>
</book>
<book>
<name>红楼梦</name>
</book>
</books>
测试类:
public class DemoBook {
public static void main(String[] args) throws DocumentException {
SAXReader reader = new SAXReader();
Document document = reader.read(DemoBook.class.getResourceAsStream("book.xml"));
List<Node> nodes = document.selectNodes("//name");
for (Node node : nodes) {
Element element = (Element) node;
System.out.println(element.getText());
}
}
}
结果为:
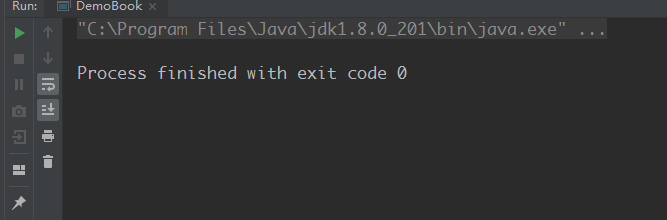
我们会发现,同样的代码,运行在引入了Schema约束的xml文件上虽然正常运行了,但是并没有达到我们想要的结果,document对象获取到的nodes集合是个空集合[] 。
产生问题的原因
当XPath表达式中没有前缀时,查询的元素命名空间也应该是默认值,否则是查询不到结果的。引入了Schema约束的xml文件使用了命名空间,此时查询元素的命名空间不再是默认值了,所以此时的结果是个空集合。
解决方案:
此时如果想要正确的解析结果,必须设置命名空间后再对文档进行解析。
修改后的测试类:
public class DemoBook {
public static void main(String[] args) throws DocumentException {
SAXReader reader = new SAXReader();
//声明一个map集合保存命名空间
Map<String,String > map = new HashMap<>();
//给命名空间取别名
map.put("myNameSpace","http://www.mytest.com/book");
//设置命名空间
reader.getDocumentFactory().setXPathNamespaceURIs(map);
//读取文档
Document document = reader.read(Demo1.class.getResourceAsStream("book.xml"));
List<Node> nodes = document.selectNodes("//myNameSpace:name");
for (Node node : nodes) {
Element element = (Element)node;
System.out.println(element.getText());
}
}
}
运行结果:
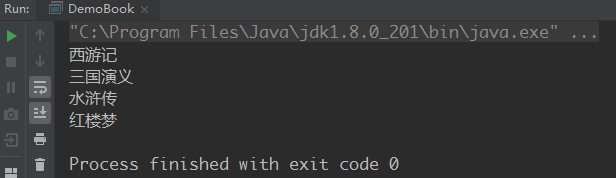
Perfect~
Dom4J配合XPath解析schema约束的xml配置文件问题的更多相关文章
- 简单用DOM4J结合XPATH解析XML
由于DOM4J在解析XML时只能一层一层解析,所以当XML文件层数过多时使用会很不方便,结合XPATH就可以直接获取到某个元素 使用dom4j支持xpath的操作的几种主要形式 第一种形式 ...
- java使用dom4j和XPath解析XML与.net 操作XML小结
最近研究java的dom4j包,使用 dom4j包来操作了xml 文件 包括三个文件:studentInfo.xml(待解析的xml文件), Dom4jReadExmple.java(解析的主要类), ...
- 使用Dom4j的xPath解析xml文件------xpath语法
官方语法地址:http//www.w3school.com.cn/xpath/index.asp xpath使用路径表达式来选取xml文档中的节点或节点集.节点是通过沿着路径(path)或者步(ste ...
- 利用XPath解析带有xmlns的XML文件
在.net中,编写读取xml 的程序中提示"未将对象引用设置到对象的实例",当时一看觉得有点奇怪.为什么在读取xml数据的时候也要实例化一个对象.google了才知道,xml文件中 ...
- JAVA通过XPath解析XML性能比较(原创)
(转载请标明原文地址) 最近在做一个小项目,使用到XML文件解析技术,通过对该技术的了解和使用,总结了以下内容. 1 XML文件解析的4种方法 通常解析XML文件有四种经典的方法.基本的解析方式有两种 ...
- dom4j解析器 基于dom4j的xpath技术 简单工厂设计模式 分层结构设计思想 SAX解析器 DOM编程
*1 dom4j解析器 1)CRUD的含义:CreateReadUpdateDelete增删查改 2)XML解析器有二类,分别是DOM和SAX(simple Api for xml). ...
- JAVA通过XPath解析XML性能比较
转自[http://www.cnblogs.com/mouse-coder/p/3451243.html] 最近在做一个小项目,使用到XML文件解析技术,通过对该技术的了解和使用,总结了以下内容. 1 ...
- Schema约束
Schema约束(*xml中如何引入schema约束)(看懂Schema:能根据Schema写出XML文档来:)1.Schema约束文档本身就是一个XML文档.2.Schema对名称空间支持很好3.S ...
- XML概念定义以及如何定义xml文件编写约束条件java解析xml DTD XML Schema JAXP java xml解析 dom4j 解析 xpath dom sax
本文主要涉及:xml概念描述,xml的约束文件,dtd,xsd文件的定义使用,如何在xml中引用xsd文件,如何使用java解析xml,解析xml方式dom sax,dom4j解析xml文件 XML来 ...
随机推荐
- How to untar a TAR file using Apache Commons
import org.apache.commons.compress.archivers.tar.TarArchiveEntry; import org.apache.commons.compress ...
- React Native系列(6) - 编译安卓私有React-Native代码
为何要自己编译React Native安卓私有代码 我们在开发中遇到一个HTTP2的问题,React Native安卓客户端在和HTTP2支持的服务器通讯的过程中会有crash,见 React-Nat ...
- 5.两分钟让你明白app后端有啥用
app后端,也称为app后台,称呼不一样,但指的是同一个东西. 我一直都以app后端有啥用这个问题不用解释.但在网络上,有准备进行app创业的网友(是从传统行业过来的)问过这个问题,我这里就以app后 ...
- [python]多线程模块thread与threading
Python通过两个标准库(thread, threading)提供了对多线程的支持 thread模块 import time import thread def runner(arg): for i ...
- 一次完整的HTTP网络请求过程详解
0. 前言 从我们在浏览器的地址栏输入http://blog.csdn.net/seu_calvin后回车,到我们看到该博客的主页,这中间经历了什么呢?简单地回答这个问题,大概是经历了域名解析.TC ...
- timeCache.go
package blog4go import ( "sync" "time" ) const ( // PrefixTimeFormat 时间格式前缀 Pre ...
- laravel 分页和共多少条 加参数的分页链接
<div class="pagers "> <span class="fs pager">共 {{$trades->total() ...
- Django 项目搭建(ubuntu系统)
1 环境搭建 sudo apt-get install python3-pip 安装pip3 sudo pip3 install virtualenv 安装虚拟环境,这里展示virtualenv vi ...
- 谈谈.NET架构师面试及如何设计面试题
上星期:应老东家的要求,帮其面试.NET架构师. 于是:老东家进行了一星期的简历收集: 终于:在一堆简历里,精挑细选了四个: 约了:周末上午下午各两个. 面试者年龄:在30-35岁左右,差不多10年. ...
- Mock接口平台Moco学习
Mock就是模拟接口的.本文学习Mock的 Moco开源框架. Moco源码和jar下载地址: git jar 下载moco-runner-xxxx-standalone.jar moco的启动及 ...