使用Python3爬虫抓取网页来下载小说
很多时候想看小说但是在网页上找不到资源,即使找到了资源也没有提供下载,小说当然是下载下来用手机看才爽快啦!
于是程序员的思维出来了,不能下载我就直接用爬虫把各个章节爬下来,存入一个txt文件中,这样,一部小说就爬下来啦。
这一次我爬的书为《黑客》,一本网络小说,相信很多人都看过吧,看看他的代码吧。
代码见如下:
import re
import urllib.request
import time #
root = 'http://www.biquge.com.tw/3_3542/'
# 伪造浏览器
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) ' \
'AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/62.0.3202.62 Safari/537.36'} req = urllib.request.Request(url=root, headers=headers) with urllib.request.urlopen(req, timeout=1) as response:
# 大部分的涉及小说的网页都有charset='gbk',所以使用gbk编码
htmls = response.read().decode('gbk') # 匹配所有目录<a href="/3_3542/2020025.html">HK002 上天给了一个做好人的机会</a>
dir_req = re.compile(r'<a href="/3_3542/(\d+?.html)">')
dirs = dir_req.findall(htmls) # 创建文件流,将各个章节读入内存
with open('黑客.txt', 'w') as f:
for dir in dirs:
# 组合链接地址,即各个章节的地址
url = root + dir
# 有的时候访问某个网页会一直得不到响应,程序就会卡到那里,我让他0.6秒后自动超时而抛出异常
while True:
try:
request = urllib.request.Request(url=url, headers=headers)
with urllib.request.urlopen(request, timeout=0.6) as response:
html = response.read().decode('gbk')
break
except:
# 对于抓取到的异常,我让程序停止1.1秒,再循环重新访问这个链接,一旦访问成功,退出循环
time.sleep(1.1) # 匹配文章标题
title_req = re.compile(r'<h1>(.+?)</h1>')
# 匹配文章内容,内容中有换行,所以使flags=re.S
content_req = re.compile(r'<div id="content">(.+?)</div>',re.S,)
# 拿到标题
title = title_req.findall(html)[0]
# 拿到内容
content_test = content_req.findall(html)[0]
# 对内容中的html元素杂质进行替换
strc = content_test.replace(' ', ' ')
content = strc.replace('<br />', '\n')
print('抓取章节>' + title)
f.write(title + '\n')
f.write(content + '\n\n')
就这样,一本小说就下载下来啦!!!
运行情况见图:
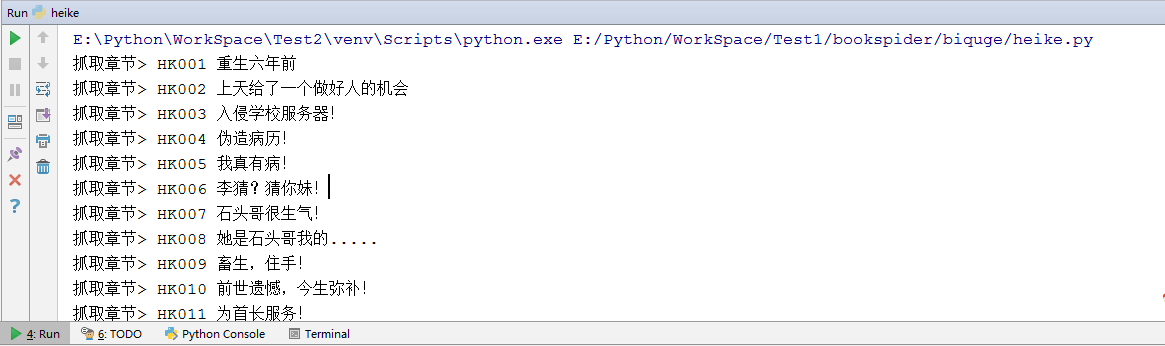
有的时候服务器会因为大量访问而认为你是个机器人就封了你的IP,可以加个随机数,让程序随机停止不同的时间。
如果下载太慢,可以使用多线程,一起下载多个章节
使用Python3爬虫抓取网页来下载小说的更多相关文章
- 关于Python3爬虫抓取网页Unicode
import urllib.requestresponse = urllib.request.urlopen('http://www.baidu.com')html = response.read() ...
- Python3简单爬虫抓取网页图片
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到 ...
- PHP利用Curl实现多线程抓取网页和下载文件
PHP 利用 Curl 可以完成各种传送文件操作,比如模拟浏览器发送GET,POST请求等等,然而因为php语言本身不支持多线程,所以开发爬虫程序效率并不高,一般采集 数据可以利用 PHPquery ...
- 笔趣看小说Python3爬虫抓取
笔趣看小说Python3爬虫抓取 获取HTML信息 解析HTML信息 整合代码 获取HTML信息 # -*- coding:UTF-8 -*- import requests if __name__ ...
- python3爬虫爬取网页思路及常见问题(原创)
学习爬虫有一段时间了,对遇到的一些问题进行一下总结. 爬虫流程可大致分为:请求网页(request),获取响应(response),解析(parse),保存(save). 下面分别说下这几个过程中可以 ...
- 怎么用Python写爬虫抓取网页数据
机器学习首先面临的一个问题就是准备数据,数据的来源大概有这么几种:公司积累数据,购买,交换,政府机构及企业公开的数据,通过爬虫从网上抓取.本篇介绍怎么写一个爬虫从网上抓取公开的数据. 很多语言都可以写 ...
- linux中使用wget模拟爬虫抓取网页
如何在linux上或者是mac上简单使用爬虫或者是网页下载工具呢,常规的我们肯定是要去下载一个软件下来使用啦,可怜的这两个系统总是找不到相应的工具,这时wget出来帮助你啦!!!wget本身是拿来下载 ...
- C# 使用 Abot 实现 爬虫 抓取网页信息 源码下载
下载地址 ** dome **
- win7下用python3.3抓取网上图片并下载到本地
这篇文章是看了网上有人写了之后,才去试试看的,但是因为我用的是python3.3,与python2.x有些不同,所以就写了下来,以供参考. get_webJpg.py #coding=utf-8 im ...
随机推荐
- VMware Workstation 14 Pro永久激活密钥
1. ZC3WK-AFXEK-488JP-A7MQX-XL8YF 2. AC5XK-0ZD4H-088HP-9NQZV-ZG2R4 3. ZY5H0-D3Y8K-M89EZ-AYPEG-MYUA8 4 ...
- k60模块
lptmr_time_start_ms(); //开始计时 DELAY_MS(); //延时一段时间(由于语句执行需要时间,因而实际的延时时间会更长一些) timevar = lptmr_time_g ...
- Learn HTML5 in 5 Minutes!
There's no question, HTML5 is a hot topic for developers. If you need a crash course to quickly unde ...
- Mac上使用jenkins+ant执行第一个程序
本文旨在让同学们明白如何让jenkis在mac笔记本上运行,以模拟实际工作中在linux上搭建jenkins服务平台首先按照笔者的习惯先说一下如何安装jenkis和tomcat,先安装tomcat,在 ...
- 筛法求素数Java
输出:一个集合S,表示1~n以内所有的素数 import java.util.Scanner; public class 筛法求素数 { public static void main(String[ ...
- kubernetes实践之运行aspnetcore webapi微服务
1.预备工作 unbuntu 16.04 and above docker kubernetes 集群 2.使用vs2017创建一个web api应用程序,并打包镜像到本地. 3.推送本地镜像到doc ...
- 部署wcf出现的问题与解决方法
我将本机作为服务器开发时,没出什么问题,将wcf服务端寄缩到另一台电脑上时,出现了一些问题,这里总结下: 1.wcf服务器和另一个网站应用出问题 服务器的iis上有一个网站应用,当我将wcf服务寄缩到 ...
- python爬微信公众号前10篇历史文章(4)-正则表达式RegularExpressionPattern
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串.将匹配的子串替换或者从某个串中取出符合某个条件的子串等. Pytho ...
- linux常用命令汇总(更新中...)
文本查看与编辑 1.文本编辑命令 vi/vim 2.查看文件内容命令 命令 说明 命令格式 参数 cat 将一个文件的内容连续输出在屏幕上 cat [-option] 文件名 -n:将行号一起显示在 ...
- 掌握这些回答技术面试题的诀窍,让你offer拿到手软。
三.四月份,春回大地,万物复苏(请自带赵忠祥老师的BGM),又到了不少同学的跳槽时节. 最近一段时间团队也在招人,这期间筛选了不少简历,面试了一些候选人.这里谈谈我自己的对「怎样回答面试题」的理解. ...