异常检测算法:Isolation Forest
iForest (Isolation Forest)是由Liu et al. [1] 提出来的基于二叉树的ensemble异常检测算法,具有效果好、训练快(线性复杂度)等特点。
1. 前言
iForest为聚类算法,不需要标记数据训练。首先给出几个定义:
- 划分(partition)指样本空间一分为二,相当于决策树中节点分裂;
- isolation指将某个样本点与其他样本点区分开。
iForest的基本思想非常简单:完成异常点的isolation所需的划分数大于正常样本点(非异常)。如下图所示:
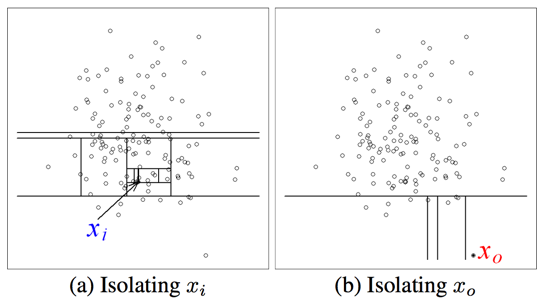
\(x_i\)样本点的isolation需要大概12次划分,而异常点\(x_0\)指需要4次左右。因此,我们可以根据划分次数来区分是否为异常点。但是,如何建模呢?我们容易想到:划分对应于决策树中节点分裂,那么划分次数即为从决策树的根节点到叶子节点所经历的边数,称之为路径长度(path length)。假设样本集合共有\(n\)个样本点,对于二叉查找树(Binary Search Tree, BST),则查找失败的平均路径长度为
\[
c(n) = 2H(n-1) -(2(n-1)/n)
\]
其中,\(H(i)\)为harmonic number,可估计为\(\ln (i) + 0.5772156649\)。那么,可建模anomaly score:
\[
s(x,n) = 2^{-\frac{E(h(x))}{c(n)}}
\]
其中,\(h(x)\)为样本点\(x\)的路径长度,\(E(h(x))\)为iForest的多棵树中样本点\(x\)的路径长度的期望。特别地,

当\(s\)值越高(接近于1),则表明该点越可能为异常点。若所有的样本点的\(s\)值都在0.5左右,则说明该样本集合没有异常点。
2. 详解
iForest采用二叉决策树来划分样本空间,每一次划分都是随机选取一个属性值来做,具体流程如下:

停止分裂条件:
- 树达到了最大高度;
- 落在孩子节点的样本数只有一个,或者所有样本点的值均相同;
为了避免错检(swamping)与漏检(masking),在训练每棵树的时候,为了更好地区分,不会拿全量样本,而会sub-sampling样本集合。iForest的训练流程如下:

sklearn给出了iForest与其他异常检测算法的比较。
3. 参考资料
[1] Liu, Fei Tony, Kai Ming Ting, and Zhi-Hua Zhou. "Isolation forest." Data Mining, 2008. ICDM'08. Eighth IEEE International Conference on. IEEE, 2008.
异常检测算法:Isolation Forest的更多相关文章
- 异常检测算法--Isolation Forest
南大周志华老师在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结. iTree 提到森林 ...
- Python机器学习笔记 异常点检测算法——Isolation Forest
Isolation,意为孤立/隔离,是名词,其动词为isolate,forest是森林,合起来就是“孤立森林”了,也有叫“独异森林”,好像并没有统一的中文叫法.可能大家都习惯用其英文的名字isolat ...
- [转]Python机器学习笔记 异常点检测算法——Isolation Forest
Isolation,意为孤立/隔离,是名词,其动词为isolate,forest是森林,合起来就是“孤立森林”了,也有叫“独异森林”,好像并没有统一的中文叫法.可能大家都习惯用其英文的名字isolat ...
- 【异常检测】Isolation forest 的spark 分布式实现
1.算法简介 算法的原始论文 http://cs.nju.edu.cn/zhouzh/zhouzh.files/publication/icdm08b.pdf .python的sklearn中已经实现 ...
- 异常检测算法Robust Random Cut Forest(RRCF)关键定理引理证明
摘要:RRCF是亚马逊发表的一篇异常检测算法,是对周志华孤立森林的改进.但是相比孤立森林,具有更为扎实的理论基础.文章的理论论证相对较为晦涩,且没给出详细的证明过程.本文不对该算法进行详尽的描述,仅对 ...
- 机器学习:异常检测算法Seasonal Hybrid ESD及R语言实现
Twritters的异常检测算法(Anomaly Detection)做的比较好,Seasonal Hybrid ESD算法是先用STL把序列分解,考察残差项.假定这一项符合正态分布,然后就可以用Ge ...
- 【机器学习】异常检测算法(I)
在给定的数据集,我们假设数据是正常的 ,现在需要知道新给的数据Xtest中不属于该组数据的几率p(X). 异常检测主要用来识别欺骗,例如通过之前的数据来识别新一次的数据是否存在异常,比如根据一个用户以 ...
- kaggle信用卡欺诈看异常检测算法——无监督的方法包括: 基于统计的技术,如BACON *离群检测 多变量异常值检测 基于聚类的技术;监督方法: 神经网络 SVM 逻辑回归
使用google翻译自:https://software.seek.intel.com/dealing-with-outliers 数据分析中的一项具有挑战性但非常重要的任务是处理异常值.我们通常将异 ...
- 如何开发一个异常检测系统:使用什么特征变量(features)来构建异常检测算法
如何构建与选择异常检测算法中的features 如果我的feature像图1所示的那样的正态分布图的话,我们可以很高兴地将它送入异常检测系统中去构建算法. 如果我的feature像图2那样不是正态分布 ...
随机推荐
- 2016广东工业大学新生杯决赛网络同步赛暨全国新生邀请赛 题解&源码
Problem A: pigofzhou的巧克力棒 Description 众所周知,pigofzhou有许多妹子.有一天,pigofzhou得到了一根巧克力棒,他想把这根巧克力棒分给他的妹子们.具体 ...
- BZOJ 3097: Hash Killer I【构造题,思维题】
3097: Hash Killer I Time Limit: 5 Sec Memory Limit: 128 MBSec Special JudgeSubmit: 963 Solved: 36 ...
- Quoit Design(最近点对+分治)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1007 Quoit Design Time Limit: 10000/5000 MS (Java/Oth ...
- Redis进阶实践之四Redis的基本数据类型
一.引言 今天正式开始了Redis的学习,如果要想学好Redis,必须先学好Redis的数据类型.Redis为什么会比以前的Memchaed等内存缓存软件使用的更频繁,适用范围更广呢?就是因为R ...
- c语言基础学习02
=============================================================================涉及到的知识点有:include有两种用法.{ ...
- c++(堆排序)
堆排序是另外一种常用的递归排序.因为堆排序有着优秀的排序性能,所以在软件设计中也经常使用.堆排序有着属于自己的特殊性质,和二叉平衡树基本是一致的.打一个比方说,处于大堆中的每一个数据都必须满足这样一个 ...
- ionic2 安装与cordova打包
1.安装: cnpm install -g cordova ionic ionic start name cd name cnpm install 2.环境配置: http://www.cnblo ...
- Android开发——BroadcastReceiver广播的使用
想要了解广播定义及相关原理的可以看下这一篇BroadcastReceiver史上最全面解析 简单地对广播进行分类吧,广播有两个角色,一个是广播发送者,另外一个是广播接收者 广播按照类型分为两种,一种是 ...
- 浅析const、let与var
以前无论声明变量还是常量,总是使用var一勺端,知道接触了es6之后,发现原来变量.常量的声明其实是很讲究的. 这里简单来谈谈var.const与let. 1.var.var声明的变量没有块级作用域, ...
- wamp apache无法启动的解决方法
作者 grunmin 2014.03.12 14:44* 字数 535 阅读 22167评论 9喜欢 5 如题,近日在安装wamp的时候出现了apache无法启动的情况.wamp图标一直显示橙色.网上 ...