python爬虫(3)——SSL证书与Handler处理器
一、SSL证书问题
上一篇文章,我们创建了一个小爬虫,下载了上海链家房产的几个网页。实际上我们在使用urllib联网的过程中,会遇到证书访问受限的问题。
处理HTTPS请求SSL证书验证,如果SSL证书验证不通过,会警告用户证书不受信任(即没有通过AC认证)。
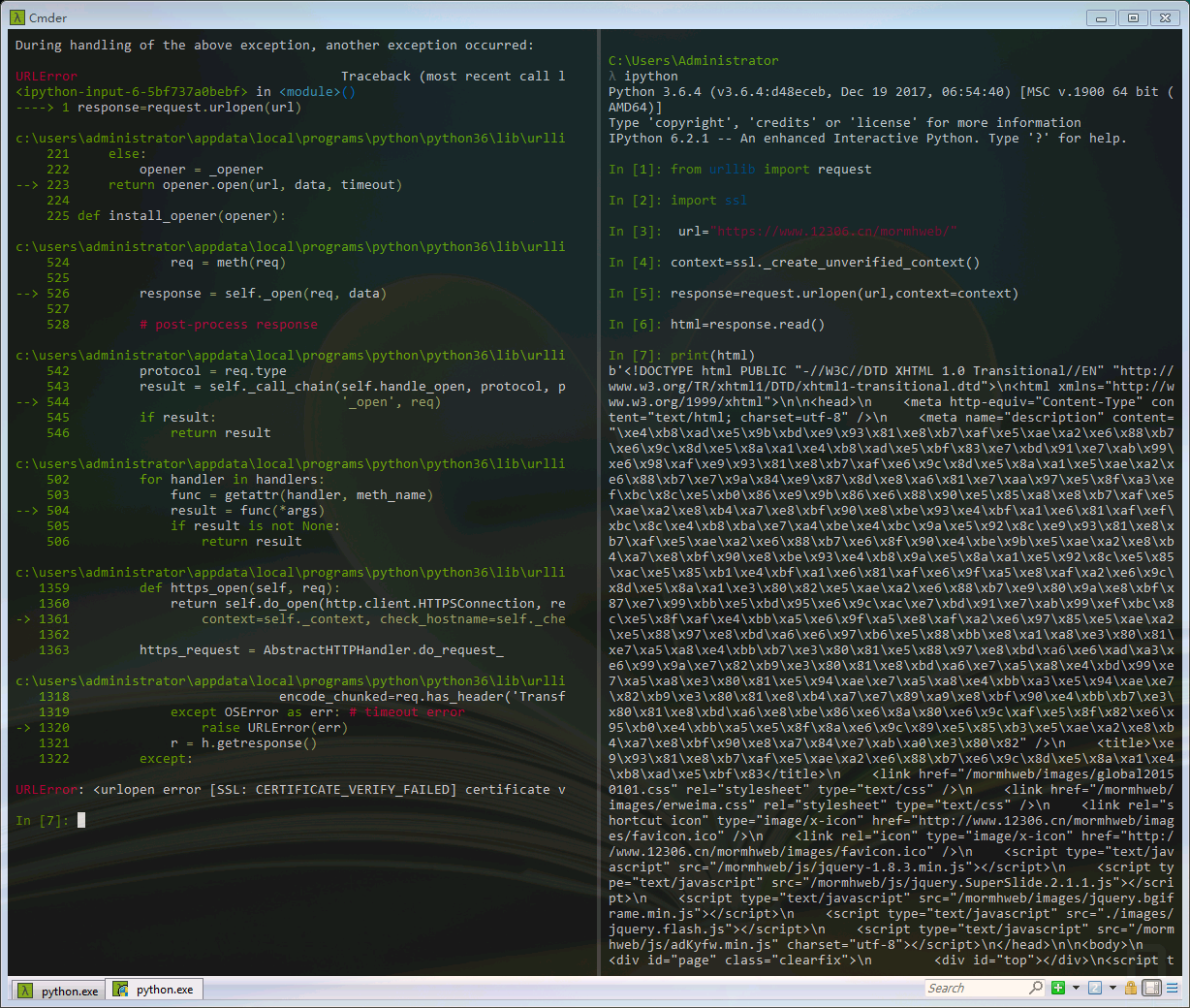
上图左边我们可以看到SSL验证失败,所以以后遇到这些网站我们需要单独处理SSL证书,让程序主动忽略SSL证书验证错误,即可正常访问。例如我们访问12306。
from urllib import request
#导入python的SSL处理模块
import ssl #忽略SSL验证失败
context=ssl._create_unverified_context() url="https://www.12306.cn/mormhweb/" response=request.urlopen(url,context=context)
html=response.read()
print(html)
二、Handler处理器以及自定义opener
我们之前一直使用的urlopen,它是一个模块帮我们构建好的特殊的opener。但是这个基本的urlopen()是不支持代理、cookie等其他的HTTP/HTTPS高级功能。所以我们需要利用Handler处理器自定义opener,来满足我们需要的这些功能。
import urllib.request url="http://www.whatismyip.com.tw/" #该参数是一个字典类型,键表示代理的类型,值为代理IP和端口号
proxy_support=urllib.request.ProxyHandler({'http':'117.86.199.19:8118'}) #接着创建一个包含代理的opener
opener=urllib.request.build_opener(proxy_support)
opener.addheaders=[("User-Agent","Mozilla/5.0(Macintosh;U;IntelMacOSX10_6_8;en-us)AppleWebKit/534.50(KHTML,likeGecko)Version/5.1Safari/534.50")] #第一种方式是使用install_opener()安装进默认环境,那么以后你使用urlopen()函数,它都是以你定制的opener工作的
urllib.request.install_opener(opener)
response=urllib.request.urlopen(url) #第二种使用一次性的opener.open()打开
#req=urllib.request.Request(url)
#response=opener.open(req) html=response.read().decode('utf-8')
print(html)
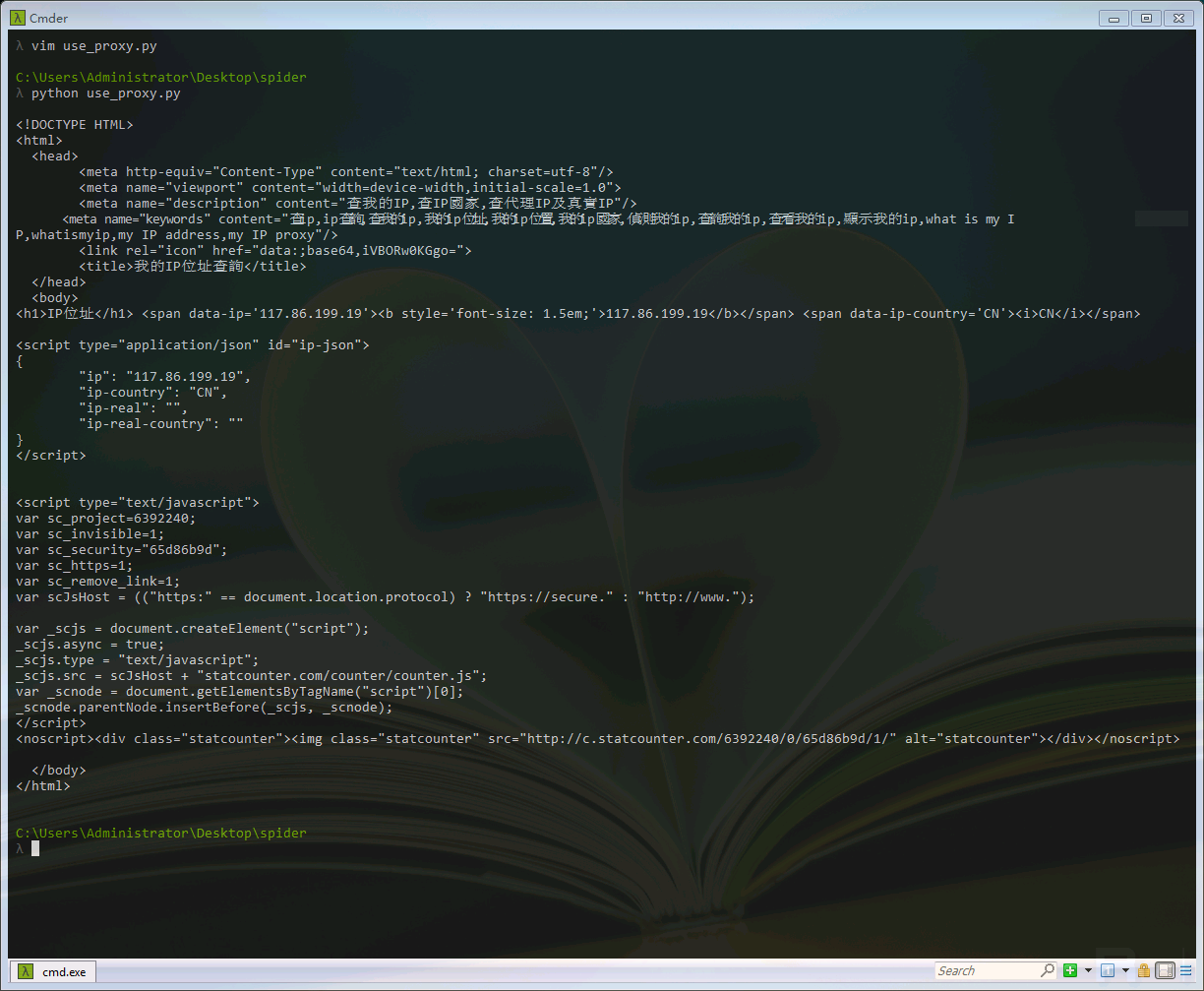
我们可以看到,访问网站的IP已经被换成了代理IP。在以上的设置代理的过程中,我们也使用addheaders这一函数,给请求附加了UserAgent,UserAgent中文名为用户代理,是Http协议中的一部分,属于头域的组成部分,UserAgent也简称UA。它是一个特殊字符串头,是一种向访问网站提供你所使用的浏览器类型及版本、操作系统及版本、浏览器内核、等信息的标识。这也是对抗反爬虫的常用手段之一。
python爬虫(3)——SSL证书与Handler处理器的更多相关文章
- python 爬虫 TCL SSL 安全证书问题
其实很复杂 但也很简单 只需要在requests爬虫编写前 加上这句话 requests.packages.urllib3.util.ssl_.DEFAULT_CIPHERS = 'DH+AES:RS ...
- python爬虫(六)_urllib2:handle处理器和自定义opener
本文将介绍handler处理器和自定义opener,更多内容请参考:python学习指南 opener和handleer 我们之前一直使用的是urllib2.urlopen(url)这种形式来打开网页 ...
- Python request SSL证书问题
错误信息如下: 1 requests.exceptions.SSLError: ("bad handshake: Error([('SSL routines', 'tls_process_s ...
- python之https爬虫出现 SSL: CERTIFICATE_VERIFY_FAILED (同时打开fiddler就会出现)
1.参考 Py 坑之 CERTIFICATE_VERIFY_FAILED Python 升级到 2.7.9 之后引入了一个新特性,当你urllib.urlopen一个 https 的时候,会验证一次 ...
- 网络请求 爬虫学习笔记 一 requsets 模块的使用 get请求和post请求初识别,代理,session 和ssl证书
前情提要: 为了养家糊口,为了爱与正义,为了世界和平, 从新学习一个爬虫技术,做一个爬虫学习博客记录 学习内容来自各大网站,网课,博客. 如果觉得食用不良,你来打我啊 requsets 个人觉得系统自 ...
- 爬虫之Handler处理器 和 自定义Opener
Handler处理器 和 自定义Opener opener是 urllib2.OpenerDirector 的实例,我们之前一直都在使用的urlopen,它是一个特殊的opener(也就是模块帮我们构 ...
- Python爬虫教程-15-读取cookie(人人网)和SSL(12306官网)
Python爬虫教程-15-爬虫读取cookie(人人网)和SSL(12306官网) 上一篇写道关于存储cookie文件,本篇介绍怎样读取cookie文件 cookie的读取 案例v16ssl文件:h ...
- python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题
python爬虫---详解爬虫分类,HTTP和HTTPS的区别,证书加密,反爬机制和反反爬策略,requests模块的使用,常见的问题 一丶爬虫概述 通过编写程序'模拟浏览器'上网,然后通 ...
- 爬虫urllib2中Handler处理器和自定义Opener
Handler处理器 和 自定义Opener opener是 urllib2.OpenerDirector 的实例,urlopen是一个特殊的opener(也就是模块已经构建好的). 但是基本的url ...
随机推荐
- 【转载】keil5中加入STM32F10X_HD,USE_STDPERIPH_DRIVER的原因
初学STM32,在RealView MDK 环境中使用STM32固件库建立工程时,初学者可能会遇到编译不通过的问题.出现如下警告或错误提示: warning: #223-D: function &qu ...
- css background之设置图片为背景技巧
css background之设置图片为背景技巧-css 背景 Background是什么意思,翻译过来有背景意思.同样在css里面作为css属性一成员同样是有背景意思,并且是设置背景图片.背景颜色. ...
- 邓_html_图片轮播
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- J.U.C JMM. pipeline.指令重排序,happen-before
pipeline: 现在的CPU一般采用流水线方式来执行指令.一个指令执行周期被分成:取值,译码,执行,访存,写会,更新PC若干阶段.然后,多条指令可以同时存在于流水线中,同时被执行,来提高系统的吞吐 ...
- python判断两个list包含关系
a = [1,2] b = [1,2,3] c = [0, 1] set(b) > set(a) set(b) > set(c)
- 配置SESSION超时与请求超时
<!--项目的web.xml中 配置SESSION超时,单位是min.用户在线时间.如果不设置,tomcat下的web.xml的session-timeout为默认.--><sess ...
- mysql主从配置主主配置
一. 概述 MySQL从3.23.15版本以后提供数据库复制(replication)功能,利用该功能可以实现两个数据库同步.主从模式.互相备份模式的功能.本文档主要阐述了如何在linux系 ...
- Linux cp 移动的时候报错
报错如下: cp: omitting directory `./nginx-1.12.1' 原因: 要移动的目录下还存在有目录 解决: cp -r 文件名 地址 注意: 这里的-r代表递归 ...
- 安卓和IOS兼容问题
点击穿透 click延迟 scroll元素临界的bug android screen.w/h 不准 rem不准 scroll时动画失效 animate回调 最小字号限制 不同机型全屏自适应 andro ...
- C# Linq基本常用用法
1.什么是Linq? Lanaguage Interated Query(语言集成查询),Linq 是集成C# 和VB这些语言中用于提供数据查询能力的一个新特性. 这里只介绍两种基本常用用法. 学习方 ...