Hadoop Yarn框架原理解析
在说Hadoop Yarn的原理之前,我们先来看看Yarn是怎样出现的。在古老的Hadoop1.0中,MapReduce的JobTracker负责了太多的工作,包括资源调度,管理众多的TaskTracker等工作。这自然就会产生一个问题,那就是JobTracker负载太多,有点“忙不过来”。于是Hadoop在1.0到2.0的升级过程中,便将JobTracker的资源调度工作独立了出来,而这一改动,直接让Hadoop成为大数据中最稳固的那一块基石。,而这个独立出来的资源管理框架,就是Hadoop Yarn框架 。
一. Hadoop Yarn是什么
在详细介绍Yarn之前,我们先简单聊聊Yarn,Yarn的全称是Yet Another Resource Negotiator,意思是“另一种资源调度器”,这种命名和“有间客栈”这种可谓是异曲同工之妙。这里多说一句,以前Java有一个项目编译工具,叫做Ant,他的命名也是类似的,叫做“Another Neat Tool”的缩写,翻译过来是”另一种整理工具“。
既然都叫做资源调度器了,那么自然,它的功能也是负责资源管理和调度的,接下来,我们就深入到Yarn框架内部一探究竟吧。
二. Hadoop Yarn架构原理剖析
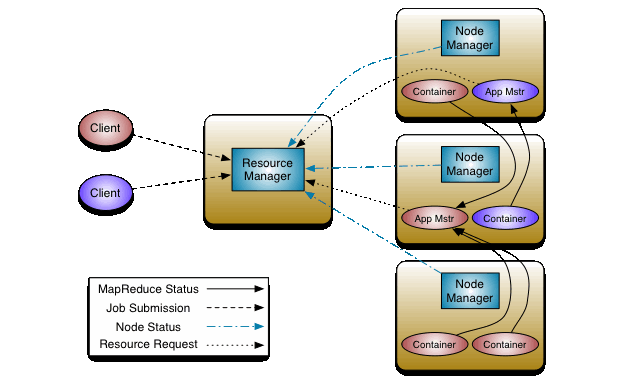
这张图可以说是Yarn的全景图,我们主要围绕上面这张图展开,介绍图中的每一个细节部分。首先,我们会介绍里面的Container的概念以及相关知识内容,然后会介绍图中一个个组件,最后看看提交一个程序的流程。
2.1 Container
容器(Container)这个东西是Yarn对资源做的一层抽象。就像我们平时开发过程中,经常需要对底层一些东西进行封装,只提供给上层一个调用接口一样,Yarn对资源的管理也是用到了这种思想。
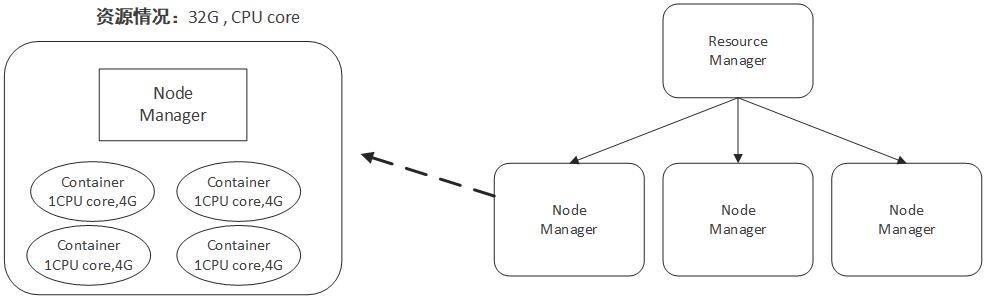
如上所示,Yarn将CPU核数,内存这些计算资源都封装成为一个个的容器(Container)。需要注意两点:
- 容器由NodeManager启动和管理,并被它所监控。
- 容器被ResourceManager进行调度。
其中NodeManager和ResourceManager这两个组件会在下面讲到。
2.2 Yarn的三个主要组件
再看最上面的图,我们能直观发现的两个主要的组件是ResourceManager和NodeManager,但其实还有一个ApplicationMaster在图中没有直观显示(其实就是图中的App Mstr,图里用了简写)。三个组件构成了Yarn的全景,这三个组件的主要工作是什么,Yarn 框架又是如何让他们相互配合的呢,我们分别来看这三个组件。
ResourceManager
我们先来说说上图中最中央的那个ResourceManager(RM)。从名字上我们就能知道这个组件是负责资源管理的,在运行过程中,整个系统有且只有一个RM,系统的资源正是由RM来负责调度管理的。RM包含了两个主要的组件:定时调用器(Scheduler)以及应用管理器(ApplicationManager),我们分别来看看它们的主要工作。
定时调度器(Scheduler):从本质上来说,定时调度器就是一种策略,或者说一种算法。当Client提交一个任务的时候,它会根据所需要的资源以及当前集群的资源状况进行分配。注意,它只负责向应用程序分配资源,并不做监控以及应用程序的状态跟踪。
应用管理器(ApplicationManager):同样,听名字就能大概知道它是干嘛的。应用管理器就是负责管理Client用户提交的应用。上面不是说到定时调度器(Scheduler)不对用户提交的程序监控嘛,其实啊,监控应用的工作正是由应用管理器(ApplicationManager)完成的。
OK,明白了资源管理器ResourceManager,那么应用程序如何申请资源,用完如何释放?这就是ApplicationMaster的责任了。
ApplicationMaster
每当Client(用户)提交一个Application(应用程序)时候,就会新建一个ApplicationMaster。由这个ApplicationMaster去与ResourceManager申请容器资源,获得资源后会将要运行的程序发送到容器上启动,然后进行分布式计算。
这里可能有些难以理解,为什么是把运行程序发送到容器上去运行?如果以传统的思路来看,是程序运行着不动,然后数据进进出出不停流转。但当数据量大的时候就没法这么玩了,因为海量数据移动成本太大,时间太长。但是中国有一句老话山不过来,我就过去。大数据分布式计算就是这种思想,既然大数据难以移动,那我就把容易移动的应用程序发布到各个节点进行计算呗,这就是大数据分布式计算的思路。
那么最后,资源有了,应用程序也有了,那么该怎么管理应用程序在每个节点上的计算呢?别急,我们还有一个NodeManager。
NodeManager
相比起上面两个组件的掌控全局,NodeManager就显得比较细微了。NodeManager是ResourceManager在每台机器的上代理,主要工作是负责容器的管理,并监控他们的资源使用情况(cpu,内存,磁盘及网络等),并且它会定期向ResourceManager/Scheduler提供这些资源使用报告,再由ResourceManager决定对节点的资源进行何种操作(分配,回收等)。
三. 提交一个Application到Yarn的流程
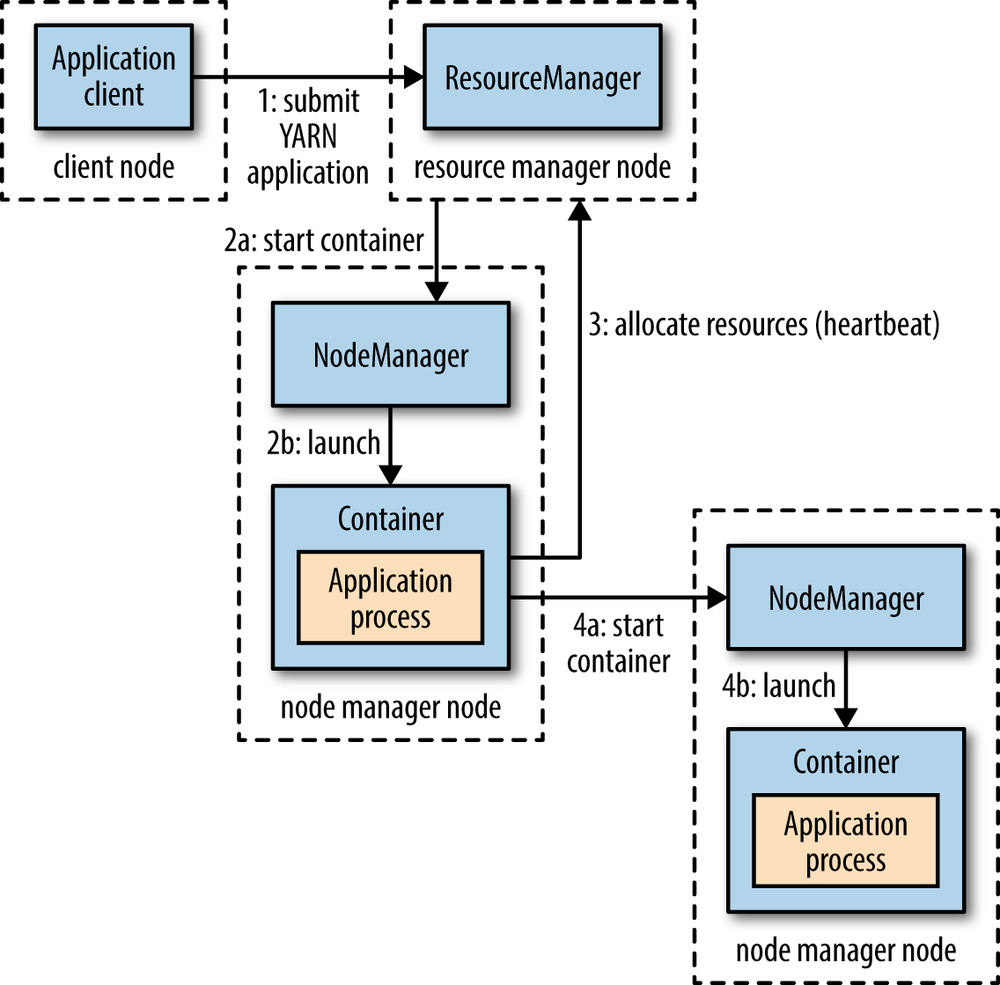
这张图简单地标明了提交一个程序所经历的流程,接下来我们来具体说说每一步的过程。
Client向Yarn提交Application,这里我们假设是一个MapReduce作业。
ResourceManager向NodeManager通信,为该Application分配第一个容器。并在这个容器中运行这个应用程序对应的ApplicationMaster。
ApplicationMaster启动以后,对作业(也就是Application)进行拆分,拆分task出来,这些task可以运行在一个或多个容器中。然后向ResourceManager申请要运行程序的容器,并定时向ResourceManager发送心跳。
申请到容器后,ApplicationMaster会去和容器对应的NodeManager通信,而后将作业分发到对应的NodeManager中的容器去运行,这里会将拆分后的MapReduce进行分发,对应容器中运行的可能是Map任务,也可能是Reduce任务。
容器中运行的任务会向ApplicationMaster发送心跳,汇报自身情况。当程序运行完成后,ApplicationMaster再向ResourceManager注销并释放容器资源。
以上就是一个作业的大体运行流程。
小结:这次我们介绍了Hadoop yarn的主要架构原理以及yarn上任务的运行流程。我们说了yarn的几个主要的组件,各自的责任,以及如何与其他组件协作调和。最后我们再来说说为什么会有Yarn这么个框架的出现吧~~
为什么会有Hadoop Yarn框架的出现?
上面说了这么多,最后我们来聊聊为什么会有Yarn吧。
直接的原因呢,就是因为Hadoop1.0中架构的缺陷,在MapReduce中,jobTracker担负起了太多的责任了,接收任务是它,资源调度是它,监控TaskTracker运行情况还是它。这样实现的好处是比较简单,但相对的,就容易出现一些问题,比如常见的单点故障问题。
要解决这些问题,只能将jobTracker进行拆分,将其中部分功能拆解出来。彼时业内已经有了一部分的资源管理框架,比如mesos,于是照着这个思路,就开发出了Yarn。这里多说个冷知识,其实Spark早期是为了推广mesos而产生的,这也是它名字的由来,不过后来反正是Spark火起来了。。。
闲话不多说,其实Hadoop能有今天这个地位,Yarn可以说是功不可没。因为有了Yarn,更多计算框架可以接入到Hdfs中,而不单单是MapReduce,到现在我们都知道,MapReduce早已经被Spark等计算框架赶超,而Hdfs却依然屹立不倒。究其原因,正式因为Yarn的包容,使得其他计算框架能专注于计算性能的提升。Hdfs可能不是最优秀的大数据存储系统,但却是应用最广泛的大数据存储系统,Yarn功不可没。
推荐阅读 :
从分治算法到 MapReduce
一个故事告诉你什么才是好的程序员
大数据存储的进化史 --从 RAID 到 Hadoop Hdfs
Hadoop Yarn框架原理解析的更多相关文章
- Hadoop Yarn 框架原理及运作机制及与MapReduce比较
Hadoop 和 MRv1 简单介绍 Hadoop 集群可从单一节点(其中所有 Hadoop 实体都在同一个节点上运行)扩展到数千个节点(其中的功能分散在各个节点之间,以增加并行处理活动).图 1 演 ...
- Hadoop — Yarn原理解析
1. 概述 Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台:而MapReduce等运算程序则相当运行于操作系统之上的应用程序. 2. YARN的重要概念 ...
- hadoop yarn
简介: 本文介绍了 Hadoop 自 0.23.0 版本后新的 map-reduce 框架(Yarn) 原理,优势,运作机制和配置方法等:着重介绍新的 yarn 框架相对于原框架的差异及改进:并通过 ...
- hadoop集群配置方法---mapreduce应用:xml解析+wordcount详解---yarn配置项解析
注:以下链接均为近期hadoop集群搭建及mapreduce应用开发查找到的资料.使用hadoop2.6.0,其中hadoop集群配置过程下面的文章都有部分参考. hadoop集群配置方法: ---- ...
- Hadoop数据操作系统YARN全解析
“ Hadoop 2.0引入YARN,大大提高了集群的资源利用率并降低了集群管理成本.其在异构集群中是怎样应用的?Hulu又有哪些成功实践可以分享? 为了能够对集群中的资源进行统一管理和调度,Hado ...
- Hadoop Yarn框架详细解析
在说Hadoop Yarn之前,我们先来看看Yarn是怎样出现的.在古老的Hadoop1.0中,MapReduce的JobTracker负责了太多的工作,包括资源调度,管理众多的TaskTracker ...
- Hadoop Yarn 安装
环境:Linux, 8G 内存.60G 硬盘 , Hadoop 2.2.0 为了构建基于Yarn体系的Spark集群.先要安装Hadoop集群,为了以后查阅方便记录了我本次安装的详细步骤. 事前准备 ...
- [bigdata] hadoop 参数配置解析
ResourceManager相关配置参数 yarn-site.xml 中配置 yarn.resourcemanager.address ResourceManager 对客户端暴露的地址.客户端通过 ...
- Hadoop YARN 100-1知识点
0 YARN中实体 资源管理者(resource manager, RM) 长时间运行的守护进程,负责管理集群上资源的使用 节点管理者(node manager, NM) 长时间运行的守护进程,在集群 ...
随机推荐
- C# 创建含多层分类标签的Excel图表
相较于数据,图表更能直观的体现数据的变化趋势.在数据表格中,同一数据值,可能同时代表不同的数据分类,表现在图表中则是一个数据体现在多个数据分类标签下.通常生成的图表一般默认只有一种分类标签,下面的方法 ...
- maven 依赖中scope标签的配置范围详解
在创建Maven项目时,需要在pom.xml 文件中添加相应的依赖,其中有一个scope标签,该标签是设置该依赖范围 (maven项目包含三种classpath{编译classpath,测试class ...
- ArcGIS API for JavaScript 入门教程[5] 再讲数据——Map类之底图与高程
[回顾]前4篇交代了JsAPI的背景.资源如何获取,简介了数据与视图分离的概念与实现,剖析了页面的大骨架. 这篇开始,讲Map类. 转载注明出处,博客园/CSDN/B站/知乎:秋意正寒 目录:http ...
- Unity的Mesh压缩:为什么我的内存没有变化?
0x00 前言 最近和朋友聊天,谈到了Mesh的内存优化问题,他发现开启Model Importer面板上的Mesh Compression选项之后,内存并没有什么变化.事实上,期望开启Mesh Co ...
- eggjs 框架代理调试 SELF_SIGNED_CERT_IN_CHAIN 报错解决方案
eggjs 中的 this.ctx.curl 可以发起一个请求,配置 proxy 可以很方面的通过接口进行问题定位.代理方式如下: 1.开启 egg-development-proxyagent ,配 ...
- javascript 字符串转换数字的方法大总结
方法主要有三种 转换函数.强制类型转换.利用js变量弱类型转换. 1. 转换函数: js提供了parseInt()和parseFloat()两个转换函数.前者把值转换成整数,后者把值转换成浮点数.只有 ...
- java常用工具(jps等)说明
Java为我们提供了大量的工具辅助我们进行开发,位于jdk目录下的bin目录里,本篇博客将会随时更新相关工具的使用说明. jps 获取当前运行的java应用 lgj@lgj-Lenovo-G470:~ ...
- 数组for循环查找范围
数组for循环查找范围,如果是判读是否在键值之间,如$array[$i],那么接邻的元素不能用$array[$i+1]或者$array[$i-1]只能用$array[$i++]
- Redis集群架构
Redis集群概述 集群的核心意义只有一个:保证一个节点出现了问题之后,其他的节点可以继续提供服务使用. Redis基础部分讲解过主从配置:对于主从配置可以有两类:一主二从,层级关系.开发者一主二从是 ...
- nginx.conf添加lua.conf配置
1.在nginx的conf下配置lua.conf......vi lua.conf server { listen ; server_name _; location /lua { default_t ...