Java-Web DOM方式解析xml文件
XML DOM 树形结构:
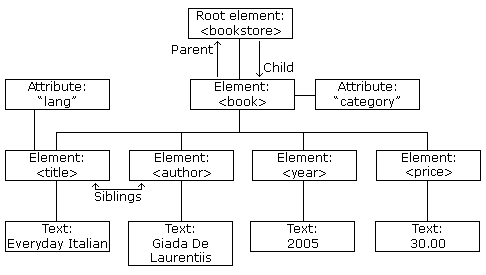
DOM 节点
根据 DOM,XML 文档中的每个成分都是一个节点。
DOM 是这样规定的:
- 整个文档是一个文档节点
- 每个 XML 元素是一个元素节点
- 包含在 XML 元素中的文本是文本节点
- 每一个 XML 属性是一个属性节点
- 注释是注释节点
常用节点类型
| 节点类型 | NodeType | Named Constant | nodeName 的返回值 | nodeValue 的返回值 |
| Element | 1 | ELEMENT_NODE | element name | null |
| Attr | 2 | ATTRIBUTE_NODE | 属性名称 | 属性值 |
| Text | 3 | TEXT_NODE | #text | 节点名称 |
案例:
目标:解析xml文件后,Java程序能够得到xml文件的所有数据
思考:如何在解析之后保留xml的结构信息
xml文档:

实例:
package Test;
/**
* 案例:运用DOM解析xml文件,获得xml文件的所有数据
*/
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList; public class DOMDemo {
public static void main(String[] args) throws Exception {
/** 步骤一:创建一个DocumentBuilderFactory的对象
* 1.定义工厂 API,使应用程序能够从 XML 文档获取生成 DOM 对象树的解析器。
* 2. protected DocumentBuilderFactory()
* 用于阻止实例化的受保护构造方法
* 3. static DocumentBuilderFactory newInstance()
* 获取 DocumentBuilderFactory 的新实例。
*/
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); /** 步骤二:创建一个DocumentBuilder的对象
* 1.protected DocumentBuilder()
* 受保护的构造方法
* 2.使其从 XML 文档获取 DOM 文档实例。使用此类,应用程序员可以从 XML 获取一个 Document。
*/
DocumentBuilder db = dbf.newDocumentBuilder(); /** 步骤三:通过DocumentBuilder对象的parse方法加载book.xml文件到当前目录下
* 1.parse(File f)
* 将给定文件的内容解析为一个 XML 文档,并且返回一个新的 DOM Document 对象。
*/
Document document = db.parse("books.xml"); /** 步骤四:获取所有book节点的集合
* 1.getElementsByTagName():通过节点的名称来获取所有同名节点,
* 因为不只有一个节点,所以就把获取的所有节点都存放在一个节点集合中。
*/
NodeList booklist = document.getElementsByTagName("book");
System.out.println("一共有" + booklist.getLength() + "本书"); /** 步骤五:遍历每一个book节点
* 1.Node item(int index)
* 返回集合中的第 index 个项。
* 2.NamedNodeMap getAttributes()
* 包含此节点的属性的 NamedNodeMap(如果它是 Element);否则为 null。
*/ for(int i = 0; i < booklist.getLength(); i++){ // 前提:不知道book节点的id属性有多少
System.out.println("===========下面开始遍历第" + (i+1) + "本书的内容===========");
// 通过item方法获取一个book节点
Node book = booklist.item(i);
// 获取book节点的所有属性集合
NamedNodeMap attrs = book.getAttributes();
System.out.println("第" + (i+1) + "本书共有" + attrs.getLength() + "个属性");
// 遍历book的属性
for(int j = 0; j < attrs.getLength(); j++){
// 通过item方法获取book节点的某一个属性
Node attr = attrs.item(j);
// 获取属性名
System.out.print("属性名:" + attr.getNodeName());
// 获取属性值
System.out.println("--属性值:" + attr.getNodeValue());
} /* // 前提:已经知道book节点有且只有一个id属性
// 将book节点进行强制类型转换,转换成Element类型
Element ebook = (Element)booklist.item(i);
// 通过getAttribute("id")方法来获取属性值
String attrValue = ebook.getAttribute("id");
System.out.println("id属性值为:" + attrValue);
*/ /** 步骤六:解析book节点的子节点
* 1.NodeList getChildNodes()
* 包含此节点的所有子节点的 NodeList。
*/
NodeList childNodes = book.getChildNodes();
// 遍历childNodes获取每个节点的节点名和节点值
System.out.println("第" + (i+1) + "本书共有" + childNodes.getLength() + "个子节点");
for(int k = 0; k < childNodes.getLength(); k++){ /* 如果不对节点类型进行判断
* 遍历book节点的子节点后会发现有9个子节点,但是我们只写了4个子节点
* 输出了5个#text节点,这是Text类型的节点。
* 因为空格也属于子节点,所以也会i被遍历出来。
* */
// 区分出text类型的node以及element类型的node
if(childNodes.item(k).getNodeType() == Node.ELEMENT_NODE){
// 获取element类型节点的节点名
System.out.print("第" + (k+1) + "个节点的是" + childNodes.item(k).getNodeName() + ": "); /* 当我们用childNodes.item(k).getNodeValue()这种方法获取
* element类型的节点的节点值时会返回空,因为他认为
* <name>冰与火之歌</name>中“冰与火之歌”是<name>的子节点,
* 所以返回<name>节点的值当然是null,因为它认为“冰与火之歌”是节点而不是内容。
* 我们这时需要返回<name>节点的第一个子节点,再返回第一个子节点的值就可以了,
* 或者用getTextContent()也可以解决,它会获取所有子节点的节点值
* */
// System.out.println(childNodes.item(k).getFirstChild().getNodeValue());
System.out.println(childNodes.item(k).getTextContent());
} } } } }
运行结果:
一共有2本书
===========下面开始遍历第1本书的内容===========
第1本书共有1个属性
属性名:id--属性值:1
第1本书共有9个子节点
第2个节点的是name: 冰与火之歌
第4个节点的是author: 乔治马丁
第6个节点的是year: 2014
第8个节点的是price: 89
===========下面开始遍历第2本书的内容===========
第2本书共有1个属性
属性名:id--属性值:2
第2本书共有9个子节点
第2个节点的是name: 格林童话
第4个节点的是year: 2004
第6个节点的是price: 66
第8个节点的是language: English
Java-Web DOM方式解析xml文件的更多相关文章
- 用JAXP的dom方式解析XML文件
用JAXP的dom方式解析XML文件,实现增删改查操作 dom方式解析XML原理 XML文件 <?xml version="1.0" encoding="UTF-8 ...
- 在iOS 开发中用GDataXML(DOM方式)解析xml文件
因为GDataXML的内部实现是通过DOM方式解析的,而在iOS 开发中用DOM方式解析xml文件,这个时候我们需要开启DOM,因为ios 开发中是不会自动开启的,只有在mac 开发中才自动开启的.我 ...
- Java&Xml教程(二)使用DOM方式解析XML文件
DOM XML 解析方式是最容易理解的,它將XML文件作为Document对象读取到内存中,然后你可以轻松地遍历不同的元素和节点对象.遍历元素和节点不需要按照顺序进行. DOM解析方式适合尺寸较小的X ...
- DOM方式解析XML文件实例
books.XML文件: <?xml version="1.0" encoding="utf-8"?><bookstore> &l ...
- dom方式解析xml文件的步骤
使用java类即可
- 用DOM方式解析XML
一.用DOM方式解析XML 此例子节点结构如下: 1.获取book节点属性 (1).如果不知道节点的属性,通过 NamedNodeMap attrs = book.getAttributes(); 来 ...
- Dom方式解析XML
public class TestXML { public static void main(String[] args) throws SAXException, IOException { //D ...
- Java眼中的XML--文件读取--1 应用DOM方式解析XML
初次邂逅XML: 需要解析的XML文件: 这里有两个book子节点. 1.如何进行XML文件解析前的准备工作,另外解析先获取book节点. 这个我后来看懂了: 这个Node的ELEMENT_NODE= ...
- Java&Xml教程(五)使用SAX方式解析XML文件
Java SAX解析机制为我们提供了一系列的API来处理XML文件,SAX解析和DOM解析方式不太一样,它并不是將XML文件内容一次性全部加载,而是连续的部分加载. javax.xml.parsers ...
随机推荐
- Codeforces Round #419 (Div. 2) E. Karen and Supermarket(树形dp)
http://codeforces.com/contest/816/problem/E 题意: 去超市买东西,共有m块钱,每件商品有优惠卷可用,前提是xi商品的优惠券被用.问最多能买多少件商品? 思路 ...
- POJ 2443 Set Operation(压位加速)
http://poj.org/problem?id=2443 题意: 有1000个集合,每个集合有至多10000个数,之后输入多个询问,判断询问的两个数是否位于同一个集合. 思路: 位运算...很强大 ...
- python 读取位于包中的数据文件
假设你的包中的文件组织成如下: mypackage/ __init__.py somedata.dat spam.py 现在假设spam.py文件需要读取somedata.dat文件中的内容.你可以用 ...
- 进入mac U盘文件夹命令
cd /Volumes 这条命令进入到你的u盘的上层文件夹,在这个文件夹里面包含了你的u盘,比如我的u盘名为SONG 则进入u盘的命令为 cd /Volumes/SONG
- offsetParent.scrollTop IE下一直报错,说“缺少对象”
<div style="position:fiexd; top:135px;_position: absolute; right: 0pt; _top:expression_r(off ...
- laravel中数据库迁移的使用:
创建数据库迁移文件: php artisan make:migration create_links_table 创建完表之后,设置字段: public function up() { Schema: ...
- Python+Flask+MysqL的web建设技术过程
一.前言(个人学期总结) 个人总结一下这学期对于Python+Flask+MysqL的web建设技术过程的学习体会,Flask小辣椒框架相对于其他框架而言,更加稳定,不会有莫名其妙的错误,容错性强,运 ...
- Jquery倒计时源码分享
在静态页添加显示倒计时的容器,并引用下面脚本,代入时间参数即可使用. timeoutDate——到期时间,时间格式为2014/01/01或2014/1/1 D——天 H——小时 M——分钟 S——秒 ...
- 用halcon提取衣服徽章
收到一封email,有个学员求助去除衣服上纹理的干扰,然后提取衣服上徽章的边缘的方法. 我想他肯定是个很努力上进的boy,在求助以前也许已经试过各种方法,通过二值化不断的调试阈值, 寻找各种边 ...
- Linux安装配置Nginx
之所以搭建Nginx,是因为要做一个图片服务器,之前已经搭建好了Ftp,要想实现通过网页的src标签显示图片需要,搭建web服务器(虽然也可以通过在img标签中的src属性里面写“ ftp://用户名 ...