Celery结合Django使用
一、Celery介绍
Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以轻松的实现任务的异步处理, 如果你的业务场景中需要用到异步任务,就可以考虑使用celery, 举几个实例场景中可用的例子:
- 你想对100台机器执行一条批量命令,可能会花很长时间 ,但你不想让你的程序等着结果返回,而是给你返回 一个任务ID,你过一段时间只需要拿着这个任务id就可以拿到任务执行结果, 在任务执行ing进行时,你可以继续做其它的事情。
- 你想做一个定时任务,比如每天检测一下你们所有客户的资料,如果发现今天 是客户的生日,就给他发个短信祝福
Celery 在执行任务时需要通过一个消息中间件来接收和发送任务消息,以及存储任务结果, 一般使用rabbitMQ or Redis
1.1 Celery有以下优点:
- 简单:一单熟悉了celery的工作流程后,配置和使用还是比较简单的
- 高可用:当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务
- 快速:一个单进程的celery每分钟可处理上百万个任务
- 灵活: 几乎celery的各个组件都可以被扩展及自定制
Celery基本工作流程图
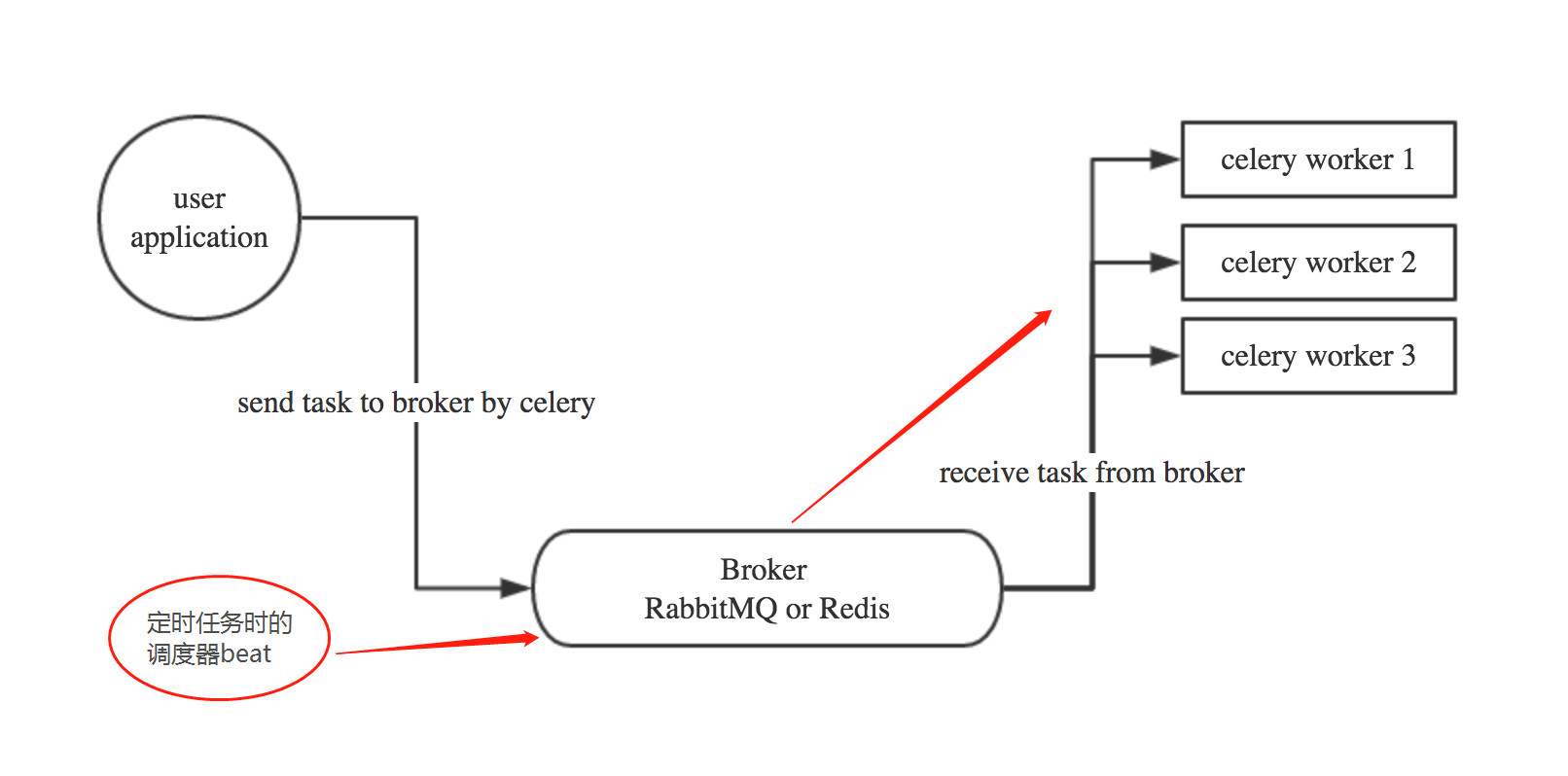
二、在Django项目中使用celery
可以把celery配置成一个应用
目录格式如下
proj/__init__.py
/celery.py
/tasks.py #名字固定
proj/celery.py内容
from __future__ import absolute_import, unicode_literals
#absolute_import (从绝对路径即celery安装目录导入celery,防止导入当前同名模块) unicode_literals(兼容python2和3)
from celery import Celery app = Celery('proj', #app名
broker='redis://:password@127.0.0.1', #接收任务使用的中间件
backend='redis://:password@127.0.0.1', #取数据时用的中间件
include=['proj.tasks']) #把tasks注册,当有多个tasks时可添加 # Optional configuration, see the application user guide. 还可以设置配置文件,实现更多自定义功能
#app.conf.update(
# result_expires=3600, #结果只保存3600s
#) if __name__ == '__main__':
app.start()
celery.py
proj/tasks.py中的内容
from __future__ import absolute_import, unicode_literals
from .celery import app #导入当前路径的celery模块 @app.task
def add(x, y):
return x + y @app.task
def mul(x, y):
return x * y @app.task
def xsum(numbers):
return sum(numbers)
tasks.py
启动worker
$ celery -A proj worker -l info
启动多个worker
$ celery multi start w1 -A proj -l info $ celery multi restart w1 -A proj -l info #重启worker $ celery multi stop w1 -A proj -l info #stop worker 由于停止命令是异步的,所以它不会等待worker完成所有任务再关闭。您可能希望使用stopwait命令,这确保在退出之前完成所有当前执行的任务: $ celery multi stopwait w1 -A proj -l info
在你的django views里调用celery task
from django.shortcuts import render,HttpResponse
# Create your views here.
from bernard import tasks
def task_test(request):
res = tasks.add.delay(228,24) #使用delay才会远程执行 返回的res是task_id,通过task_id取任务结果
print("start running task")
print("async task res",res.get() )
return HttpResponse('res %s'%res.get())
三、Django中的Celery 定时任务
1.Use pip to install the package:
$ pip install django-celery-beat
2. 将django_celery_beat 模块 添加到Django项目settings.py中的INSTALLED_APPS :
INSTALLED_APPS = (
...,
'django_celery_beat',
)
3.更新数据库会自动创建几张表:
$ python manage.py migrate
4.使用Django调度器开启 celery beat service
$ celery -A proj beat -l info -S django
5.访问Django管理界面以添加一些周期性任务。
在admin页面里,有3张表

配置完长这样
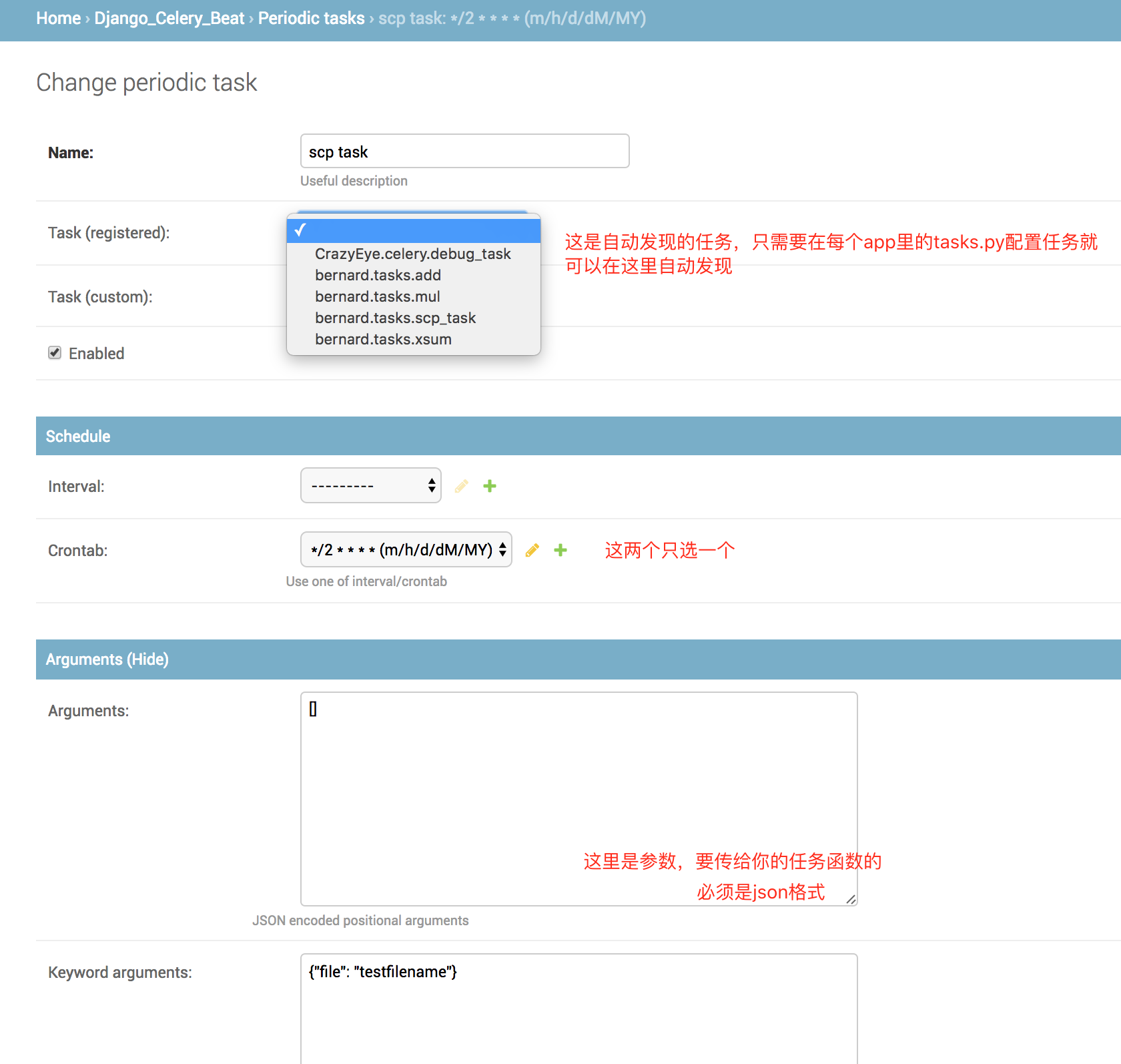
此时启动你的celery beat 和worker,会发现每隔2分钟,beat会发起一个任务消息让worker执行scp_task任务
!!注意,经测试,每添加或修改一个任务,celery beat都需要重启一次,要不然新的配置不会被celery beat进程读到
Celery结合Django使用的更多相关文章
- 异步任务队列Celery在Django中的使用
前段时间在Django Web平台开发中,碰到一些请求执行的任务时间较长(几分钟),为了加快用户的响应时间,因此决定采用异步任务的方式在后台执行这些任务.在同事的指引下接触了Celery这个异步任务队 ...
- 分布式队列celery 异步----Django框架中的使用
仅仅是个人学习的过程,发现有问题欢迎留言 一.celery 介绍 celery是一种功能完备的即插即用的任务对列 celery适用异步处理问题,比如上传邮件.上传文件.图像处理等比较耗时的事情 异步执 ...
- Using Celery with Django
参考1: http://docs.celeryproject.org/en/latest/django/first-steps-with-django.html#using-celery-with-d ...
- celery在Django中的集成使用
继上回安装和使用Redis之后,看看如何在Django中使用Celery.Celery是Python开发分布式任务列队的处理库.可以异步分布式地异步处理任务,也可定时执行任务等等.通常我们可以在Dja ...
- Celery在Django中的使用介绍
Celery在Django中的使用介绍 Celery简介 celery是一个简单.灵活且可靠的,处理大量消息的分布式系统,并且提供维护这样一个系统的必须工具. 它是一个专注于实时处理的任务队列,同时也 ...
- Celery与Django的结合
一.什么是Celery Celery 是一个 基于python开发的分布式异步消息任务队列,通过它可以实现任务的异步处理以及定时任务的处理,它的基本工作流程是: 先启动任务执行单元Worker,让它一 ...
- celery在Django中的应用
这里不解释celery,如果不清楚可以参考下面链接: http://docs.celeryproject.org/en/latest/getting-started/introduction.html ...
- Celery学习---Celery 与django结合实现计划任务功能
项目的目录结构: 项目前提: 安装并启动Redis 安装Django和Celery的定时任务插件 安装方法一: pip直接安装[安装了pip的前提下] omc@omc-virtual-machine: ...
- 使用celery执行Django串行异步任务
Django项目有一个耗时较长的update过程,希望在接到请求运行update过程的时候,Django应用仍能正常处理其他的请求,并且update过程要求不能并行,也不能漏掉任何一个请求 使用cel ...
随机推荐
- ORACLE取字段中的注释
select * from (SELECT 'comment on column '|| t.table_name||'.'||t.colUMN_NAME||' is '|| ''''||t1.COM ...
- python模块之time_random
把老师的资料放在最上面: 参考: http://www.cnblogs.com/yuanchenqi/articles/5732581.html 导入模块的方法: #!/usr/bin/env pyt ...
- more语法
二.more 文件内容或输出查看工具 more 是我们最常用的工具之一,最常用的就是显示输出的内容,然后根据窗口的大小进行分页显示,然后还能提示文件的百分比: [root@localhost ~]# ...
- 已经在Git Server服务器上导入了SSH公钥,可用TortoiseGit同步代码时,还是提示输入密码?
GitHub虽好,但毕竟在国内访问不是很稳定,速度也不快,而且推送到上面的源码等资料必须公开,除非你给他交了保护费:所以有条件的话,建议大家搭建自己的Git Server.本地和局域网服务器都好,不信 ...
- Nginx+Tomcat配置负载均衡(一)
关于负载均衡原理方面的知识点不在本文讨论范畴,本文主要就负载均衡配置过程中的细节部分配置做详细说明. 本次负载均衡大致的配置如下: 环境 : WIN7 + VM虚拟机3台(centos6.5) Ngi ...
- idea 从git上checkout项目下来,project没有文件目录结构
1.去到 查看sdk有没有配置 查看该部分是否是空的,如果没有显示项目,添加导入项目
- google Kickstart Round F 2017 四道题题解
Problem A. Kicksort 题意抽象一下为: 对于一个每次都从数列正中间取划分数的快速排序,给定一个1-n的排列,问快排的复杂度对于这个排列是否会退化为最坏复杂度. 数据范围: 测试组数1 ...
- HTML标记语言
一.html的文档结构 html含义为超文本标记语言,html文档重要由4个标签来组成就是<html> <head> <title> <body> ...
- ImageUtil
package com.rscode.credits.util; import java.io.File; import java.io.IOException; import java.util.A ...
- 自动化测试_Mac安装python+selenium
1.下载安装(参照下文) https://blog.csdn.net/kacylining/article/details/60587484 https://www.zhihu.com/questio ...