An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)
01 Mar 2018 Piotr Nowojski (@PiotrNowojski) & Mike Winters (@wints)
This post is an adaptation of Piotr Nowojski’s presentation from Flink Forward Berlin 2017. You can find the slides and a recording of the presentation on the Flink Forward Berlin website.
Apache Flink 1.4.0, released in December 2017, introduced a significant milestone for stream processing with Flink: a new feature called TwoPhaseCommitSinkFunction (relevant Jira here) that extracts the common logic of the two-phase commit protocol and makes it possible to build end-to-end exactly-once applications with Flink and a selection of data sources and sinks, including Apache Kafka versions 0.11 and beyond. It provides a layer of abstraction and requires a user to implement only a handful of methods to achieve end-to-end exactly-once semantics.
If that’s all you need to hear, let us point you to the relevant place in the Flink documentation, where you can read about how to put TwoPhaseCommitSinkFunction to use.
But if you’d like to learn more, in this post, we’ll share an in-depth overview of the new feature and what is happening behind the scenes in Flink.
Throughout the rest of this post, we’ll:
- Describe the role of Flink’s checkpoints for guaranteeing exactly-once results within a Flink application.
- Show how Flink interacts with data sources and data sinks via the two-phase commit protocol to deliver end-to-end exactly-once guarantees.
- Walk through a simple example on how to use
TwoPhaseCommitSinkFunctionto implement an exactly-once file sink.
Exactly-once Semantics Within an Apache Flink Application
When we say “exactly-once semantics”, what we mean is that each incoming event affects the final results exactly once. Even in case of a machine or software failure, there’s no duplicate data and no data that goes unprocessed.
Flink has long provided exactly-once semantics within a Flink application. Over the past few years, we’ve written in depth about Flink’s checkpointing, which is at the core of Flink’s ability to provide exactly-once semantics. The Flink documentation also provides a thorough overview of the feature.
Before we continue, here’s a quick summary of the checkpointing algorithm because understanding checkpoints is necessary for understanding this broader topic.
A checkpoint in Flink is a consistent snapshot of:
- The current state of an application
- The position in an input stream
Flink generates checkpoints on a regular, configurable interval and then writes the checkpoint to a persistent storage system, such as S3 or HDFS. Writing the checkpoint data to the persistent storage happens asynchronously, which means that a Flink application continues to process data during the checkpointing process.
In the event of a machine or software failure and upon restart, a Flink application resumes processing from the most recent successfully-completed checkpoint; Flink restores application state and rolls back to the correct position in the input stream from a checkpoint before processing starts again. This means that Flink computes results as though the failure never occurred.
Before Flink 1.4.0, exactly-once semantics were limited to the scope of a Flink application only and did not extend to most of the external systems to which Flink sends data after processing.
But Flink applications operate in conjunction with a wide range of data sinks, and developers should be able to maintain exactly-once semantics beyond the context of one component.
To provide end-to-end exactly-once semantics–that is, semantics that also apply to the external systems that Flink writes to in addition to the state of the Flink application–these external systems must provide a means to commit or roll back writes that coordinate with Flink’s checkpoints.
One common approach for coordinating commits and rollbacks in a distributed system is the two-phase commit protocol. In the next section, we’ll go behind the scenes and discuss how Flink’s TwoPhaseCommitSinkFunction utilizes the two-phase commit protocol to provide end-to-end exactly-once semantics.
End-to-end Exactly Once Applications with Apache Flink
We’ll walk through the two-phase commit protocol and how it enables end-to-end exactly-once semantics in a sample Flink application that reads from and writes to Kafka. Kafka is a popular messaging system to use along with Flink, and Kafka recently added support for transactions with its 0.11 release. This means that Flink now has the necessary mechanism to provide end-to-end exactly-once semantics in applications when receiving data from and writing data to Kafka.
Flink’s support for end-to-end exactly-once semantics is not limited to Kafka and you can use it with any source / sink that provides the necessary coordination mechanism. For example, Pravega, an open-source streaming storage system from Dell/EMC, also supports end-to-end exactly-once semantics with Flink via the TwoPhaseCommitSinkFunction.
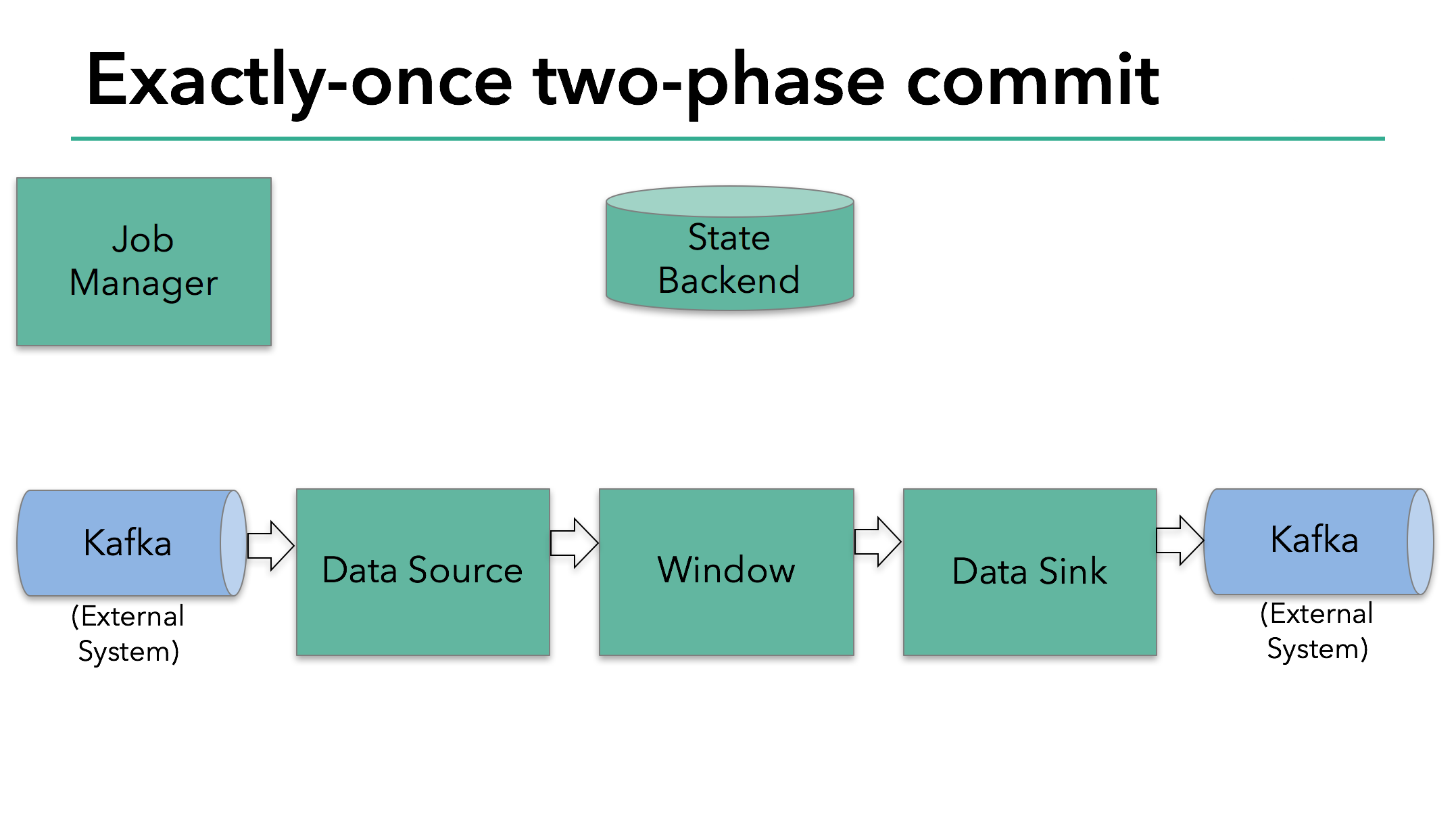
In the sample Flink application that we’ll discuss today, we have:
- A data source that reads from Kafka (in Flink, a KafkaConsumer)
- A windowed aggregation
- A data sink that writes data back to Kafka (in Flink, a KafkaProducer)
For the data sink to provide exactly-once guarantees, it must write all data to Kafka within the scope of a transaction. A commit bundles all writes between two checkpoints.
This ensures that writes are rolled back in case of a failure.
However, in a distributed system with multiple, concurrently-running sink tasks, a simple commit or rollback is not sufficient, because all of the components must “agree” together on committing or rolling back to ensure a consistent result. Flink uses the two-phase commit protocol and its pre-commit phase to address this challenge.
The starting of a checkpoint represents the “pre-commit” phase of our two-phase commit protocol. When a checkpoint starts, the Flink JobManager injects a checkpoint barrier (which separates the records in the data stream into the set that goes into the current checkpoint vs. the set that goes into the next checkpoint) into the data stream.
The barrier is passed from operator to operator. For every operator, it triggers the operator’s state backend to take a snapshot of its state.
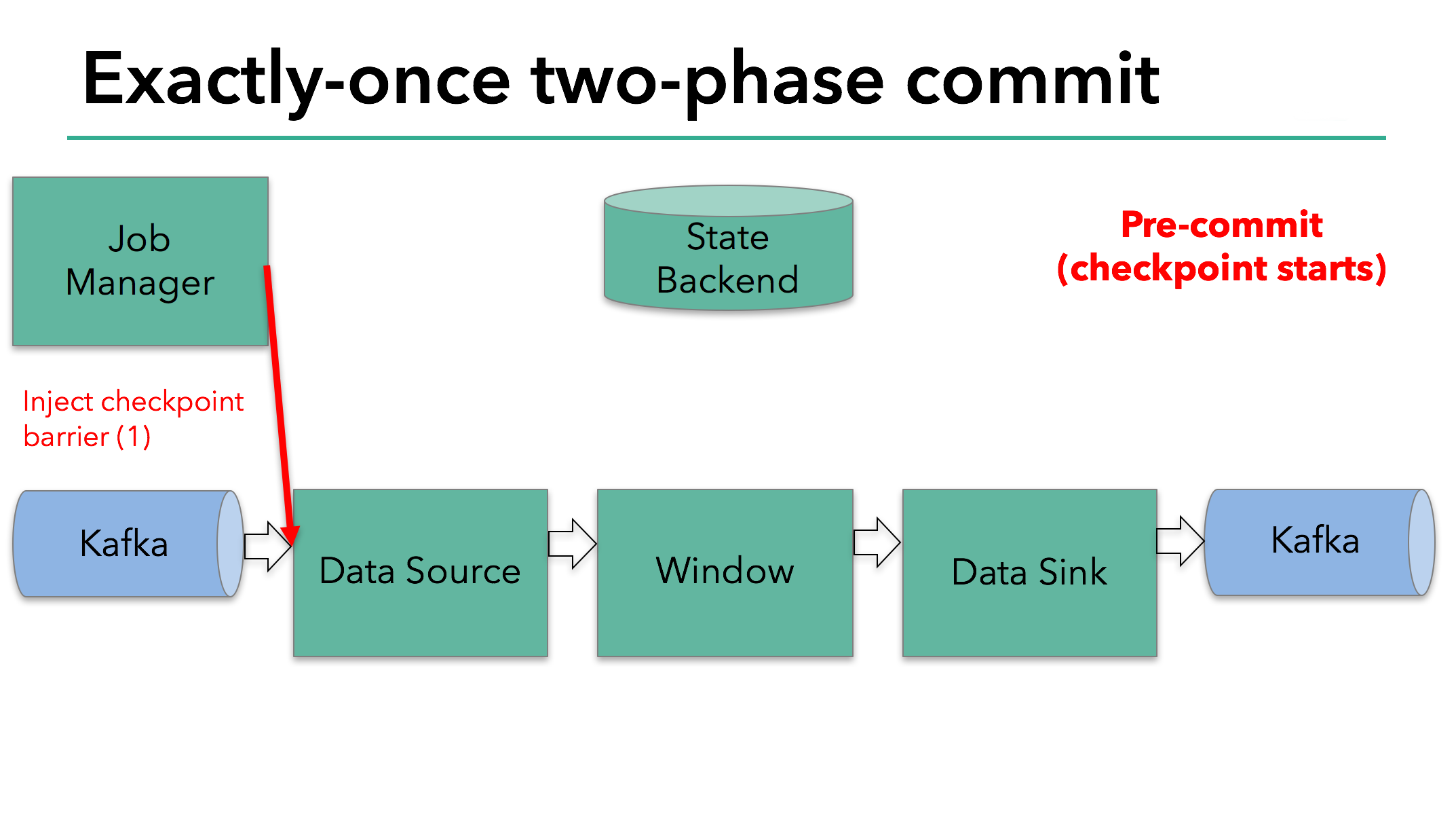
The data source stores its Kafka offsets, and after completing this, it passes the checkpoint barrier to the next operator.
This approach works if an operator has internal state only. Internal state is everything that is stored and managed by Flink’s state backends - for example, the windowed sums in the second operator. When a process has only internal state, there is no need to perform any additional action during pre-commit aside from updating the data in the state backends before it is checkpointed. Flink takes care of correctly committing those writes in case of checkpoint success or aborting them in case of failure.
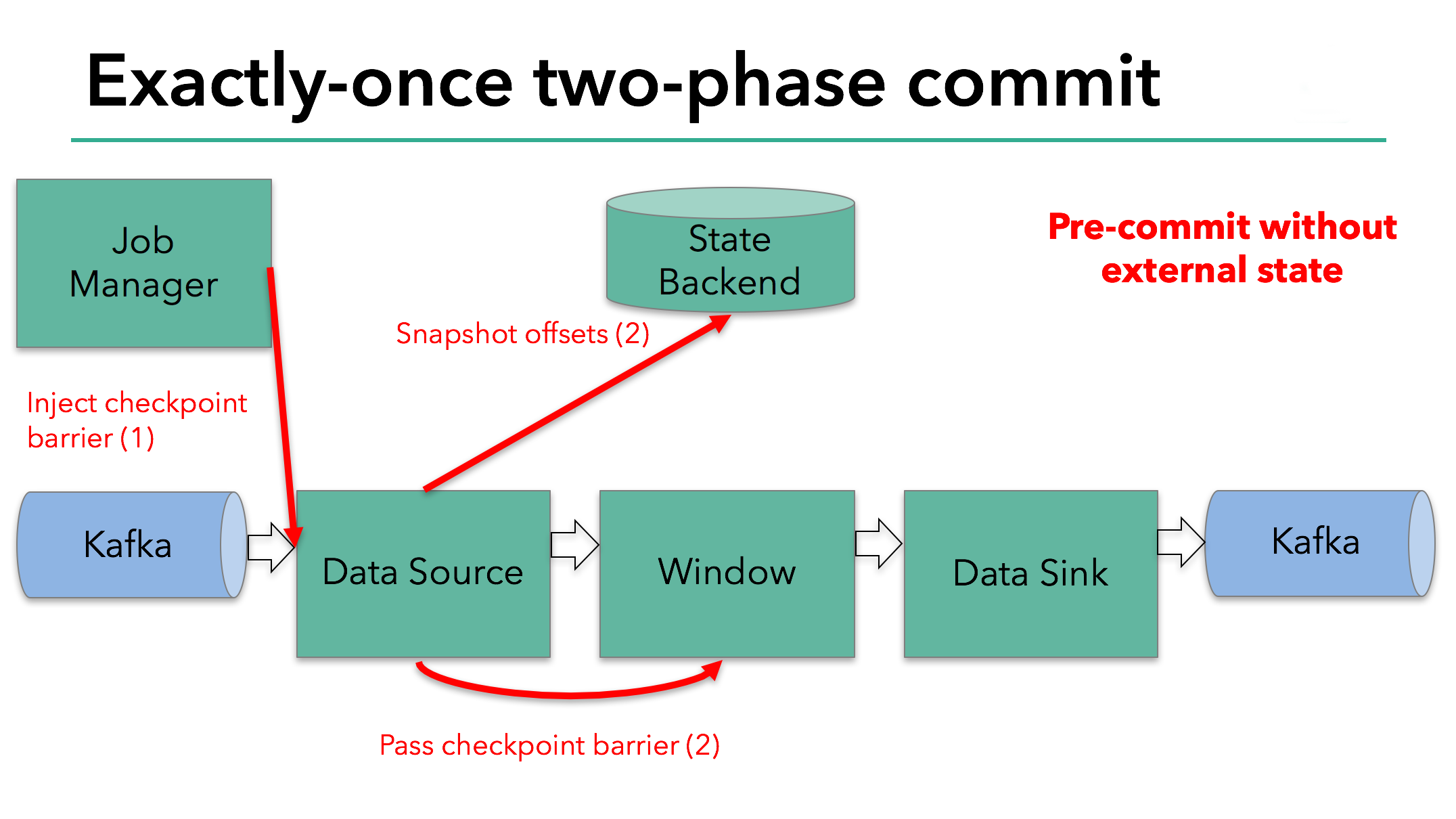
However, when a process has external state, this state must be handled a bit differently. External state usually comes in the form of writes to an external system such as Kafka. In that case, to provide exactly-once guarantees, the external system must provide support for transactions that integrates with a two-phase commit protocol.
We know that the data sink in our example has such external state because it’s writing data to Kafka. In this case, in the pre-commit phase, the data sink must pre-commit its external transaction in addition to writing its state to the state backend.
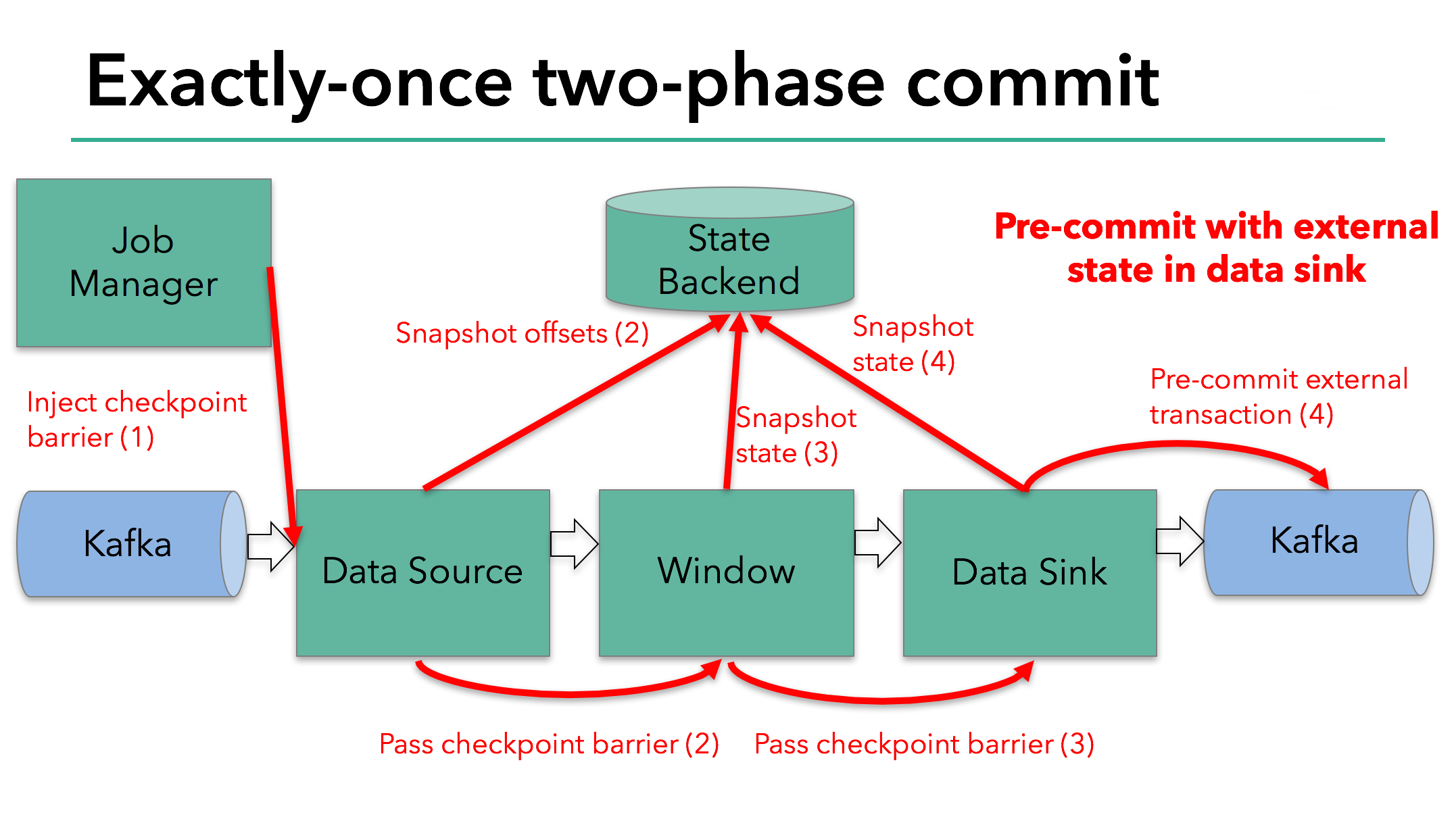
The pre-commit phase finishes when the checkpoint barrier passes through all of the operators and the triggered snapshot callbacks complete. At this point the checkpoint completed successfully and consists of the state of the entire application, including pre-committed external state. In case of a failure, we would re-initialize the application from this checkpoint.
The next step is to notify all operators that the checkpoint has succeeded. This is the commit phase of the two-phase commit protocol and the JobManager issues checkpoint-completed callbacks for every operator in the application. The data source and window operator have no external state, and so in the commit phase, these operators don’t have to take any action. The data sink does have external state, though, and commits the transaction with the external writes.
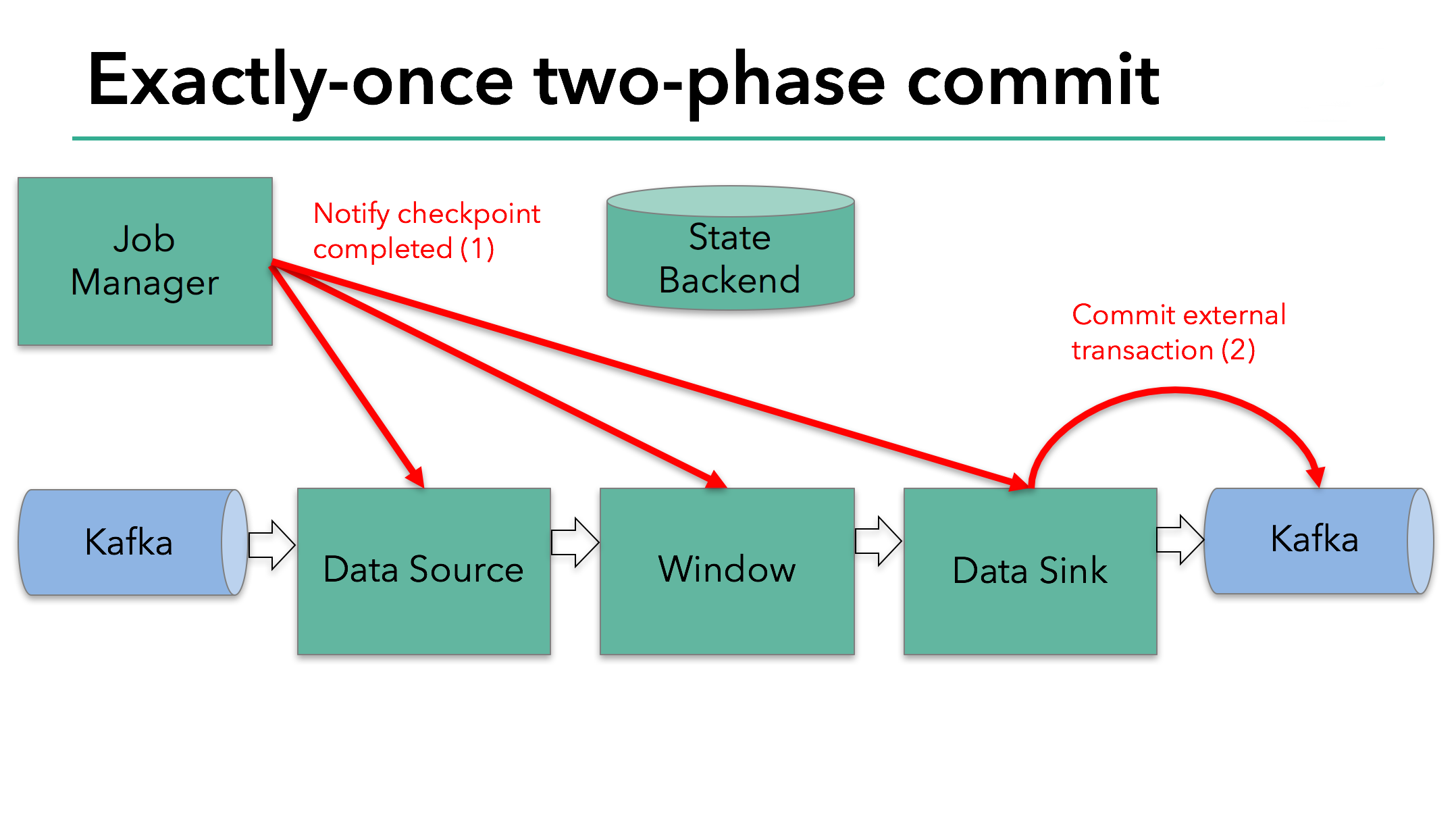
So let’s put all of these different pieces together:
- Once all of the operators complete their pre-commit, they issue a commit.
- If at least one pre-commit fails, all others are aborted, and we roll back to the previous successfully-completed checkpoint.
- After a successful pre-commit, the commit must be guaranteed to eventually succeed – both our operators and our external system need to make this guarantee. If a commit fails (for example, due to an intermittent network issue), the entire Flink application fails, restarts according to the user’s restart strategy, and there is another commit attempt. This process is critical because if the commit does not eventually succeed, data loss occurs.
Therefore, we can be sure that all operators agree on the final outcome of the checkpoint: all operators agree that the data is either committed or that the commit is aborted and rolled back.
Implementing the Two-Phase Commit Operator in Flink
All the logic required to put a two-phase commit protocol together can be a little bit complicated and that’s why Flink extracts the common logic of the two-phase commit protocol into the abstract TwoPhaseCommitSinkFunction class.
Let’s discuss how to extend a TwoPhaseCommitSinkFunction on a simple file-based example. We need to implement only four methods and present their implementations for an exactly-once file sink:
beginTransaction -to begin the transaction, we create a temporary file in a temporary directory on our destination file system. Subsequently, we can write data to this file as we process it.preCommit -on pre-commit, we flush the file, close it, and never write to it again. We’ll also start a new transaction for any subsequent writes that belong to the next checkpoint.commit -on commit, we atomically move the pre-committed file to the actual destination directory. Please note that this increases the latency in the visibility of the output data.abort -on abort, we delete the temporary file.
As we know, if there’s any failure, Flink restores the state of the application to the latest successful checkpoint. One potential catch is in a rare case when the failure occurs after a successful pre-commit but before notification of that fact (a commit) reaches our operator. In that case, Flink restores our operator to the state that has already been pre-committed but not yet committed.
We must save enough information about pre-committed transactions in checkpointed state to be able to either abort or commit transactions after a restart. In our example, this would be the path to the temporary file and target directory.
The TwoPhaseCommitSinkFunction takes this scenario into account, and it always issues a preemptive commit when restoring state from a checkpoint. It is our responsibility to implement a commit in an idempotent way. Generally, this shouldn’t be an issue. In our example, we can recognize such a situation: the temporary file is not in the temporary directory, but has already been moved to the target directory.
There are a handful of other edge cases that TwoPhaseCommitSinkFunction takes into account, too. Learn more in the Flink documentation.
Wrapping Up
If you’ve made it this far, thanks for staying with us through a detailed post. Here are some key points that we covered:
- Flink’s checkpointing system serves as Flink’s basis for supporting a two-phase commit protocol and providing end-to-end exactly-once semantics.
- An advantage of this approach is that Flink does not materialize data in transit the way that some other systems do–there’s no need to write every stage of the computation to disk as is the case is most batch processing.
- Flink’s new
TwoPhaseCommitSinkFunctionextracts the common logic of the two-phase commit protocol and makes it possible to build end-to-end exactly-once applications with Flink and external systems that support transactions - Starting with Flink 1.4.0, both the Pravega and Kafka 0.11 producers provide exactly-once semantics; Kafka introduced transactions for the first time in Kafka 0.11, which is what made the Kafka exactly-once producer possible in Flink.
- The Kafka 0.11 producer is implemented on top of the
TwoPhaseCommitSinkFunction, and it offers very low overhead compared to the at-least-once Kafka producer.
We’re very excited about what this new feature enables, and we look forward to being able to support additional producers with the TwoPhaseCommitSinkFunction in the future.
This post first appeared on the data Artisans blogand was contributed to Apache Flink and the Flink blog by the original authors Piotr Nowojski and Mike Winters.
An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)的更多相关文章
- Kafka设计解析(二十二)Flink + Kafka 0.11端到端精确一次处理语义的实现
转载自 huxihx,原文链接 [译]Flink + Kafka 0.11端到端精确一次处理语义的实现 本文是翻译作品,作者是Piotr Nowojski和Michael Winters.前者是该方案 ...
- <译>Flink编程指南
Flink 的流数据 API 编程指南 Flink 的流数据处理程序是常规的程序 ,通过再流数据上,实现了各种转换 (比如 过滤, 更新中间状态, 定义窗口, 聚合).流数据可以来之多种数据源 (比如 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 大数据开发-Flink-数据流DataStream和DataSet
Flink主要用来处理数据流,所以从抽象上来看就是对数据流的处理,正如前面大数据开发-Flink-体系结构 && 运行架构提到写Flink程序实际上就是在写DataSource.Tra ...
- Apache Sqoop - Overview——Sqoop 概述
Apache Sqoop - Overview Apache Sqoop 概述 使用Hadoop来分析和处理数据需要将数据加载到集群中并且将它和企业生产数据库中的其他数据进行结合处理.从生产系统加载大 ...
- Apache Sqoop - Overview Apache Sqoop 概述
使用Hadoop来分析和处理数据需要将数据加载到集群中并且将它和企业生产数据库中的其他数据进行结合处理.从生产系统加载大块数据到Hadoop中或者从大型集群的map reduce应用中获得数据是个挑战 ...
- Java资源大全中文版(Awesome最新版)
Awesome系列的Java资源整理.awesome-java 就是akullpp发起维护的Java资源列表,内容包括:构建工具.数据库.框架.模板.安全.代码分析.日志.第三方库.书籍.Java 站 ...
- Linux 集群
html,body { } .CodeMirror { height: auto } .CodeMirror-scroll { } .CodeMirror-lines { padding: 4px 0 ...
- Gradle笔记系列(一)
1.Gradle概述 Gradle是一个基于Apache Ant和Apache Maven概念的项目自动化构建工具.它使用一种基于Groovy的特定领域语言(DSL)来声明项目设置,抛弃了基于XML的 ...
随机推荐
- PerformanceCounter蛋痛的设计
在.NET下对进程的性能计数可以使用PerformanceCounter,通过该对象可以对进程的CPU,内存等信息进行统计.对于正常使用来说这个对象还是很方便,但对于同一名称的多个进程进行性能计数那真 ...
- SpringBoot入门教程(十五)集成Druid
Druid是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0.DBCP.PROXOOL等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况,可以说是针对监控而生的DB ...
- 《HelloGitHub月刊》第 09 期
<HelloGitHub>第 09 期 兴趣是最好的老师,<HelloGitHub>就是帮你找到兴趣! 前言 转眼就到年底了,月刊做到了第09期,感谢大家一路的支持和帮助
- LeetCode专题-Python实现之第14题:Longest Common Prefix
导航页-LeetCode专题-Python实现 相关代码已经上传到github:https://github.com/exploitht/leetcode-python 文中代码为了不动官网提供的初始 ...
- eclipse创建的maven项目,pom.xml文件报错解决方法
[错误一:]maven 编译级别过低 [解决办法:] 使用 maven-compiler-plugin 将 maven 编译级别改为 jdk1.6 以上: <!-- java编译插件 --> ...
- IO帮助类
using System; using System.IO; using System.Web; using System.Drawing; using System.Drawing.Imaging; ...
- 拯救老旧工程,记桥接SpringMVC与Stripes框架
背景: 公司基础设施部门推出了自己的微服务框架(以下简称M),要求所有业务应用都要接入进去,但坑爹的是M只提供了SpringMVC工程的support,对于采用Stripes作为MVC框架的应用并不支 ...
- (4)Maven快速入门_4在Spring+SpringMVC+MyBatis+Oracle+Maven框架整合运行在Tomcat8中
利用Maven 创建Spring+SpringMVC+MyBatis+Oracle 项目 分了三个项目 Dao (jar) Service (jar) Controller (web) ...
- 聊聊 API Gateway 和 Netflix Zuul
最近参与了公司 API Gateway 的搭建工作,技术选型是 Netflix Zuul,主要聊一聊其中的一些心得和体会. 本文主要是介绍使用 Zuul 且在不强制使用其他 Neflix OSS 组件 ...
- 页面内容不够高footer始终位于页面的最底部
相信很多前端工程师在开发页面时会遇到这个情况:当整个页面高度不足以占满显示屏一屏,页脚不是在页面最底部,用户视觉上会有点不好看,想让页脚始终在页面最底部,我们可能会想到用: 1.min-height来 ...