皮尔逊相关系数(Pearson Correlation Coefficient, Pearson's r)
Pearson's r,称为皮尔逊相关系数(Pearson correlation coefficient),用来反映两个随机变量之间的线性相关程度。
用于总体(population)时记作ρ (rho)(population correlation coefficient):
给定两个随机变量X,Y,ρ的公式为:

其中: 


用于样本(sample)时记作r(sample correlation coefficient):
给定两个随机变量x,y,r的公式为:

其中: 



r的取值在-1与1之间。取值为1时,表示两个随机变量之间呈完全正相关关系;取值为-1时,表示两个随机变量之间呈完全负相关关系;取值为0时,表示两个随机变量之间线性无关。
(注:我们用样本相关系数r作为总体相关系数ρ的估计值,要判断r值是不是由抽样误差或偶然因素导致的,需要进行假设检验。)
那么皮尔逊相关系数是怎么得来的呢?(参考:https://blog.csdn.net/ichuzhen/article/details/79535226)
要理解皮尔逊相关系数,首先要理解协方差(Covariance)
。协方差可以反映两个随机变量之间的关系,如果一个变量跟随着另一个变量一起变大或者变小,那么这两个变量的协方差就是正值,就表示这两个变量之间呈正相关关系,反之相反。协方差的公式如下:
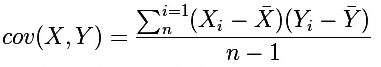
如果协方差的值是个很大的正数,我们可以得到两个可能的结论:
(1) 两个变量之间呈很强的正相关性
(2) 两个变量之间并没有很强的正相关性,协方差的值很大是因为X或Y的标准差很大
那么到底哪个结论正确呢?只要把X和Y变量的标准差,从协方差中剔除不就知道了吗?协方差能告诉我们两个随机变量之间的关系,但是却没法衡量变量之间相关性的强弱。因此,为了更好地度量两个随机变量之间的相关程度,引入了皮尔逊相关系数。可以看到,皮尔逊相关系数就是用协方差除以两个变量的标准差得到的。
皮尔逊相关系数(Pearson Correlation Coefficient, Pearson's r)的更多相关文章
- 皮尔逊相关系数与余弦相似度(Pearson Correlation Coefficient & Cosine Similarity)
之前<皮尔逊相关系数(Pearson Correlation Coefficient, Pearson's r)>一文介绍了皮尔逊相关系数.那么,皮尔逊相关系数(Pearson Corre ...
- 【ML基础】皮尔森相关系数(Pearson correlation coefficient)
前言 参考 1. 皮尔森相关系数(Pearson correlation coefficient): 完
- [Statistics] Comparison of Three Correlation Coefficient: Pearson, Kendall, Spearman
There are three popular metrics to measure the correlation between two random variables: Pearson's c ...
- PCC值average pearson correlation coefficient计算方法
1.先找到task paradise 的m1-m6: 2.根据公式Dy=D1* 1/P*∑aT ,例如 D :t*k1 a:k2*k1: Dy :t*k2 Dy应该有k2个原子,维度是t: 3.依 ...
- Pearson product-moment correlation coefficient in java(java的简单相关系数算法)
一.什么是Pearson product-moment correlation coefficient(简单相关系数)? 相关表和相关图可反映两个变量之间的相互关系及其相关方向,但无法确切地表明两个变 ...
- Pearson Correlation Score
[http://www.statisticshowto.com/what-is-the-pearson-correlation-coefficient/] Correlation between se ...
- Python 余弦相似度与皮尔逊相关系数 计算
夹角余弦(Cosine) 也可以叫余弦相似度. 几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异. (1)在二维空间中向量A(x1,y1)与向量B(x2,y2 ...
- 协同过滤算法中皮尔逊相关系数的计算 C++
template <class T1, class T2>double Pearson(std::vector<T1> &inst1, std::vector<T ...
- 斯皮尔曼等级相关(Spearman’s correlation coefficient for ranked data)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
随机推荐
- procemon
全记录然后筛选子进程,保存成csv 然后用程序处理 需要去掉重复的文件
- C++二分查找算法演示源码
如下内容段是关于C++二分查找算法演示的内容. #include <cstdio>{ int l = 0, r = n-1; int mid; while (l <= r){ mid ...
- Android Studio 代码无提示,无颜色区分
一.问题 ①java代码没有颜色区分,统一黑色 ②代码不会联想提示,原来打前几个字母便会联想到后面的内容 二.解决 打开File,将Power save Mode的勾勾去掉
- Python+ITchart实现微信机器人对指定的朋友和群自动回复
这里我主要用了3个机器人,可以切换. 1.图灵机器人 (傻的不行,一直在问别人问题,没有限制) http://www.tuling123.com 2.showApi上的图灵机器人 (感觉最聪明,可以 ...
- Linux 中NFS服务器的搭建
serve端IP:192.168.2.128 客户端IP:192.168.2.131 server端配置: 1.安装nfs,rpcbind,可以参考Linux 中yum的配置来安装: yum inst ...
- GitHub下载克隆clone指定的分支tag代码
需求描述: 这边有很多tag分支版本的代码,我想克隆下载指定版本到我服务器上面 例如:我想下载tag:1.4.1的代码 解决方法: 命令:git clone --branch [tags标签] [gi ...
- Unix、Windows、Mac OS、Linux系统故事
我们熟知的操作系统大概都是windows系列,近年来Apple的成功,让MacOS也逐渐走进普通用户.在服务器领域,恐怕Linux是无人不知无人不晓.他们都是操作系统,也在自己的领域里独领风骚.这都还 ...
- #020PAT 没整明白的题L1-009 N个数求和 (20 分)
后面的测试点过不去,两个错误一个超时. 目前未解决 L1-009 N个数求和 (20 分) 本题的要求很简单,就是求N个数字的和.麻烦的是,这些数字是以有理数分子/分母的形式给出的,你输出的和 ...
- MapReduce shuffle过程剖析及调优
MapReduce简介 在Hadoop MapReduce中,框架会确保reduce收到的输入数据是根据key排序过的.数据从Mapper输出到Reducer接收,是一个很复杂的过程,框架处理了所有问 ...
- android开发学习 ------- 关于getSupportFragmentManager()不可用的问题
在Android开发中,少不了Fragment的运用. 目前在实际运用中,有v-4包下支持的Fragment以及app包下的Fragment,这两个包下的FragmentManager获取方式有点区别 ...