【论文阅读】Sequence to Sequence Learning with Neural Network
Sequence to Sequence Learning with NN
《基于神经网络的序列到序列学习》原文google scholar下载。
@author: Ilya Sutskever (Google)and so on
一、总览
DNNs在许多棘手的问题处理上取得了瞩目的成绩。文中提到用一个包含2层隐藏层神经网络给n个n位数字排序的问题。如果有好的学习策略,DNN能够在监督和反向传播算法下训练出很好的参数,解决许多计算上复杂的问题。通常,DNN解决的问题是,算法上容易的而计算上困难的。DNN就是解决这个问题,将计算上看似不易解的问题通过一个设计好的多层神经网络,并按照一定的策略轻松解决。
但是,DNN有一个明显的缺陷:DNN只能处理输入、输出向量维度是定长的情形。对于输入、输出可变长的情况,使用RNN-Recurrent Neural Network更易求解。
对于一个RNN,每一个cell通常是使用LSTM。也有GRU替代,GRU精度上可能不如LSTM,但计算上更加简便,因为他是对LSTM的简化。
这篇论文的模型类似于Encoder-Decoder的模型,Encoder和Decoder的部分采用两个不同的RNN,之所以采用不同的RNN是因为可以以很少的计算代价训练更多的参数。
具体的说,这个Sequence to Sequence的学习中,首先将可变长的Sequence用一个RNN提取出特征向量—定长的,这个特征向量取自飞一个RNN的最后一个LSTM单元。
之后,把这个向量输入另一个RNN(语言模型),如条件语言模型,使用beam search计算出概率最大的句子,得到输出。
本文的创新之处在于,源串作为第一个RNN的输入,其中的每一个单词是逆向输入的。这样做得到了更高的BLEU分数。
虽然本文的模型没有超过当下最好的模型的得分,但其逆向输入的方法提供了新的思路。
二、模型
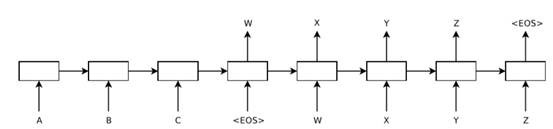
本文的模型如下:这是一个英语 –> 法语的翻译模型:
源串是CBA,得到输出WXYZ。
数据集:WMT’14 English to French dataset。
使用的词典是英文16万词,法语8万词。词向量已经训练好。未知单词采用UNK。句子结尾为EOS。
三、训练细节
- 使用的是4层LSTM单元,深层的LSTM表现的更好
- 每一层1000个LSTM,也就是说,循环1000次(因为大多数句子30词左右,其实这有点浪费)
- 初始化参数使用服从均匀分布U(-0.8,0.8)随机初始化
- 解码阶段输出层概率采用的是一个很大的softmax,这个占用了绝大多数的计算资源
- 词向量维度是1000维度的
- 学习过程中,使用随机梯度下降,学习率初始0.7,迭代7.5次,前5次固定学习率是0.7,之后每半次迭代学习率减半一次
- 使用mini-batch,每个batch是128个句子
- 为了避免梯度消失和梯度爆炸,限制梯度大小。如果梯度g的二范数||g||大于5,就进行g = 5*g/||g|| 的转换。
- 为了解决上面提到的,LSTM横向1000次是浪费的,但我们可以尽可能让同一mini-batch里的句子长度几乎相同。这样是2倍加速效果的。
- 本文的实验采用8个GPU,其中4个用来处理LSTM的每一层,其余的处理softmax层。
四、实验结果
一方面实验直接对本文的模型以及其他经典模型求BLUE比较,并且对本模型也对不同的超参数做了对比。
另一方面,与统计的机器翻译模型一起使用,通常会比直接使用RNN得分更高。这样做的结果如下:
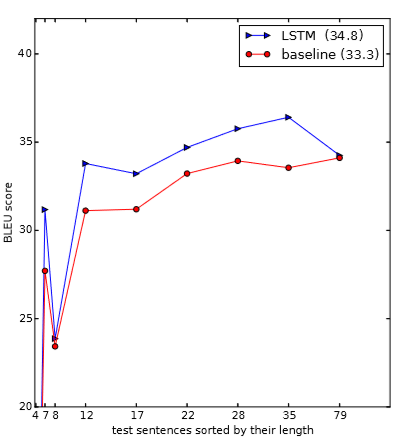
此外,实验发现,LSTM对长句子表现的更好。
实验还对针对不同句子长度的BLUE得分做了分析:
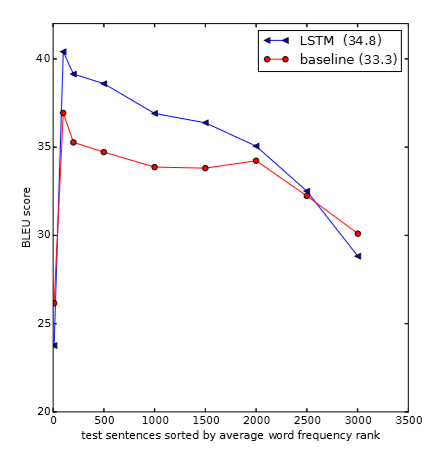
对不同句子的平均词频下的BLEU得到做了分析:


五、结论
本文得出的结论如下:
- 使用LSTM的RNN MT可以战胜传统的基于统计的MT—>STM。
- 源句子反转输入对于模型提升的帮助很大。这个没有数学解释,但一个通俗的理解是:目标句子与源句子开头的短时联系更加紧密了,在一个就翻译的初期,目标句子开头翻译质量的提升,提高了整体翻译的质量。
六、其他
还有一些人研究其他的机制。
- 编码并不采用RNN,而是使用CNN,这样编码的向量/矩阵改变了语序的问题。
- 有些人致力于将RNN结合到传统的STM中去。
- 有一种注意力机制。这种机制考虑到Encoder可能并不能完全提取源句子的所有信息,所以使用编码成向量+生成注意力向量 -> 在解码的每一步都线性组合出新的条件(源句子信息)。这样做的好处是在解码生成每一个单词的过程中,网络对源句子中不同的单词更加感兴趣,这可以提高翻译质量。
【论文阅读】Sequence to Sequence Learning with Neural Network的更多相关文章
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1
3.Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1 http://blog.csdn.net/sunbow0 ...
- 【论文笔记】Malware Detection with Deep Neural Network Using Process Behavior
[论文笔记]Malware Detection with Deep Neural Network Using Process Behavior 论文基本信息 会议: IEEE(2016 IEEE 40 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.2
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.2 http://blog.csdn.net/sunbow0 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.3
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.3 http://blog.csdn.net/sunbow0 ...
- [论文阅读笔记] Community aware random walk for network embedding
[论文阅读笔记] Community aware random walk for network embedding 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 先前许多算法都 ...
- 论文阅读 Dynamic Graph Representation Learning Via Self-Attention Networks
4 Dynamic Graph Representation Learning Via Self-Attention Networks link:https://arxiv.org/abs/1812. ...
- 通过Visualizing Representations来理解Deep Learning、Neural network、以及输入样本自身的高维空间结构
catalogue . 引言 . Neural Networks Transform Space - 神经网络内部的空间结构 . Understand the data itself by visua ...
- Python -- machine learning, neural network -- PyBrain 机器学习 神经网络
I am using pybrain on my Linuxmint 13 x86_64 PC. As what it is described: PyBrain is a modular Machi ...
- machine learning 之 Neural Network 1
整理自Andrew Ng的machine learning课程week 4. 目录: 为什么要用神经网络 神经网络的模型表示 1 神经网络的模型表示 2 实例1 实例2 多分类问题 1.为什么要用神经 ...
随机推荐
- C# 使用NPOI出现超过最大字体数和单元格格式变成一样的解决
在使用NPOI写入Excel文件的时候出现“它已经超出最多允许的字体数”,查询资料发现是字体创建太多的原因,需要将常用字体创建好,传入CellStyle中.参考(http://www.cnblogs. ...
- Vsphere 回收未消使用的磁盘空间
下载sdelete.exe 执行 sdelete.exe -z E: ,然后又恢复为原可用空间 关机 SHH进入物理主机,找到对应的虚机文件 执行vmkfstools -K test-Win200 ...
- 命令行以及Python交互模式下python程序的编写
一.命令行模式 在Windows开始菜单选择“命令提示符”,就进入到命令行模式,它的提示符类似C:\>: 二.Python交互模式 在命令行模式下敲命令python,就看到类似如下的一堆文本输出 ...
- iOS-----------进阶书籍收藏
1.编写高质量iOS与OS X代码的52个有效方法 (Effective Objective-C 2.0) 这本书介绍了一些OC的语法技巧,runtime,内存管理等方面的知识.书已买,准备入手. 2 ...
- android常犯错误记录(二)
检查 minSdkVersion什么的是不是和你依赖的包一样,它上面也有个小提示,显示本地的11,依赖的为15,那就改成15好了,重新build好了 ClassNotFoundException异常 ...
- grid++报表使用时注意事项
#开始使用:Grid++Report 可以在 Visual C#.Net 与 Visual Basic.Net 下的 WinForm 项目中使用.在项目中使用 Grid++Report 之前,首先必须 ...
- <5>Python的uwsgi web服务器
一.是什么? uWSGI是web服务器,用来部署线上web应用到生产环境.uWSGI实现了WSGI协议.uwsgi协议.http协议.WSGI(Web Server Gateway Interface ...
- nodejs 使用 js 模块
nodejs 使用 js 模块 Intro 最近需要用 nodejs 做一个爬虫,Google 有一个 Puppeteer 的项目,可以用它来做爬虫,有关 Puppeteer 的介绍网上也有很多,在这 ...
- Python第二天 变量 运算符与表达式 input()与raw_input()区别 字符编码 python转义符 字符串格式化 format函数字符串格式化 帮助
Python第二天 变量 运算符与表达式 input()与raw_input()区别 字符编码 python转义符 字符串格式化 format函数字符串格式化 帮助 目录 Pychar ...
- jQuery中toggle与slideToggle以及fadeToggle之间的不同
toggle()方法: 定义和用法 切换元素的可见状态.如果被选元素可见,则隐藏这些元素,如果被选元素隐藏,则显示这些元素. 语法: $(selector).toggle(speed,callback ...