Pandas 基础(14) - DatetimeIndex and Resample
这一小节要介绍两个内容, 一个是 DatetimeIndex 日期索引, 另一个是 Resample, 这是一个函数, 可以通过参数的设置, 来调整数据的查询条件, 从而得到不同的结果.
首先看下关于 DatetimeIndex 的内容, 照例先引入一个csv 文件作为数据基础:
import pandas as pd
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/14_ts_datetimeindex/aapl.csv')
df.head()
输出: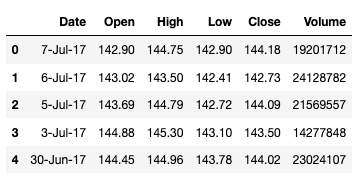
查看一下 Date 列的数据类型:
type(df.Date[0])
输出:
str
从数据结果来看, 目前的 Date 列存储的是字符串, 这显然是不适合用来做数据分析的, 需要转换成时间类型才可以:
import pandas as pd
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/14_ts_datetimeindex/aapl.csv', parse_dates=['Date'], index_col='Date')
df.head()
输出: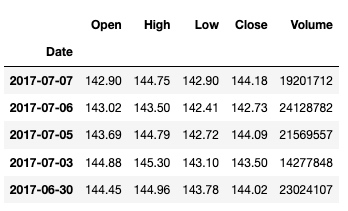
这里在引入数据的同时, 用 parse_dates 参数将 Date 列转成了 时间类型, 并把 Date 列设置为索引列, 因为我们后面的数据分析都会基于日期.
查看一下索引:
df.index
输出:
DatetimeIndex(['2017-07-07', '2017-07-06', '2017-07-05', '2017-07-03',
'2017-06-30', '2017-06-29', '2017-06-28', '2017-06-27',
'2017-06-26', '2017-06-23',
...
'2016-07-22', '2016-07-21', '2016-07-20', '2016-07-19',
'2016-07-18', '2016-07-15', '2016-07-14', '2016-07-13',
'2016-07-12', '2016-07-11'],
dtype='datetime64[ns]', name='Date', length=251, freq=None)
上面输出的最后一行有: dtype='datetime64[ns]', 证明 Date 列的数据类型已经从字符串变成了时间. 那么, 下面就尝试着根据索引来查看一些数据:
查看 2017年1月的所有数据:
df['Jan, 2017']
输出: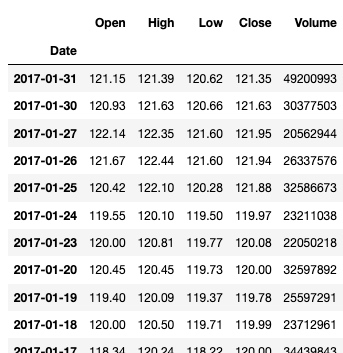
查看 2017年1月闭市数据的平均值:
df['Jan, 2017'].Close.mean()
输出:
119.57000000000001
查看具体某一天的数据:
df['2017-01-03']
输出:
查看某几天的数据:
df['2017-01-07':'2017-01-01']
输出: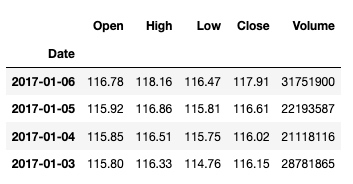
以上, 就是关于 DatetimeIndex 要跟大家分享的内容了, 总结一下, 可以看到我们只要把日期列设置为索引列, 并且保证其数据类型是时间, 就可以利用这个索引灵活地操作数据了.
下面我们来看下关于 resample() 函数的使用:
df.Close.resample('M').mean()
输出:
Date
2016-07-31 99.473333
2016-08-31 107.665217
2016-09-30 110.857143
2016-10-31 115.707143
2016-11-30 110.154286
2016-12-31 114.335714
2017-01-31 119.570000
2017-02-28 133.713684
2017-03-31 140.617826
2017-04-30 142.886842
2017-05-31 152.227727
2017-06-30 147.831364
2017-07-31 143.625000
Freq: M, Name: Close, dtype: float64
这里我们可以一步一步来看, 首先我们要获取所有的闭市数据, 在这个数据基础上又通过 resample() 函数加以加工, 函数里传的参数是 M, 就是 month 的缩写, 也就是我们要以月为单位, 也就是说要每个整月的数据, 那要每个月的什么值, 这个是必须要指定的, 否则计算机不知道是返回每个月的合计,还是最小值, 还是平均值等等, 所以后面用了 mean(), 也就是说要去平均值.
还可以将数据以图表的形式输出:
df.Close.resample('W').mean().plot()
输出: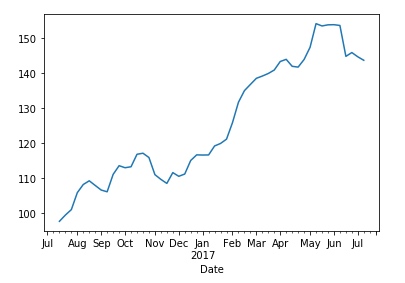
以季度为单位输出柱形图:
df.Close.resample('Q').mean().plot(kind='bar')
输出: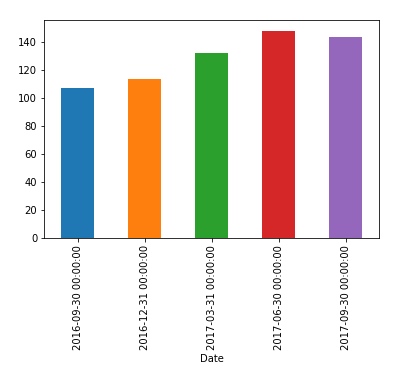
关于 resample 的具体用法, 大家还是可以按照上节课介绍的, 通过快捷键 shift+tab 查看, 它的参数有很多种, 除了我们上面介绍的 M, W, Q, 还有 D, B 等等.
以上, 有问题就给我留言吧, 希望共同进步, enjoy~~
Pandas 基础(14) - DatetimeIndex and Resample的更多相关文章
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- 数据分析02 /pandas基础
数据分析02 /pandas基础 目录 数据分析02 /pandas基础 1. pandas简介 2. Series 3. DataFrame 4. 总结: 1. pandas简介 numpy能够帮助 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- [.net 面向对象编程基础] (14) 重构
[.net 面向对象编程基础] (14) 重构 通过面向对象三大特性:封装.继承.多态的学习,可以说我们已经掌握了面向对象的核心.接下来的学习就是如何让我们的代码更优雅.更高效.更易读.更易维护.当然 ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
- Pandas 基础(1) - 初识及安装 yupyter
Hello, 大家好, 昨天说了我会再更新一个关于 Pandas 基础知识的教程, 这里就是啦......Pandas 被广泛应用于数据分析领域, 是一个很好的分析工具, 也是我们后面学习 machi ...
随机推荐
- CentOS系统/tmp目录里面的文件默认保留多久
一.CentOS系统/tmp目录里面的文件默认保留多久 CentOS6默认保留30天,CentOS7默认保留10天 一.CentOS7系统/tmp目录里面的文件默认保留多久 CentOS7默认保留10 ...
- JAVA判断是否是手机设备访问
package com.common.util; import java.util.regex.Matcher;import java.util.regex.Pattern; /** * 检测是否为移 ...
- Kali Hydra SSL issue, xHydra (GUI version of Hydra) works just fine
First find the source code. (https://is.gd/LlS5Sy) - Example search Once located you must download i ...
- Go 初体验 - 反射
首先,反射虽强大, 但不可乱用,会有性能损耗 直接上代码: 输出: 代码并不难理解,不做解释
- Unity3D 粒子系统 属性
- TCP三次握手及TCP连接状态 TCP报文首部格式
建立TCP连接时的TCP三次握手和断开TCP连接时的4次挥手整体过程如下图: 开个玩笑 ACK: TCP协议规定,只有ACK=1时有效,连接建立后所有发送的报文ACK必须为1 SYN(SYNchron ...
- java23种设计模式之: 策略模式,观察者模式
策略模式 --老司机开车,但是他今天想到路虎,明天想开奔驰...针对他不同的需求,来产生不同的应对策略 策略类是一个接口,定义了一个大概的方法,而实现具体的策略则是由实现类完成的,这样的目的是 ...
- HTTP笔记1
传输层:提供进程地址 TCP:传输控制协议,面向连接的协议:通信前需要建立虚拟链路:结束后拆除链路.端口号:0-65535 UDP:用户报文协议,无连接的协议.端口号:0-65535 IANA(互联网 ...
- 【转】Powershell与jenkins集成部署的运用(powershell运用)
powershell简介: 远程管理采用的一种新的通信协议,Web Services for Management,简称WS-MAN它通过http或者https进行工作,WS-WAN的实现主要基于一个 ...
- Jmeter之Redis读写
Jmeter之Redis读写 奔跑的小小鱼 关注 0.2 2019.03.21 18:25* 字数 1330 阅读 45评论 0喜欢 1 Jmeter插件访问Redis共有3种方式: 1)通过自已 ...