【转载】Lucene.Net无障碍学习和使用:搜索篇
在上一篇中,我们初步理解了索引的增删改查基本操作。本文着重介绍一下常用的搜索,以及搜索结果的排序和分页。本文的搜索主要是基于前一篇介绍的文本文件的索引,建议下载最后改进的demo对照着看阅读本文,同时大家可以自己动手创建一些测试文本,然后建立索引并搜索试试看。
一、初步认识搜索
先从上一篇示例代码中我们摘录一段代码看看搜索的简单实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
private TopDocs Search(string keyword,string field) { TopDocs docs = null; int n = 10;//最多返回多少个结果 SetOutput(string.Format("正在检索关键字:{0}", keyword)); try { QueryParser parser = new QueryParser(field, new StandardAnalyzer()); Query query = parser.Parse(keyword);//搜索内容 contents (用QueryParser.Parse方法实例化一个查询) Stopwatch watch = new Stopwatch(); watch.Start(); docs = searcher.Search(query, (Filter)null, n); //获取搜索结果 watch.Stop(); StringBuffer sb = "索引完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); docs = null; } return docs; } |
从上面代码,我们不难看出,搜索需要用到IndexSearcher,Query,QueryParser和TopDocs(或者Hits)四个核心类:
1、 IndexSearcher
IndexSearcher会打开索引文件,它不使用Lucene.Net的锁,可以理解为只读操作。它的Search方法是我们最常用的,该方法返回我们需要的结果。
2、QueryParser
QueryParser是Query的构造器,它的Parse方法会根据Analyzer构造一个合理的Query对象来应对搜索。
3、Query
Query类作为查询表达式的载体同样至关重要,它有丰富的子类,让我们可以应对多种变化的搜索需求,简单来说,我们想到的常用搜索Lucene.Net几乎已经都给我们实现了,你只要分辨应该使用那个类来搜索比较合理。
4、TopDocs(或者Hits)
这个类我们可以简单把它理解成它就是我们要的搜索结果集,通过它我们可以知道记录集合中的各个Document的详细信息:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
/// <summary> /// 显示搜索结果 /// </summary> /// <param name="queryResult"></param> private void ShowFileSearchResult(TopDocs queryResult) { if (queryResult == null || queryResult.totalHits == 0) { SetOutput("Sorry,没有搜索到你要的结果。"); return; } int counter = 1; foreach (ScoreDoc sd in queryResult.scoreDocs) { try { Document doc = searcher.Doc(sd.doc); string id = doc.Get("id");//获取id string fileName = doc.Get("filename");//获取文件名 string contents = doc.Get("contents");//获取文件内容 string result = string.Format("这是第{0}个搜索结果,Id为{1},文件名为:{2},文件内容为:{3}{4}", counter, id, fileName, Environment.NewLine, contents); SetOutput(result); } catch (Exception ex) { SetOutput(ex.Message); } counter++; } } |
毫无疑问,搜索结果的准确性和Query以及QueryParser密切相关,其实还和一个东西有莫大的关系,下面我会再次提到。搜索的过程就是对索引文件进行查找的过程。我们可以直白地这样理解:索引文件好比是数据库,查询表达式就像是T-SQL语句,最后通过Lucene.Net搜索引擎找到结果集。
二、几种常用的Query介绍
A、单个索引文件进行搜索举例
1、TermQuery
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
private TopDocs TermQuery(string keyword, string field){ TopDocs docs = null; int n = 10;//最多返回多少个结果 SetOutput(string.Format("正在检索关键字:{0}", keyword)); try { Term t = new Term(field, keyword); Query query = new TermQuery(t); Stopwatch watch = new Stopwatch(); watch.Start(); docs = searcher.Search(query, (Filter)null, n); watch.Stop(); StringBuffer sb = "TermQuery搜索完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); docs = null; } return docs;} |
这个Query主要用来查询关键字。我在测试TermQuery的时候,输入”jeff“是可以搜索到一条记录的,然后我输入找到的这条记录内容中的两个汉字“喜欢”,这一次却没有返回结果(当然,搜索不到也不能表示Jeff Wong还没有喜欢的人。 ^_^):
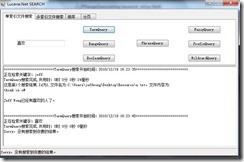
为什么呢?上面我们说搜索的准确程度和Query、QueryParser相关,根据我参考的几个文档,我怀疑第三个因素就是Analyzer(期待高人指点,下面的BooleanQuery等几个搜索,用英文“think”可以搜出结果,但用中文也搜索不到结果),这里搜索不到的原因可能就是没有指定Analyzer为StandardAnalyzer(存疑,TO DO)。
注:只要在QueryParse的Parse方法中只有一个keyword,就会自动转换成TermQuery。
2、RangeQuery
用于查询范围,看下面的示例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
private TopDocs RangeQuery( string field,string start,string end,bool isInclude) { TopDocs docs = null; int n = 10;//最多返回多少个结果 SetOutput(string.Format("正在检索,id范围为{0}~{1}", start,end)); try { Term beginT = new Term(field, start); Term endT = new Term(field, end); Query query = new RangeQuery(beginT, endT, isInclude); Stopwatch watch = new Stopwatch(); watch.Start(); docs = searcher.Search(query, (Filter)null, n); watch.Stop(); StringBuffer sb = "RangeQuery搜索完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); docs = null; } return docs; } |
取id在3和5之间的满足搜索条件的结果集。
3、BooleanQuery
这个Query也经常使用,用于搜索满足多个条件的查询:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
private TopDocs BooleanQuery(string keyword, string field) { string[] words = keyword.Trim().Split(new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries); TopDocs docs = null; int n = 10;//最多返回多少个结果 SetOutput(string.Format("正在检索关键字:{0}", keyword)); try { BooleanQuery boolQuery = new BooleanQuery(); Term beginT = new Term("id", "3"); Term endT = new Term("id", "5"); RangeQuery rq = new RangeQuery(beginT, endT, true); //rangequery id从3到5 for (int i = 0; i < words.Length; i++) { TermQuery tq = new TermQuery(new Term(field, words[i]));//termquery boolQuery.Add(tq, BooleanClause.Occur.MUST); } boolQuery.Add(rq, BooleanClause.Occur.MUST); Stopwatch watch = new Stopwatch(); watch.Start(); docs = searcher.Search(boolQuery, (Filter)null, n); watch.Stop(); StringBuffer sb = "BooleanQuery搜索完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); docs = null; } return docs; } |
希望大家注意到输入中文搜索不到结果的问题。我测试可能的几种情况都没有搜出结果。
4、PrefixQuery
PrefixQuery用于搜索是否包含某个特定前缀,常用于分类(Catalog)的检索:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
private TopDocs PrefixQuery(string keyword, string field){ TopDocs docs = null; int n = 10;//最多返回多少个结果 SetOutput(string.Format("正在检索关键字:{0}", keyword)); try { Term t = new Term(field, keyword); PrefixQuery query = new PrefixQuery(t); Stopwatch watch = new Stopwatch(); watch.Start(); docs = searcher.Search(query, (Filter)null, n); watch.Stop(); StringBuffer sb = "PrefixQuery搜索完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); docs = null; } return docs;} |
本文测试的时候,输入“ja”就可以搜到包含java和javascript两项结果了。
5、FuzzyQuery
模糊查询:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
private TopDocs FuzzyQuery(string keyword, string field) { TopDocs docs = null; int n = 10;//最多返回多少个结果 SetOutput(string.Format("正在检索关键字:{0}", keyword)); try { Term t = new Term(field, keyword); FuzzyQuery query = new FuzzyQuery(t); Stopwatch watch = new Stopwatch(); watch.Start(); docs = searcher.Search(query, (Filter)null, n); watch.Stop(); StringBuffer sb = "FuzzyQuery搜索完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); docs = null; } return docs; } |
我还从没有在项目中用过这个Query。
6、WildcardQuery
通配符搜索:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
private TopDocs WildcardQuery(string keyword, string field) { TopDocs docs = null; int n = 10;//最多返回多少个结果 SetOutput(string.Format("正在检索关键字:{0}", keyword)); try { Term t = new Term(field, keyword); WildcardQuery query = new WildcardQuery(t); Stopwatch watch = new Stopwatch(); watch.Start(); docs = searcher.Search(query, (Filter)null, n); watch.Stop(); StringBuffer sb = "WildcardQuery搜索完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); docs = null; } return docs; } |
本文示例您可以试着输入“java*”,它可以把包含java和javascript两项结果取出来。感觉这个比较好使,但是必须熟悉通配符的使用语法(看上去和正则类似)。
7、PhraseQuery
查询短语,这里面主要有一个slop的概念, 也就是各个词之间的位移偏差, 这个值会影响到结果的评分,可以通过SetSlop方法进行设定:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
private TopDocs PhraseQuery(string keyword, string field,int slop) { string[] words = keyword.Trim().Split(new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries); TopDocs docs = null; int n = 10;//最多返回多少个结果 SetOutput(string.Format("正在检索关键字:{0}", keyword)); try { PhraseQuery query = new PhraseQuery(); query.SetSlop(slop); foreach (string word in words) { Term t = new Term(field, word); query.Add(t); } Stopwatch watch = new Stopwatch(); watch.Start(); docs = searcher.Search(query, (Filter)null, n); watch.Stop(); StringBuffer sb = "PhraseQuery搜索完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); docs = null; } return docs; } |
本文示例中,输入“think javascript”,并且设置slop为1,即可命中“think in javascript”那一项。
注意,旧的参考资料上说PhraseQuery对于短语的顺序是不管的(存疑,我测试的时候输入“javascript think”,就没有匹配任何结果),这点在查询时虽然提高了命中率,却会对性能产生很大的影响。
到这里,您可能会说,哇,介绍了这么多,应该已经涵盖了大部分可能的搜索情况了吧?嘿嘿,好问题,实际上万里长征我们才走到第一步。上面的代码示例基本上都是对内容(contents)或者id进行匹配搜索,这里我还要补充一种情况,就是同一索引文件下,对多个字段进行搜索,比如下面的代码就是通过MultiFieldQueryParser实现的对id和contents同时进行搜索:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
/// <summary>/// 多字段搜索(以空格,逗号等分隔符隔开)/// </summary>/// <param name="keyword"></param>/// <returns></returns>private TopDocs MulFieldsSearch(string keyword){ TopDocs docs = null; int n = 100; SetOutput("正在检索关键字:" + keyword); try { BooleanClause.Occur[] flags=new BooleanClause.Occur[]{BooleanClause.Occur.MUST,BooleanClause.Occur.MUST}; string[] fields = new string[] { "id", "contents" }; string[] values = keyword.Trim().Split(new char[] { ' ', ',' }, StringSplitOptions.RemoveEmptyEntries); if (fields.Length != values.Length) { throw new Exception("字段和对应值不一致"); } //MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, new StandardAnalyzer()); //parser.SetDefaultOperator(QueryParser.Operator.OR);//或者的关系 //Query query = parser.Parse(keyword); Query query = MultiFieldQueryParser.Parse(values, fields, flags, new StandardAnalyzer()); Stopwatch watch = new Stopwatch(); watch.Start(); docs = searcher.Search(query, (Filter)null, n); //排序获取搜索结果 watch.Stop(); StringBuffer sb = "搜索完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); } return docs;} |
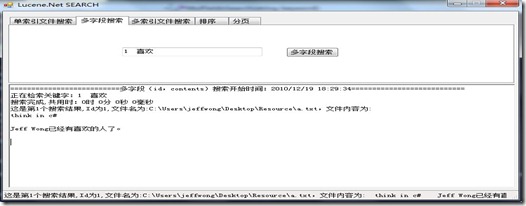
示例中,我输入“1 喜欢”,就可以把id为1,且内容保护“喜欢”的那条记录显示出来了。搜索结果如图:
注:上面介绍的这几种Query也适用于下面B中要介绍的多个索引文件搜索。
B、多个索引文件进行搜索举例
说一下我在本地的测试:索引文件index建好后,其他多余的索引文件我们就不费事了,直接把建好的索引index文件夹复制一份,命名为index1,然后就是通过MultiSearcher类进行多索引文件操作:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
/// <summary>/// 根据多个索引文件夹搜索/// </summary>/// <param name="keyword"></param>/// <returns></returns>private TopDocs MultiSearch(string keyword, string field){ TopDocs docs = null; int n = 20;//最多返回多少个结果 SetOutput(string.Format("正在检索关键字:{0}", keyword)); Searchable[] abs = new Searchable[2]; abs[0] = new IndexSearcher(INDEX_STORE_PATH); abs[1] = new IndexSearcher(INDEX_STORE_PATH1); MultiSearcher searcher = new MultiSearcher(abs);//构造MultiSearcher try { QueryParser parser = new QueryParser(field, new StandardAnalyzer()); Query query = parser.Parse(keyword); Stopwatch watch = new Stopwatch(); watch.Start(); docs = searcher.Search(query, (Filter)null, n); //排序获取搜索结果 watch.Stop(); StringBuffer sb = "搜索完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); docs = null; } return docs;}/// <summary>/// 显示搜索结果/// </summary>/// <param name="queryResult"></param>private void ShowMultFileSearchResult(TopDocs queryResult){ if (queryResult == null || queryResult.totalHits == 0) { SetOutput("Sorry,没有搜索到你要的结果。"); return; } Searchable[] abs = new Searchable[2]; abs[0] = new IndexSearcher(INDEX_STORE_PATH); abs[1] = new IndexSearcher(INDEX_STORE_PATH1); MultiSearcher searcher = new MultiSearcher(abs);//构造MultiSearcher int counter = 1; foreach (ScoreDoc sd in queryResult.scoreDocs) { try { Document doc = searcher.Doc(sd.doc); string id = doc.Get("id");//获取id string fileName = doc.Get("filename");//获取文件名 string contents = doc.Get("contents");//获取文件内容 string result = string.Format("这是第{0}个搜索结果,Id为{1},文件名为:{2},文件内容为:{3}{4}", counter, id, fileName, Environment.NewLine, contents); SetOutput(result); } catch (Exception ex) { SetOutput(ex.Message); } counter++; }} |
搜索结果不出意外,通常都是匹配两份:

三、排序
排序我们通常都需要用到Sort和SortField类,顾名思义,这两个类专门是用来排序的:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
/// <summary>/// 根据索引排序搜索/// </summary>/// <param name="keyword"></param>/// <returns></returns>private TopDocs SortSearch(string keyword, string field){ TopDocs docs = null; int n = 10;//最多返回多少个结果 SetOutput(string.Format("正在检索关键字:{0}", keyword)); try { QueryParser parser = new QueryParser(field, new StandardAnalyzer());//针对内容查询 Query query = parser.Parse(keyword);//搜索内容 contents (用QueryParser.Parse方法实例化一个查询) Stopwatch watch = new Stopwatch(); bool sortDirection = true; if (chkIsSortById.Checked == true)//按照id升序 { sortDirection = false; } watch.Start(); Sort sort = new Sort(); SortField sf = new SortField("id", SortField.INT, sortDirection);//按照id字段排序,false表示升序,ture表示逆序 //SortField sf = new SortField("filename", SortField.DOC, false);//按照filename字段排序,false表示升序 sort.SetSort(sf); //多个条件排序 //Sort sort = new Sort(); //SortField f1 = new SortField("id", SortField.INT, false); //SortField f2 = new SortField("filename", SortField.DOC, false); //sort.SetSort(new SortField[] { f1, f2 }); docs = searcher.Search(query, (Filter)null, n, sort); //排序获取搜索结果 watch.Stop(); StringBuffer sb = "搜索完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); docs = null; } return docs;} |
可以按照多个字段进行排序,据可靠消息,排序会降低搜索效率,所以通常对于数据量较频繁或者较大的搜索,通常都会采取某一些策略,先取出来再在程序中进行排序。
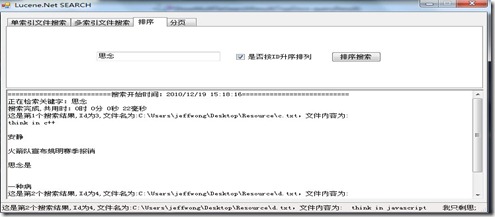
下图是简单的按照id升序的排序结果:
四、分页
本文的分页搜索主要就是利用旧文介绍的一个分页控件,根据返回的结果总数(TopDocs的totalHits),利用当前页和每页记录数进行分页,而不是像数据库分页一样,一次就取出某一页的每页记录数,严格来讲,不算Lucene.Net自身的正确的分页(Lucene.Net的另一种分页需要用到缓存),待我再看看源码研究研究,过段时间再总结一下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
|
/// <summary>/// 根据索引分页搜索/// </summary>/// <param name="keyword"></param>/// <returns></returns>private TopDocs PagerSearch(string keyword, string field){ TopDocs docs = null; int n = 10000;//最多返回多少个结果 SetOutput(string.Format("正在检索关键字:{0}", keyword)); try { QueryParser parser = new QueryParser(field, new StandardAnalyzer());//针对内容查询 Query query = parser.Parse(keyword);//搜索内容 contents (用QueryParser.Parse方法实例化一个查询) Stopwatch watch = new Stopwatch(); watch.Start(); docs = searcher.Search(query, (Filter)null, n); //排序获取搜索结果 watch.Stop(); StringBuffer sb = "搜索完成,共用时:" + watch.Elapsed.Hours + "时 " + watch.Elapsed.Minutes + "分 " + watch.Elapsed.Seconds + "秒 " + watch.Elapsed.Milliseconds + "毫秒"; SetOutput(sb); } catch (Exception ex) { SetOutput(ex.Message); docs = null; } return docs;}/// <summary>/// 显示分页搜索结果/// </summary>/// <param name="queryResult"></param>private void ShowPagerSearchResult(TopDocs queryResult,int currentPage){ if (queryResult == null || queryResult.totalHits == 0) { SetOutput("Sorry,没有搜索到你要的结果。"); return; } int counter = 1; int start = (currentPage - 1) * recordsPerPage;//开始记录 int end = currentPage * recordsPerPage;//结束记录 if (end > queryResult.totalHits) { end = queryResult.totalHits; } for (int i = start; i < end; i++) { ScoreDoc sd = queryResult.scoreDocs[i]; try { Document doc = searcher.Doc(sd.doc); string id = doc.Get("id");//获取id string fileName = doc.Get("filename");//获取文件名 string contents = doc.Get("contents");//获取文件内容 string result = string.Format("这是第{0}页第{1}个搜索结果,Id为{2},文件名为:{3},文件内容为:{4}{5}",currentPage, counter, id, fileName, Environment.NewLine, contents); SetOutput(result); } catch (Exception ex) { SetOutput(ex.Message); } counter++; }}/// <summary>/// 将搜索结果分页显示/// </summary>/// <param name="currentPage"></param>private void BindPagerResults(int currentPage){ searcher = new IndexSearcher(INDEX_STORE_PATH); //构建一个索引搜索器 TopDocs queryResult = PagerSearch(this.txtPagerKeyword.Text.Trim(), "contents");//按照内容搜索 int totalCount = queryResult.totalHits;//总记录数 ShowPagerSearchResult(queryResult,currentPage); if (totalCount > 0) { this.panelPager.Visible = true; //绑定页码相关信息 PagerControl pager = new PagerControl(currentPage, recordsPerPage, totalCount, "跳转"); pager.currentPageChanged += new EventHandler(pager_currentPageChanged);//页码变化 触发的事件 this.panelPager.Controls.Add(pager);//在Panel容器中加入分页控件 }}private void pager_currentPageChanged(object sender, EventArgs e){ PagerControl pager = sender as PagerControl; if (pager == null || string.IsNullOrEmpty(this.txtPagerKeyword.Text.Trim())) { return; } SetOutput(string.Format("==========================分页搜索开始时间:{0}===========================", DateTime.Now.ToString())); currentPage = pager.CurrentPage; BindPagerResults(currentPage);//查询数据并分页绑定} |
有图有真相:

关于分页控件,请参考拙文winform下的一个分页控件。
好了,简单常见的搜索就介绍到这里,有时间我会继续总结QueryParser的常用搜索语法和技巧以及一些复杂搜索(包括令人头疼的分组问题等等)。
最后,我想说的是,没有合理的索引数据作为搜索的前期准备,好比想要在程序员中找到漂亮体贴亭亭玉立温柔贤惠善解人意的女朋友一样,大部分工作和精力可能都是徒劳的,所以,合理创建索引的工作至关重要,在实际的开发中,按照项目需要,最大程度构造和优化您的索引吧。
改进后的demo下载:LuceneNetApp
转自:http://www.cnblogs.com/jeffwongishandsome/archive/2010/12/19/1910697.html
【转载】Lucene.Net无障碍学习和使用:搜索篇的更多相关文章
- Lucene.Net无障碍学习和使用:搜索篇
一.初步认识搜索 先从上一篇示例代码中我们摘录一段代码看看搜索的简单实现: private TopDocs Search(string keyword,string field) { TopDocs ...
- Lucene.Net无障碍学习和使用:索引篇
一.简单认识索引 Lucene.Net的应用相对比较简单.一段时间以来,我最多只是在项目中写点代码,利用一下它的类库而已,对很多名词术语不是很清晰,甚至理解 可能还有偏差.从我过去的博客你也可以看出, ...
- [转载]SharePoint 2013搜索学习笔记之搜索构架简单概述
Sharepoint搜索引擎主要由6种组件构成,他们分别是爬网组件,内容处理组件,分析处理组件,索引组件,查询处理组件,搜索管理组件.可以将这6种组件分别部署到Sharepoint场内的多个服务器上, ...
- Lucene.net入门学习
Lucene.net入门学习(结合盘古分词) Lucene简介 Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全 ...
- 使用 Apache Lucene 和 Solr 4 实现下一代搜索和分析
使用 Apache Lucene 和 Solr 4 实现下一代搜索和分析 使用搜索引擎计数构建快速.高效和可扩展的数据驱动应用程序 Apache Lucene™ 和 Solr™ 是强大的开源搜索技术, ...
- Lucene.net入门学习系列(2)
Lucene.net入门学习系列(2) Lucene.net入门学习系列(1)-分词 Lucene.net入门学习系列(2)-创建索引 Lucene.net入门学习系列(3)-全文检索 在使用Luce ...
- Lucene.net入门学习系列(1)
Lucene.net入门学习系列(1) Lucene.net入门学习系列(1)-分词 Lucene.net入门学习系列(2)-创建索引 Lucene.net入门学习系列(3)-全文检索 这几天在公 ...
- 用Lucene对文档进行索引搜索
问题 现在给出很多份文档,现在对某个搜索词感兴趣,想找到相关的文档. 简单搜索 一种简单粗暴的做法是: 1.读取每个文档:2.找到其中含有搜索词的文档:3.对找到的文档中搜索词出现的次数统计:4.根据 ...
- 利用Lucene.net搜索引擎进行多条件搜索的做法
利用Lucene.net搜索引擎进行多条件搜索的做法 2018年01月09日 ⁄ 搜索技术 ⁄ 共 613字 ⁄ 字号 小 中 大 ⁄ 评论关闭 利用Lucene.net搜索引擎进行多条件搜索的做法 ...
随机推荐
- 源代码版本管理与项目管理软件的认识与github的注册
源代码版本管理软件: 主要有:svn,cvs,hg,git,VSS 这些工具主要是一种记录代码更改历史, 可以无限回溯, 用于代码管理,多个程序员开发协作的工具.Perforce,StarTeam)- ...
- JavaScript 常用功能总结
小编吐血整理加上翻译,太辛苦了~求赞! 本文主要总结了JavaScript 常用功能总结,如一些常用的JS 对象,基本数据结构,功能函数等,还有一些常用的设计模式. 目录: 众所周知,JavaScri ...
- mysql C API的使用
<MySQL++简介>介绍了如何使用C++来访问mysql,本文记录下使用C API访问mysql,mysql++就是对本文介绍的C-API的封装. 常用函数(名字就能告诉我们用法): M ...
- CSS的样式表基本概念
一.样式表分类 1.内联样式表 <p style="fint-size:24px;">直接在标签内部进行样式设置</style> 2.内嵌样式表 <h ...
- 爱上MVC~MVC4模型验证可以放在前端
回到目录 MVC4.0推出后,在模型验证上有了一个新的改近,它支持前端验证,即在用户POST之前,如果验证失败,则Action(POST方式的)不会被执行,而直接停留在原视图,这对于用户体验是好的,它 ...
- 锋利的JQuery —— 事件和动画
大图猛戳
- 带你走近AngularJS - 创建自定义指令
带你走近AngularJS系列: 带你走近AngularJS - 基本功能介绍 带你走近AngularJS - 体验指令实例 带你走近AngularJS - 创建自定义指令 ------------- ...
- flow.ci Beta 上线,将开发工作流自动化
说起未来,我们会想到自动.智能.机器人...,希望可以从眼前重复繁琐的事情中解放出来,让"机器人"自动智能地帮我们做更多的事情:希望开发可以更自动化.智能化.社会化,更少的资源浪费 ...
- iOS开发——高级技术&广告服务
广告服务 上 面也提到做iOS开发另一收益来源就是广告,在iOS上有很多广告服务可以集成,使用比较多的就是苹果的iAd.谷歌的Admob,下面简单演示一下如何 使用iAd来集成广告.使用iAd集成广告 ...
- 快速入门系列--CLR--01基本概念
在.NET平台用C#这么久,自然会发现其版本很多,相应的概念也会很多,常常都是萌萌哒.而在实际工作中经常会遇到需要配置dll版本号,公钥token等场景,因而对C#.NET.CLR.框架类型等基础概念 ...