SparkSQL程序设计
1、创建Spark Session
val spark = SparkSession.builder
. master("local")
.appName("spark session example")
.getOrCreate()
注:下面的 spark 都指的是 sparkSession
2、将RDD隐式转换为DataFrame
import spark.implicits._
spark中包含 sparkContext和 sqlContext两个对象
sparkContext 是操作 RDD 的
sqlContext 是操作 sql 的
4、将数据源转换为 DataSet/DataFrame
1、RDD
通过反射
通过自定义 schema 方式
2、通过使用 SparkSql 内置数据源直接读取 JSON、parquet、jdbc、orc、csv、text 文件,创建 DS/DF
hive 里用 orc 多
impla 里用 parquet 多
5、对4反射方式进行解释
同时,红色字体处表示 import spark.implicits._ 排上用场

6、对4中通过自定义 schema 方式显式的注入 schema 来生产 DF
这个 schema 由StructType 构成,StructType 由StructFiledName,StructType,是否为空,这三部分组成
mode(SaveMode.override) 指的是,将数据写成文件时,如果存在这个目录,则覆盖掉

7、对4中,直接从数据源读取数据,转换成 DF 进行解释
这些数据源,内部本身就包含了数据的 schema,所以可以直接读取文件成一个 DF
2是1的简写,区别是,如果是内部数据源,用2,如果是外部数据源,用1
3是直接通过 sql 的方式去创建成表,然后通过 select 的方式去查找,然而编程的时候不是用这样的写法,由其他 sql 写法
json 和 parquet 两者方式一样

8、读取 JDBC 数据,产生 DF

9、通过读取 text 来生成 DF
注意1与2的不同!

10、引用外部数据源的方法
去下面网址,进入 DataSource,查找外部数据源的使用
spark-packages.org
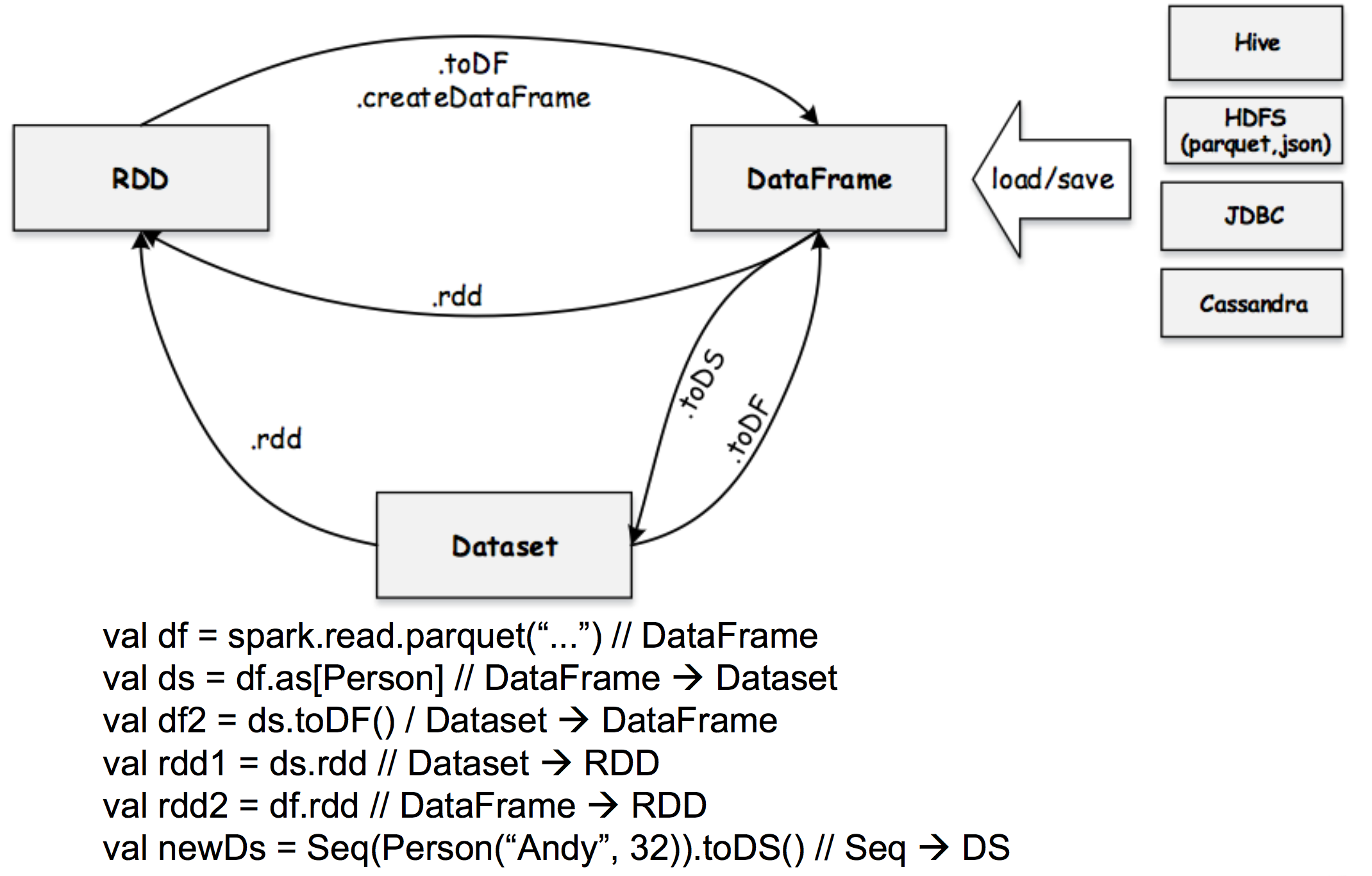
11、RDD、DF、DS 之间的关系
首先从 DataSource 那里获取数据,生成 DF,
DF 通过.rdd 生成 RDD
DF 通过.toDS 或者 .as 生成 DS
DF和 DS 都可以转换成 RDD ,需要注意的是从 DF 转换成 RDD 格式是 Row 对象,并不是它原始对象,DS 转换成 RDD 格式可以是原始的对象
还可以把一个 Scala 集合转化成 DS,跟把 Scala 集合转化成 RDD 一样
图有点老,在 spark2.1中,RDD.toDS 方法已经有了
12、加载文件
1:
scala> val usersRdd=sc.textFile("/Users/orco/data/ml-1m/users.dat")
usersRdd: org.apache.spark.rdd.RDD[String] = /Users/orco/data/ml-1m/users.dat MapPartitionsRDD[1] at textFile at <console>:24 2:
//json、orc、parquet、csv 读取方式一样,下面举例两个
scala> val userJsonDF=spark.read.format("json").load("/tmp/user.json")
userJsonDF: org.apache.spark.sql.DataFrame = [age: bigint, gender: string ... 3 more fields] //该读取方式是上面方式的简写,内部数据用下面的,外部数据用上面的
scala> val userParquetDF=spark.read.parquet("/tmp/user.parquet")
userParquetDF: org.apache.spark.sql.DataFrame = [userID: bigint, gender: string ... 3 more fields] 3:
//spark.read.text 返回 DataFrame
scala> val rdd = spark.read.text("/Users/orco/data/ml-1m/users.dat")
rdd: org.apache.spark.sql.DataFrame = [value: string] //spark.read.textFile 返回 DataSet
scala> val rdd = spark.read.textFile("/Users/orco/data/ml-1m/users.dat")
rdd: org.apache.spark.sql.Dataset[String] = [value: string]
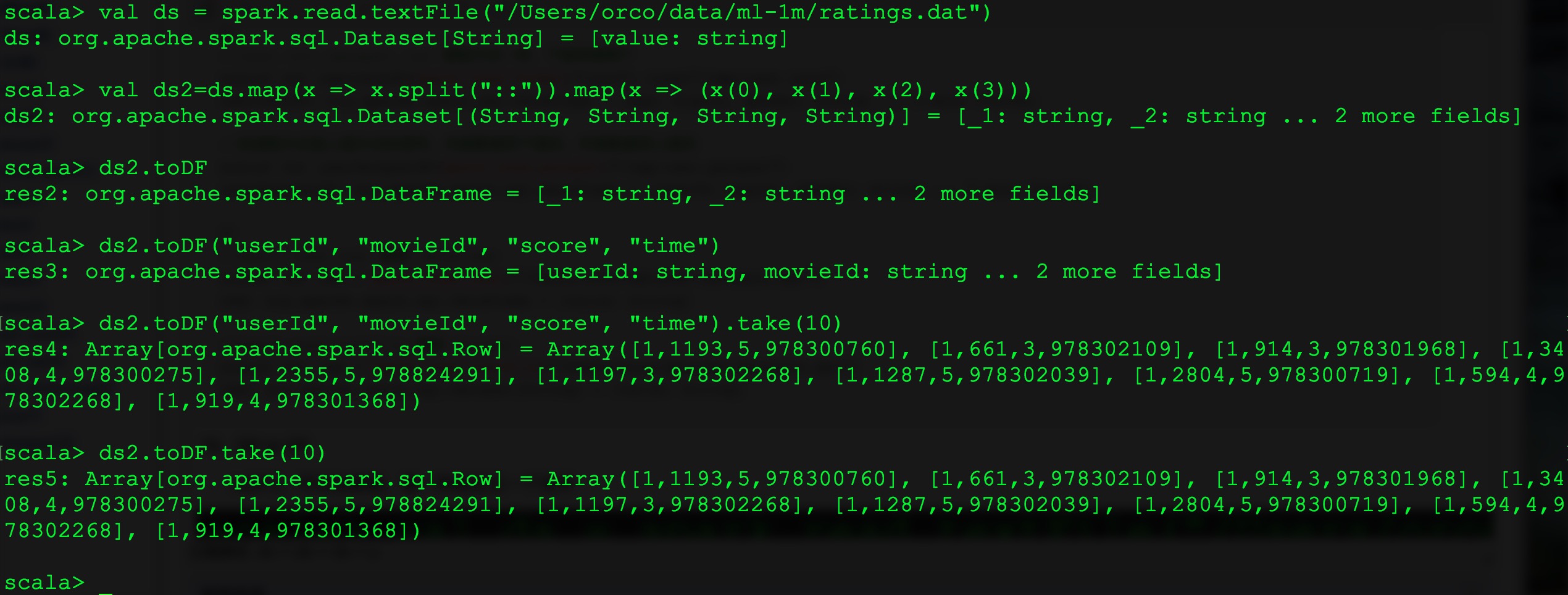
13、DS to DF
toDF(),可以加参数,每一列给定义一个名字
14、练习
1. json 数据
{"age":"45","gender":"M","occupation":"7","userID":"4","zipcode":"02460"}{"age":"1","gend
er":"F","occupation":"10","userID":"1","zipcode":"48067"}
2. 读取数据
scala> val userDF = spark.read.json("/tmp/user.json")
userDF: org.apache.spark.sql.DataFrame = [age: string, gender: string, occupation: string, userID: string, zipcode: string]
3. 生成Json数据
scala> userDF.limit(5).write.mode("overwrite").json("/tmp/user2.json")
4. 查看数据
scala> userDF.show(4)
或者(DF.toJSON 生成一个 DS)
scala> userDF.limit(2).toJSON.foreach(x =>println(x))
{"age":"1","gender":"F","occupation":"10","userID":"1","zipcode":"48067"} {"age":"56","gender":"M","occupation":"16","userID":"2","zipcode":"70072"}
或者
scala> userDF.printSchema
root
|-- age: string (nullable = true)
|-- gender: string (nullable = true)
|-- occupation: string (nullable = true) |-- userID: string (nullable = true)
|-- zipcode: string (nullable = true)
5. 修改 DF/DS 元信息
userDF.toDF("a","b","c","d","e")
userDS.toDF("a","b","c","d","e")
或者
val userDs = spark.read.textFile("ml-1m/users.dat").map(_.split("::"))
val userDf = userDs.map(x => (x(0).toLong, x(1).toString, x(2).toInt, x(3).toInt, x(4))).toDF("userId", "gender", "age", "occ", "timestamp")
或者
//增加新列“age2”
userDf.withColumn(”age2",col(”age")+1)
6. Action 算子,如 collect、first、take、head 等
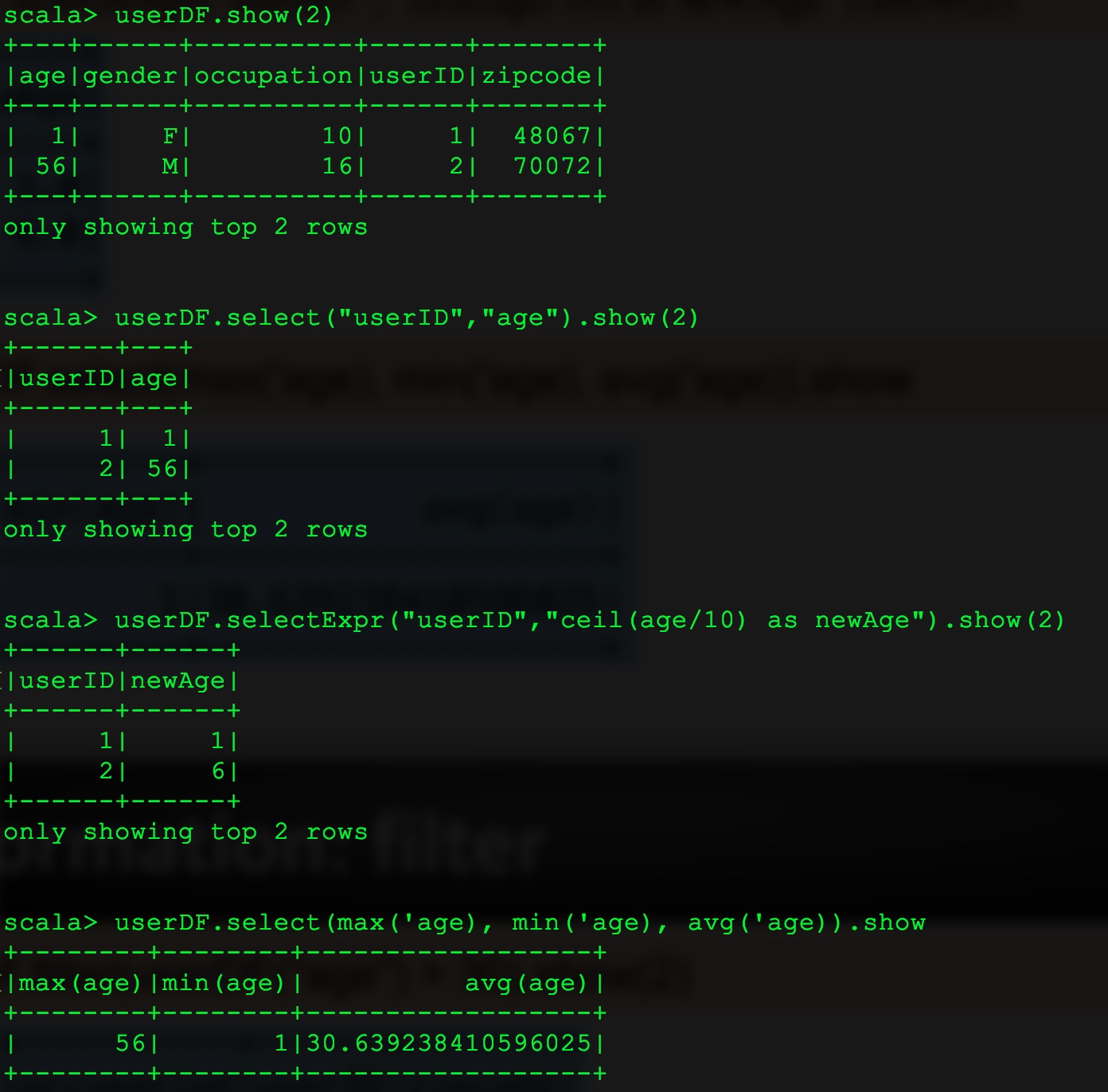
15、单独列举出来,select 算子
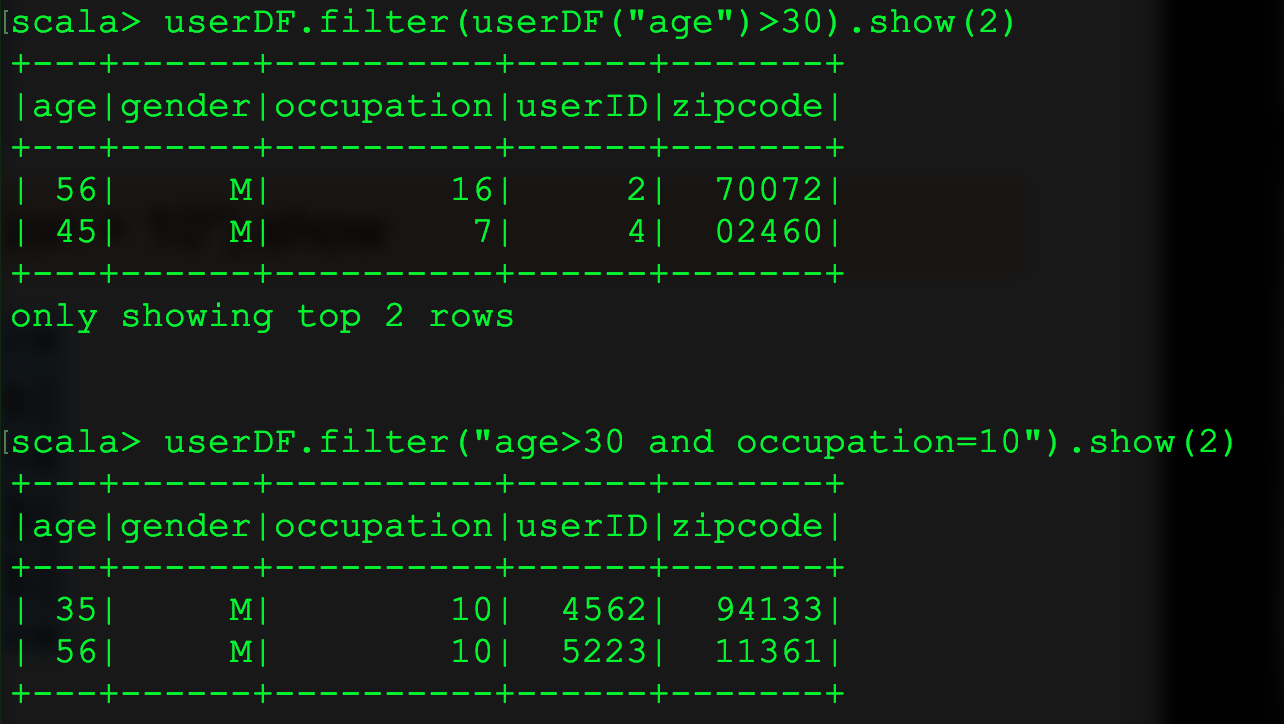
16、filter 的两种使用
17、混用 select filter,无先后顺序
userDF.select("userID", "age").filter("age > 30").show(2)
userDF.filter("age > 30").select("userID", "age").show(2)
18、groupBy
scala> userDF.groupBy("age").count().show()
+---+-----+
|age|count|
+---+-----+
| 50| 496|
| 25| 2096|
| 56| 380|
| 1| 222|
| 35| 1193|
| 18| 1103|
| 45| 550|
+---+-----+
scala> userDF.groupBy("age").agg(count("gender")).show()
+---+-------------+
|age|count(gender)|
+---+-------------+
| 50| 496|
| 25| 2096|
| 56| 380|
| 1| 222|
| 35| 1193|
| 18| 1103|
| 45| 550|
+---+-------------+
scala> userDF.groupBy("age").agg(countDistinct("gender")).show()
+---+----------------------+
|age|count(DISTINCT gender)|
+---+----------------------+
| 50| 2|
| 25| 2|
| 56| 2|
| 1| 2|
| 35| 2|
| 18| 2|
| 45| 2|
+---+----------------------+
scala>
19、groupBy,agg 另一种写法
可用的聚集函数:
`avg`, `max`, `min`, `sum`, `count`
scala> userDF.groupBy("age").agg("gender"->"count","occupation"->"count").show()
+---+-------------+-----------------+
|age|count(gender)|count(occupation)|
+---+-------------+-----------------+
| 50| 496| 496|
| 25| 2096| 2096|
| 56| 380| 380|
| 1| 222| 222|
| 35| 1193| 1193|
| 18| 1103| 1103|
| 45| 550| 550|
+---+-------------+-----------------+
20、join

当 join 的列名不一样的时候用下面的方式,同时可以指定连接方式,如 inner

21、DF 创建临时表
不论是临时表还是全局表,application 关闭后,都会删除,如果想一直有效,那就用 saveAsTable 的方式存起来
userDataFrame.createOrReplaceTempView("users")
val groupedUsers = spark.sql("select gender, age, count(*) as n from users group by gender, age")
groupedUsers.show()

22、SparkSQL 的万能思路
第一步:得到DataFrame或Dataset
val ds = ...
第二步:注册成临时表
ds.registerTempTable("xxx")
第三步:用SQL计算
spark.sql ("SELECT ...")
SparkSQL程序设计的更多相关文章
- SparkSQL(一)
一.概述 组件 运行机制 转 SparkSQL – 从0到1认识Catalyst https://blog.csdn.net/qq_36421826/article/details/81988157 ...
- HTML5 程序设计 - 使用HTML5 Canvas API
请你跟着本篇示例代码实现每个示例,30分钟后,你会高喊:“HTML5 Canvas?!在哥面前,那都不是事儿!” 呵呵.不要被滚动条吓到,很多都是代码和图片.我没有分开写,不过上面给大家提供了目录,方 ...
- 解析大型.NET ERP系统 单据标准(新增,修改,删除,复制,打印)功能程序设计
ERP系统的单据具备标准的功能,这里的单据可翻译为Bill,Document,Entry,具备相似的工具条操作界面.通过设计可复用的基类,子类只需要继承基类窗体即可完成单据功能的程序设计.先看标准的销 ...
- java基础学习03(java基础程序设计)
java基础程序设计 一.完成的目标 1. 掌握java中的数据类型划分 2. 8种基本数据类型的使用及数据类型转换 3. 位运算.运算符.表达式 4. 判断.循环语句的使用 5. break和con ...
- CWMP开源代码研究5——CWMP程序设计思想
声明:本文涉及的开源程序代码学习和研究,严禁用于商业目的. 如有任何问题,欢迎和我交流.(企鹅号:408797506) 本文介绍自己用过的ACS,其中包括开源版(提供下载包)和商业版(仅提供安装包下载 ...
- 《JavaScript高级程序设计(第3版)》笔记-序
很少看书,不喜欢看书,主要是上学时总坐不住,没有多大定性,一本书可以两天看完,随便翻翻,也可以丢在角落里几个月不去动一下. 上次碰到了<JavaScript高级程序设计(第3版)>感觉真的 ...
- 《JavaScript高级程序设计(第3版)》阅读总结记录第一章之JavaScript简介
前言: 为什么会想到把<JavaScript 高级程序设计(第 3 版)>总结记录呢,之前写过一篇博客,研究的轮播效果,后来又去看了<JavaScript 高级程序设计(第3版)&g ...
- 【实战Java高并发程序设计 7】让线程之间互相帮助--SynchronousQueue的实现
[实战Java高并发程序设计 1]Java中的指针:Unsafe类 [实战Java高并发程序设计 2]无锁的对象引用:AtomicReference [实战Java高并发程序设计 3]带有时间戳的对象 ...
- 【实战Java高并发程序设计6】挑战无锁算法:无锁的Vector实现
[实战Java高并发程序设计 1]Java中的指针:Unsafe类 [实战Java高并发程序设计 2]无锁的对象引用:AtomicReference [实战Java高并发程序设计 3]带有时间戳的对象 ...
随机推荐
- js实现二分搜索法
二分搜索法: 也称折半搜索,是一种在有序数组中查找特定元素的搜索算法. 实现步骤: 1. 首先从数组中间开始查找对比,若相等则找到,直接返回中间元素的索引. 2. 若查找值小于中间值,则在小于中间值的 ...
- Math函数
floor --将一个小数向下舍入为整数 float floor ( float $value ) 注意:floor返回的虽然是取整的数字 但是类型仍然是float类型. 实例: echo floor ...
- maven + hessian 简单样例
项目结构例如以下: pom.xml 内容: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=&quo ...
- win10 设置C盘访问权限
“以管理员身份运行” cmd.exe C:\Windows\system32>icacls "C:\Program Files\Epic Games" /setintegri ...
- Android测试:从零开始2——local单元测试
上一篇分析了android项目的测试分类,这一篇讲local单元测试. 参考android官方文档. 测试前需要配置测试环境,新建项目后,目录下会出现app/src/test/java/文件夹,这个文 ...
- QQ空间的文艺打开方法
QQ空间被限制?打不开? 看看这里 第一种:http://user.qzone.qq.com/627911903 第二种:http://627911903.qzone.qq.com 第三种:http: ...
- HTML5跨平台开发环境配置
http://hi.baidu.com/kuntakinte/item/1bbd3759b4901a3695eb050c
- 服务器端Session和客户端Session(和Cookie区别)2
https://blog.csdn.net/java_faep/article/details/78082802 我们可以得出如下结论: 关闭浏览器,只会是浏览器端内存里的session cookie ...
- python中的itertools
在量化数据处理中,经常使用itertools来完成数据的各种排列组合以寻找最优参数 import itertools #1. permutations: 考虑顺序组合元素 items = [1, 2, ...
- K线数据库表结构
-- -- 数据库: `bittrex` -- -- -------------------------------------------------------- -- -- 表的结构 `ltc` ...