利用python进行数据分析之绘图和可视化
matplotlib API入门
使用matplotlib的办法最常用的方式是pylab的ipython,pylab模式还会向ipython引入一大堆模块和函数提供一种更接近与matlab的界面,matplotlib API函数位于matplotlib.pyplot模块中,其通常的引入约定是:import matplot.pyplot as plt
1、Figure和Subplot
matplotlib的图像都位于Figure对象中,你可以用plt.figure创建一个新的Figure,不能通过空Figure绘图,必须用add_subplot创建一个或多个sub_plot才行
>>> import matplotlib.pyplot as plt
>>> fig=plt.figure()
>>> ax1=fig.add_subplot(2,2,1)
>>> ax2=fig.add_subplot(2,2,2)
你可以在matplotlib的文档中找到各种图表类型,由于根据特定布局创建Figure和subplot是一件常见的任务,于是便出现一个更为方便的方法:plt.subplots,它可以创建一个新的Figure,且返回一个含有已创建的subplot对象的numpy数组。
pandas中的绘图函数
1、线型图
Series和DataFrame都有一个用于生成各类图标的plot方法,默认情况下,他们所生成的是线型图,该Series的索引会被传给matplotlib,并用于绘制x轴
>>> from pandas import *
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> s=Series(np.random.randn(10).cumsum(),index=np.arange(0,100,10))
>>> s.plot()
>>> plt.show(s.plot())
DataFrame的plot方法会在一个subplot中为各列绘制一条直线,并自动创建图例:
>>> df=DataFrame(np.random.randn(10,4).cumsum(0),columns=['A','B','C','D'],index=np.arange(0,100,10))
>>> plt.show(df.plot())
2、柱状图
在生成的线型图的代码中加上kind='bar'(垂直树状图)或 kind='barch'(水平柱状图)即可生成柱状图,此时,Series和DataFrame的索引将会被用作X或Y的刻度。
data=Series(np.random.rand(16),index=list('abcdefghijklmnop'))
>>> data.plot(kind='bar',ax=axes[0],color='k',alpha=0.7)
<matplotlib.axes._subplots.AxesSubplot object at 0x06FA9FD0>
>>> data.plot(kind='bar',ax=axes[1],color='k',alpha=0.7)
<matplotlib.axes._subplots.AxesSubplot object at 0x049D02D0>
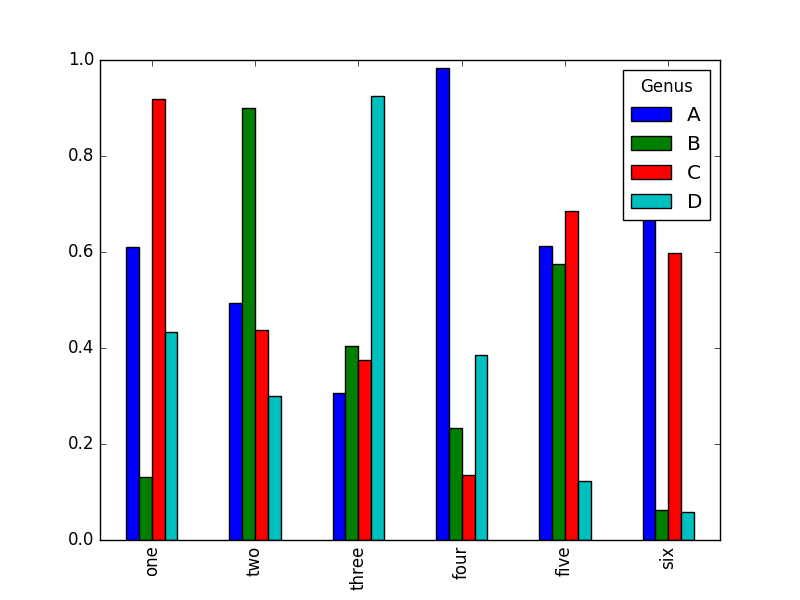
对于DataFrame,柱状图会将每一行的值分为一组
>>> df=DataFrame(np.random.rand(6,4),index=['one','two','three','four','five','six'],columns=['A','B','C','D'])
>>> df.columns.name='Genus'
>>> df
Genus A B C D
one 0.610197 0.132144 0.919492 0.432829
two 0.493323 0.899049 0.438195 0.300159
three 0.305448 0.404252 0.374776 0.924542
four 0.982561 0.233063 0.135196 0.385672
five 0.613274 0.574884 0.684504 0.123448
six 0.791576 0.062249 0.597673 0.058899
>>> plt.show(df.plot(kind='bar'))
3、直方图和密度图
直方图是一种可以对值频率进行离散化显示的柱状图,另一种是密度图,它是通过计算可能会产生观测数据的连续概率分布的估计而产生的。一般过程是将该分布近似为一组核分布,因此,密度图也被称作KDE图,调用plt时加上kind='kde'即可生成一张密度图。
4、散布图
散布图是观察两个一维数据序列之间的关系的有效手段,matplotlib的scatter方法是绘制散布图的主要方法。
>>> from pandas import *
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> macro=read_csv(r'D:\书籍与代码资料\利用python进行数据分析代码和数据集\ch08\macrodata.csv')
>>> data=macro[['cpi','m1','tbilrate','unemp']]
>>> trans_data=np.log(data).diff().dropna()
>>> trans_data[-5:]
cpi m1 tbilrate unemp
198 -0.007904 0.045361 -0.396881 0.105361
199 -0.021979 0.066753 -2.277267 0.139762
200 0.002340 0.010286 0.606136 0.160343
201 0.008419 0.037461 -0.200671 0.127339
202 0.008894 0.012202 -0.405465 0.042560
>>> plt.scatter(trans_data['m1'],trans_data['unemp'])
<matplotlib.collections.PathCollection object at 0x0525C6D0>
>>> plt.show()

在探索式的数据分析中,同时观察一组变量的散布图是很有意义的,这也被称为散布矩阵;pandas提供了一个能从DataFrame创建散布图矩阵的scatter_matrix函数。
Python图形化工具生态系统介绍
Chaco:适合用复杂的图形化方法表达数据的内部关系,对交互支持较多与适合
mayayi:基于C++图形库的图形工具包
利用python进行数据分析之绘图和可视化的更多相关文章
- 利用Python进行数据分析_Pandas_绘图和可视化_Matplotlib
1 认识Figure和Subplot import matplotlib.pyplot as plt matplotlib的图像都位于Figure对象中 fg = plt.figure() 通过add ...
- 绘图和可视化知识图谱-《利用Python进行数据分析》
所有内容整理自<利用Python进行数据分析>,使用MindMaster Pro 7.3制作,emmx格式,源文件已经上传Github,需要的同学转左上角自行下载或者右击保存图片. 其他章 ...
- 《利用Python进行数据分析·第2版》
<利用Python进行数据分析·第2版> 第 1 章 准备工作第 2 章 Python 语法基础,IPython 和 Jupyter第 3 章 Python 的数据结构.函数和文件第 4 ...
- 利用Python进行数据分析——重要的Python库介绍
利用Python进行数据分析--重要的Python库介绍 一.NumPy 用于数组执行元素级计算及直接对数组执行数学运算 线性代数运算.傅里叶运算.随机数的生成 用于C/C++等代码的集成 二.pan ...
- PYTHON学习(三)之利用python进行数据分析(1)---准备工作
学习一门语言就是不断实践,python是目前用于数据分析最流行的语言,我最近买了本书<利用python进行数据分析>(Wes McKinney著),还去图书馆借了本<Python数据 ...
- 利用python进行数据分析——(一)库的学习
总结一下自己对python常用包:Numpy,Pandas,Matplotlib,Scipy,Scikit-learn 一. Numpy: 标准安装的Python中用列表(list)保存一组值,可以用 ...
- $《利用Python进行数据分析》学习笔记系列——IPython
本文主要介绍IPython这样一个交互工具的基本用法. 1. 简介 IPython是<利用Python进行数据分析>一书中主要用到的Python开发环境,简单来说是对原生python交互环 ...
- 利用python进行数据分析--(阅读笔记一)
以此记录阅读和学习<利用Python进行数据分析>这本书中的觉得重要的点! 第一章:准备工作 1.一组新闻文章可以被处理为一张词频表,这张词频表可以用于情感分析. 2.大多数软件是由两部分 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
随机推荐
- codefirst初尝试
Code First 约定 借助 CodeFirst,可通过使用 C# 或Visual Basic .NET 类来描述模型.模型的基本形状可通过约定来检测.约定是规则集,用于在使用 Code Firs ...
- Jade 报错
今天写jade的时候遇到一个问题 Invalid indentation,you can use tabs or spaces but not both问题 经过查证原来是 在jade模板中 同时存在 ...
- BZOJ 1176: [Balkan2007]Mokia( CDQ分治 + 树状数组 )
考虑cdq分治, 对于[l, r)递归[l, m), [m, r); 然后计算[l, m)的操作对[m, r)中询问的影响就可以了. 具体就是差分答案+排序+离散化然后树状数组维护.操作数为M的话时间 ...
- mysql innodb init function error
150414 16:23:07 [ERROR] Plugin 'InnoDB' init function returned error. 150414 16:23:07 [ERROR] Plugin ...
- poj 1321 棋盘问题 递归运算
棋盘问题 Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 19935 Accepted: 9933 Description ...
- springmvc的ModelAndView的简单使用
参考:http://blog.csdn.net/zzjjiandan/article/details/34089313 先上图: MAVTest.java package com.wyl; impor ...
- ios 加水印
1.加文字 -(UIImage *)addText:(UIImage *)img text:(NSString *)text1 { //get image width and ...
- [C语言练习]学生学籍管理系统
/** * @copyright 2012 Chunhui Wang * * wangchunhui@wangchunhui.cn * * 学生学籍管理系统(12.06) */ #include &l ...
- opencv-python 学习笔记1:简单的图片处理
一.主要函数 1. cv2.imread():读入图片,共两个参数,第一个参数为要读入的图片文件名,第二个参数为如何读取图片,包括cv2.IMREAD_COLOR:读入一副彩色图片:cv2.IMREA ...
- POJ 3061 Subsequence(Two Pointers)
[题目链接] http://poj.org/problem?id=3061 [题目大意] 给出S和一个长度为n的数列,问最短大于等于S的子区间的长度. [题解] 利用双指针获取每一个恰好大于等于S的子 ...