python+scrapy 爬取西刺代理ip(一)
转自:https://www.cnblogs.com/lyc642983907/p/10739577.html
第一步:环境搭建
1.python2 或 python3

2.用pip安装下载scrapy框架
具体就自行百度了,主要内容不是在这。
第二步:创建scrapy(简单介绍)
1.Creating a project(创建项目)
scrapy startproject 项目名称
2.Defining our item(定义我们的项目)
3.writing a spider(写spider)
scrapy genspider (spider的名称)(爬取的网页)
4.writing & Configure an item Pipeline(编写和配置项目管道)
5.Execute crawl(执行爬虫)
scrapy crawl (spider的名称)
第三步:具体实现
1.创建项目
进入scrapy项目的工作区间(xici项目名)
scrapy startproject xici
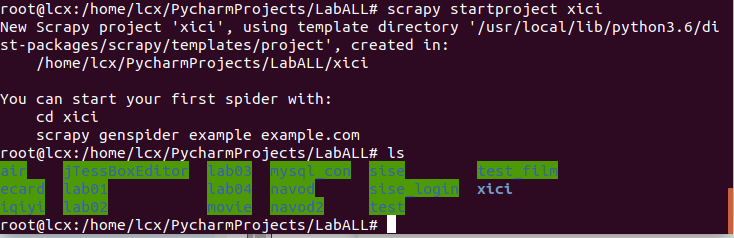
此时项目结构是这样
2.创建spider爬虫
进入项目创建(注意后面的不是具体地址,是域名)
scrapy genspider xicidaili 'xicidaili.com'

此时,你会发现在spiders文件夹下多了个 xicidaili.py 文件(这就是爬虫文件)

3.编写items.py
根据我们的需求编写
代理ip最主要是ip、端口和类型(http或https)
items.py

# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class XiciItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
ip = scrapy.Field()
port = scrapy.Field()
types = scrapy.Field()
4.编写xicidaili.py
具体爬虫操作就在这个文件里实现
xicidaili.py
# -*- coding: utf-8 -*-
import scrapy
from xici.items import XiciItem class XicidailiSpider(scrapy.Spider):
name = 'xicidaili'
allowed_domains = ['xicidaili.com']
#把http://xicidaili.com/地址改为我们需要爬去的具体地址
start_urls = ['https://www.xicidaili.com/nn/'] def parse(self, response):
#我们发现ip都是在table标签里,那我们就用xpath选择table元素
lis = response.xpath('//table[@id="ip_list"]')
#抓取table下的tr,一个tr就一个ip,端口,类型
trs = lis[0].xpath('tr') items = []
#除掉第一行
for ip in trs[1:]:
item = XiciItem()
#抓取每一行具体的内容
# //*[@id="ip_list"]/tbody/tr[2]/td[2]
item["ip"] = ip.xpath('td[2]/text()')[0].extract() # //*[@id="ip_list"]/tbody/tr[2]/td[3]
item["port"] = ip.xpath('td[3]/text()')[0].extract() # //*[@id="ip_list"]/tbody/tr[2]/td[6]
item["types"] = ip.xpath('td[6]/text()').extract() #加入到数组
items.append(item)
#返回给items.py
return items
5.编写pipelines.py
pipelines文件是对数据进行持久化存储的
MySQLdb不支持python3,所以我要用pymysql代替
没有pymysql需要用pip下载,数据库表也要自己建
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql class XiciPipeline(object):
def __init__(self):
self.client = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root', # 使用自己的用户名
passwd='root', # 使用自己的密码
db='test', # 数据库名
charset='utf8'
)
# 拿到游标
self.cur = self.client.cursor() def process_item(self, item, spider):
#mysql防止sql注入
sql = ("insert into proxyip(ip,port,types) values (%s,%s,%s)")
lis = (item['ip'], item['port'], item['types'])
try: self.cur.execute(sql, lis)
# 向数据库提交
self.client.commit()
except Exception as e:
print("Insert error:", e)
#关闭
self.cur.close()
return item
6.编写middlewares.py
middlewares.py中设置用户代理中间件
对爬虫进行伪装,伪装成人工操作,否则网站会监测出你是爬虫,并拦截你
在middlewares.py文件中加入以下代码:
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random #设置代理ip
class MyProxyMiddleware(object):
'''
设置Proxy
''' def __init__(self, ip):
self.ip = ip @classmethod
def from_crawler(cls, crawler):
return cls(ip=crawler.settings.get('PROXIES')) def process_request(self, request, spider):
ip = random.choice(self.ip)
request.meta['proxy'] = ip class MyUserAgentMiddleware(UserAgentMiddleware):
'''
设置User-Agent
''' def __init__(self, user_agent):
self.user_agent = user_agent @classmethod
def from_crawler(cls, crawler): return cls(
user_agent=crawler.settings.get('USER_AGENTS_LIST')
) def process_request(self, request, spider):
agent = random.choice(self.user_agent)
request.headers['User-Agent'] = agent
7.编写settings.py
我们刚才编写的middlewares.py和pipelines.py都要在settings.py文件里面进行配置,设置优先级等等。
(一定要记得,否则你写的数据持久化存储和爬虫伪装是没有生效的,记得把ROBOTSTXT_OBEY改为False)
修改settings.py文件代码如下:
BOT_NAME = 'xici' SPIDER_MODULES = ['xici.spiders']
NEWSPIDER_MODULE = 'xici.spiders' #对middlewares编写的进行配置
DOWNLOADER_MIDDLEWARES = {
'xici.middlewares.MyProxyMiddleware': 543,
'scrapy.downloadermiddleware.useragent.UserAgentMiddleware': None,
'xici.middlewares.MyUserAgentMiddleware': 400,
} #配置pipelines.py
ITEM_PIPELINES = {
'xici.pipelines.XiciPipeline': 300
} #代理的ip
#你看到此篇文章的时候,ip已经没用了,你可以在西刺网站上拿一个试
PROXIES = ['http://192.168.42.249:808'] #user_agent
USER_AGENTS_LIST = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
] # Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'xici (+http://www.yourdomain.com)' #要设置ROBOTSTXT_OBEY改为False
#如果为True,则遵守robots协议(爬虫协议) ROBOTSTXT_OBEY = False
8.执行爬虫
进入项目里面,列出爬虫
scrapy list

scrapy crawl xicidaili
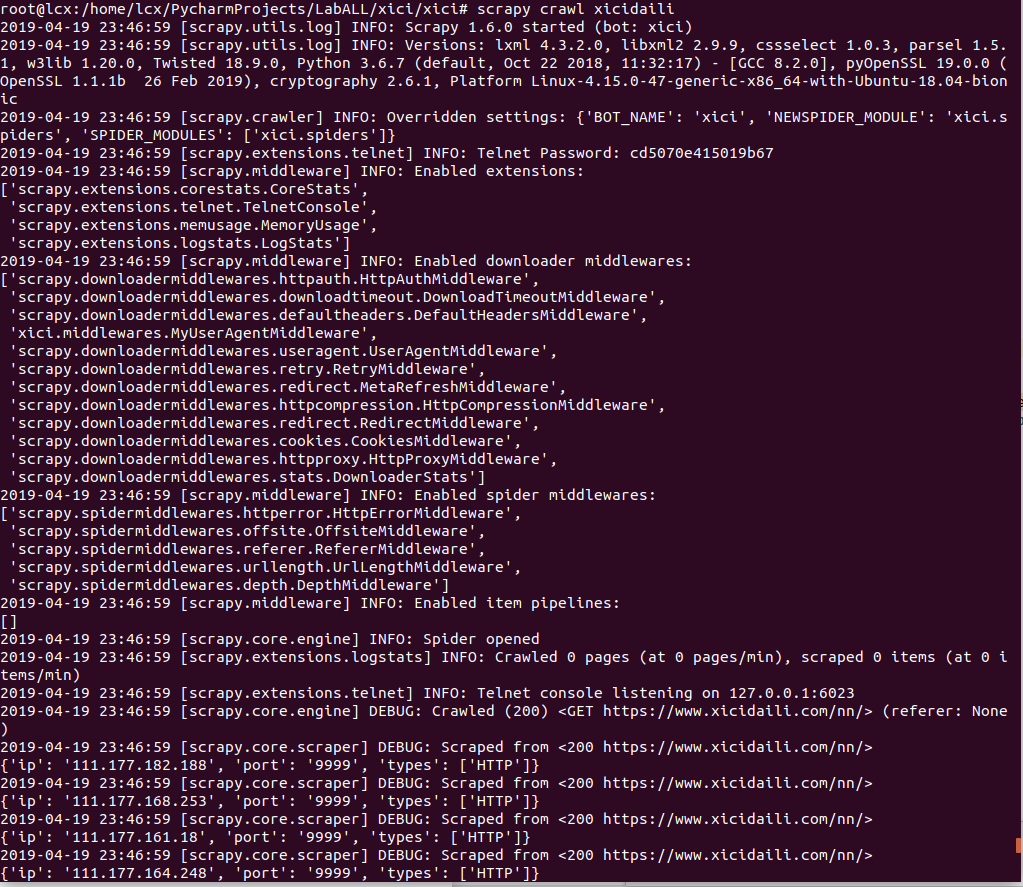
成功爬取
9.问题注意
1.在执行的时候,可能会卡住,原因是上面用的代理ip已经过期,需要另外找,
或者你可以把ip代理部分去掉,上面示例不用代理ip也能爬取,
找ip代理也是因为你频繁的访问,它是禁止了你的ip,没有也可以不用!
2.网站内的html标签有所改变,我上面xpath已经没办法找到我们想要的内容了,需要修改以下xpath
python+scrapy 爬取西刺代理ip(一)的更多相关文章
- python scrapy 爬取西刺代理ip(一基础篇)(ubuntu环境下) -赖大大
第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrapy框架 具体就自行百度了,主要内容不是在这. 第二步:创建scrapy(简单介绍) 1.Creating a p ...
- Scrapy爬取西刺代理ip流程
西刺代理爬虫 1. 新建项目和爬虫 scrapy startproject daili_ips ...... cd daili_ips/ #爬虫名称和domains scrapy genspider ...
- scrapy爬取西刺网站ip
# scrapy爬取西刺网站ip # -*- coding: utf-8 -*- import scrapy from xici.items import XiciItem class Xicispi ...
- Python四线程爬取西刺代理
import requests from bs4 import BeautifulSoup import lxml import telnetlib #验证代理的可用性 import pymysql. ...
- 使用XPath爬取西刺代理
因为在Scrapy的使用过程中,提取页面信息使用XPath比较方便,遂成此文. 在b站上看了介绍XPath的:https://www.bilibili.com/video/av30320885?fro ...
- 手把手教你使用Python爬取西刺代理数据(下篇)
/1 前言/ 前几天小编发布了手把手教你使用Python爬取西次代理数据(上篇),木有赶上车的小伙伴,可以戳进去看看.今天小编带大家进行网页结构的分析以及网页数据的提取,具体步骤如下. /2 首页分析 ...
- python3爬虫-通过requests爬取西刺代理
import requests from fake_useragent import UserAgent from lxml import etree from urllib.parse import ...
- python爬取高匿代理IP(再也不用担心会进小黑屋了)
为什么要用代理IP 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人 ...
- 爬取西刺ip代理池
好久没更新博客啦~,今天来更新一篇利用爬虫爬取西刺的代理池的小代码 先说下需求,我们都是用python写一段小代码去爬取自己所需要的信息,这是可取的,但是,有一些网站呢,对我们的网络爬虫做了一些限制, ...
随机推荐
- 乞丐版servlet容器第2篇
2. 监听端口接收请求 上一步中我们已经定义好了Server接口,并进行了多次重构,但是实际上那个Server是没啥毛用的东西. 现在要为其添加真正有用的功能. 大师说了,饭要一口一口吃,衣服要一件一 ...
- hdu-1060(数学问题)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1061 思路:结论:a=10^(N*lg(N) - [lg(N^N)]); 证明:如果一直a是结果,则a ...
- $clog2(转)
(转http://www.xilinx.com/support/answers/44586.html) 13.2 Verilog $clog2 function implemented imprope ...
- day3之函数的初始及进阶
函数初始 函数的定义与调用 ''' def 函数名 (参数): 函数体 函数名:设定与变量相同 执行函数: 函数名() ''' 函数的返回值 # 函数返回值 return ''' 1.遇到return ...
- AugularJS, Responsive, phonegap, BAE, SAE,GAE, Paas
http://freewind.me/blog/20121226/1167.html http://88250.b3log.org/bae-sae-gae http://www.ruanyifeng. ...
- MFC中不同对话框间使用SendMessage发送自定义消息的具体实现
1. 基本知识 SendMessage的基本结构如下: SendMessage( HWND hWnd, //消息传递的目标窗口或线程的句柄. UINT Msg, //消息类别(这里可 ...
- VCL消息处理机制
http://www.cnblogs.com/railgunman/archive/2010/12/10/1902524.html#2868236 说到VCL中的消息处理就不能不提到TApplicat ...
- Android App 退出整个应用
在做Android APP 过程中,有退出整个Project的功能,以下就是接受退出整个应用的操作: ActivityManager是用来管理记录每一个Activity,最后统一用来退出结束: pub ...
- Windows / Windows Phone 8.1 预留应用名称及应用上传
最近比较懒好久没有来这里跟大家聊了,WP 8.1 的 preview 发布已经有一阵子了,并且商店支持 8.1 应用也有一段时间了.我就把这篇 8.1 的应用商店预留提交作为 8.1 的一个开始吧. ...
- [Ubuntu]管理开机启动项的软件
sudo apt-get install sysv-rc-conf