mysql sql优化实例1(force index使用)
今天和运维同学一块查找mysql慢查询日志,发现了如下一条sql:
SELECT sum(`android` + ios) total,pictureid,title,add_time FROM `juzi_access_statistic` LEFT JOIN juzi_news ON juzi_access_statistic.pictureid=juzi_news.id GROUP BY `pictureid` HAVING total >= 100000 AND pictureid >= 8092 AND title IS NOT NULL LIMIT 2;
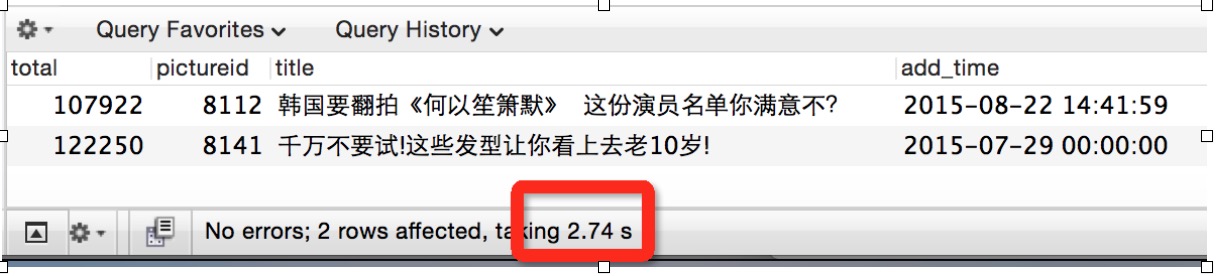
该sql语句花费了 2.7s,那么总共多少条呢?
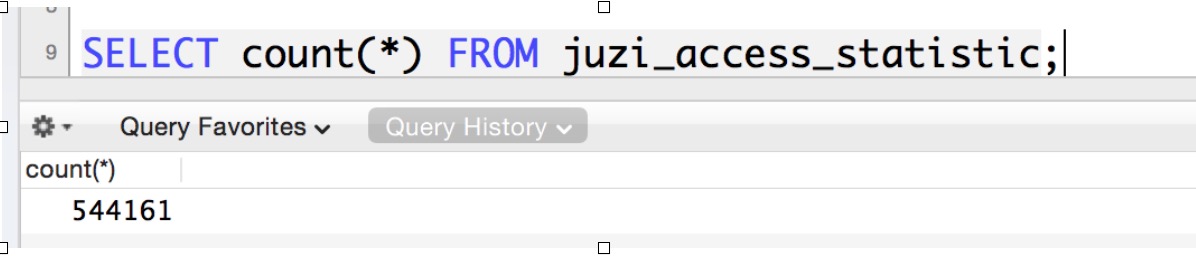
总共54万条记录,其实也不算太慢,但是我觉得应该有很大的优化空间。
一:先看一下表结构
CREATE TABLE `juzi_access_statistic` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`pictureid` int(11) NOT NULL DEFAULT '0' COMMENT '文章id',
`date` date NOT NULL COMMENT '日期',
`ios` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '苹果app访问量',
`android` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '安卓app访问量',
PRIMARY KEY (`id`),
UNIQUE KEY `pictureid` (`date`,`pictureid`) USING BTREE,
KEY `indexpictureid` (`pictureid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT=‘访问统计表’;
二: 查看一下执行计划

在这里我发现了问题:juzi_access_statistic表竟然是全表扫描,pictureid字段上存在索引,为什么没有使用上呢?
我个人觉得原因是:因为存在条件pictureid >= 8092 和 juzi_access_statistic.pictureid=juzi_news.id(等价传递),所以mysql觉得使用juzi_news表的主键id查询效率是最高的。
三:使用force index 优化

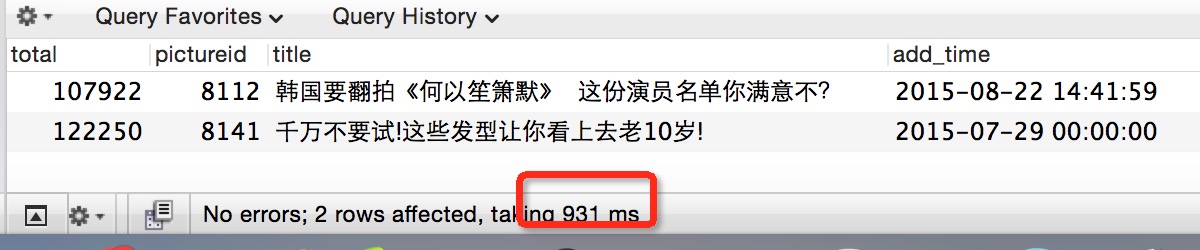
看到效果了吧:key字段显示使用到了pictureid字段的索引,但扫描的行没有减少,执行时间如下:
四:正确使用where
以上sql中的pictureid >= 8092 其实应该放到where子句中,以便过滤到更多的无用记录,修复后的执行计划如下:

效果也很明显:rows减少到不足10万,速度可想而知,见下图:
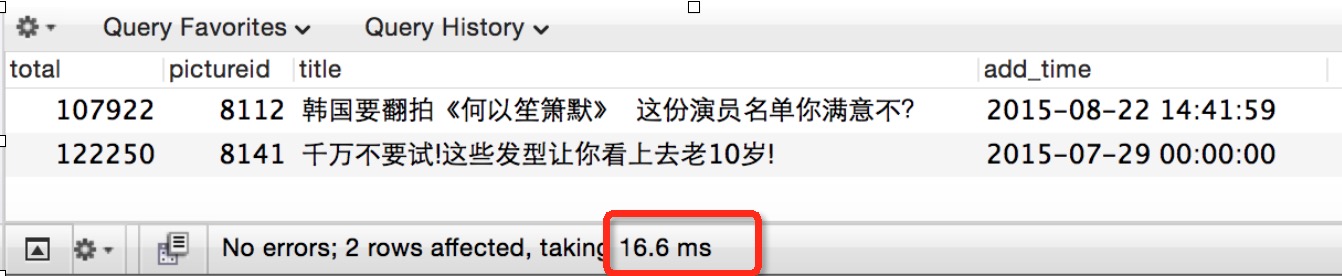
从开始的2.74s 优化到17ms, 优化了100倍
mysql sql优化实例1(force index使用)的更多相关文章
- mysql sql优化实例
mysql sql优化实例 优化前: pt-query-degist分析结果: # Query 3: 0.00 QPS, 0.00x concurrency, ID 0xDC6E62FA021C85B ...
- MySQL索引优化实例说明
下面分别创建三张表,并分别插入1W条简单的数据用来测试,详情如下: [1] test_a 有主键但无索引 CREATE TABLE `test_a` ( `id` int(10) unsign ...
- MySQL SQL优化之in与range查询【转】
本文来自:http://myrock.github.io/ 首先我们来说下in()这种方式的查询.在<高性能MySQL>里面提及用in这种方式可以有效的替代一定的range查询,提升查询效 ...
- 18.Mysql SQL优化
18.SQL优化18.1 优化SQL语句的一般步骤 18.1.1 通过show status命令了解各种SQL的执行频率show [session|global] status; -- 查看服务器状态 ...
- MySQL sql优化(摘抄自文档)
前言 有人反馈之前几篇文章过于理论缺少实际操作细节,这篇文章就多一些可操作性的内容吧. 注:这篇文章是以 MySQL 为背景,很多内容同时适用于其他关系型数据库,需要有一些索引知识为基础. 优化目标 ...
- Mysql SQL优化&执行计划
SQL优化准则 禁用select * 使用select count(*) 统计行数 尽量少运算 尽量避免全表扫描,如果可以,在过滤列建立索引 尽量避免在where子句对字段进行null判断 尽量避免在 ...
- mysql sql优化及注意事项
sql优化分析 通过slow_log等方式可以捕获慢查询sql,然后就是减少其对io和cpu的使用(不合理的索引.不必要的数据访问和排序)当我们面对具体的sql时,首先查看其执行计划A.看其是否使用索 ...
- MySQL SQL优化教程
转自:https://www.cnblogs.com/duanxz/archive/2013/02/01/2889413.html 一,查询SQL执行效率 通过show status命令了解各种SQL ...
- MySQL SQL优化
一.优化数据库的一般步骤: (A) 通过 show status 命令了解各种SQL的执行频率. (B) 定位执行效率较低的SQL语句,方法两种: 事后查询定位:慢查询日志:--log-slow-qu ...
随机推荐
- 初期测评 E 迷障
https://vjudge.net/contest/240302#problem/E 通过悬崖的yifenfei,又面临着幽谷的考验—— 幽谷周围瘴气弥漫,静的可怕,隐约可见地上堆满了骷髅.由于此处 ...
- call()方法和apply()方法
最近又遇到了JacvaScript中的call()方法和apply()方法,而在某些时候这两个方法还确实是十分重要的,那么就让我总结这两个方法的使用和区别吧. 1. 每个函数都包含两个非继承而来的方法 ...
- node 加密音频文件 和 解密音频文件
fs.readFile('./downsuccess/'+name+'', {flag: 'r+', encoding: ''}, function (err, data) { c ...
- 2013成都网赛1010 hdu 4737 A Bit Fun
题意:定义f(i, j) = ai|ai+1|ai+2| ... | aj (| 指或运算),求有多少对f(i,j)<m.1 <= n <= 100000, 1 <= m &l ...
- iOS BCD码、数据流、字节和MD5计算
一.各个之间的相互转换 1.字符串转数据流NSData NSString *str = @"abc123"; NSData *dd = [str dataUsingEncoding ...
- zabbix自定义监控阿里云RDS服务
zabbix自定义监控rds zabbix通过阿里云api 自动发现.监控阿里云RDS-Mysql数据库 注意事项 脚本会收集RDS别名, 不要默认别名 不要使用中文别名(zabbix不识别) ...
- BZOJ5254 FJWC2018红绿灯(线段树)
注意到一旦在某个路口被红灯逼停,剩下要走的时间是固定的.容易想到预处理出在每个路口被逼停后到达终点的最短时间,这样对于每个询问求出其最早在哪个路口停下就可以了.对于预处理,从下一个要停的路口倒推即可. ...
- Windows下python 3.0版本django的安装、配置、与启动
使用的环境是Windows操作系统,python的环境是3.6,django是官网上最新的版本1.10.6,本文介绍从安装python之后怎样用过pip管理工具安装django,以及django的项目 ...
- 一文看尽HashMap
前言 日常开发中,经常会使用到JDK自带的集合类:List.Set.Map三者的实现,ArrayList.LinkedList.HashSet.TreeSet.HashMap.TreeMap等.其中L ...
- BZOJ 4520: [Cqoi2016]K远点对
4520: [Cqoi2016]K远点对 Time Limit: 30 Sec Memory Limit: 512 MBSubmit: 638 Solved: 340[Submit][Status ...